点击上方“小麦大叔”,选择“置顶/星标公众号”

摘要:一直觉得C语言较其他语言最伟大的地方就是C语言中的指针,有些人认为指针很简单,而有些人认为指针很难,当然这里的对简单和难并不是等价于对指针的理解程度。为此作者在这里对C语言中的指针进行全面的总结,从底层的内存分析,彻底让读者明白指针的本质。
小编认为C指针应该和C语言中的变量放在一起,因为C指针本质上还是一个变量,但现在大部分教材将其单独拿出来讲解,这也使得很多初学者认为指针是一个和变量毫无相关的概念。
首先读者要明白指针是一个变量,为此作者写了如下代码来验证之:
#include "stdio.h"
int main(int argc, char **argv)
{
unsigned int a = 10;
unsigned int *p = NULL;
p = &a;
printf("&a=%d\n",a);
printf("&a=%d\n",&a);
*p = 20;
printf("a=%d\n",a);
return 0;
}
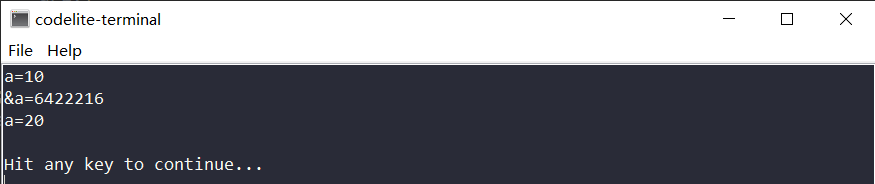
运行后可以看到a的值被更改了,上面的例子可以清楚的明白指针实质上是一个放置变量地址的特殊变量,其本质仍然是变量。
既然指针是变量,那必然会有变量类型,因此这里必须对变量类型做解释。在C语言中,所有的变量都有变量类型,整型、浮现型、字符型、指针类型、结构体、联合体、枚举等,这些都是变量类型。变量类型的出现是内存管理的必然结果,相信读者知道,所有的变量都是保存在计算机的内存中,既然是放到计算机的内存中,那必然会占用一定的空间,问题来了,一个变量会占用多少空间呢,或者说应该分出多少内存空间来放置该变量呢?为了规定这个,类型由此诞生了,对于32位编译器来说,int类型占用4个字节,即32位,long类型占用8字节,即64位。这里简单说了类型主要是为后面引出指针这个特殊性,在计算机中,将要运行的程序都保存在内存中,所有的程序中的变量其实就是对内存的操作。计算机的内存结构较为简单,这里不详细谈论内存的物理结构,只谈论内存模型。将计算机的内存可以想象为一个房子,房子里面居住着人,每一个房间对应着计算机的内存地址,内存中的数据就相当于房子里的人。

既然指针也是一个变量,那个指针也应该被存放在内存中,对于32位编译器来说,其寻址空间为2^32=4GB,为了能够都操作所有内存(实际上普通用户不可能操作所有内存),指针变量存放也要用32位数即4个字节。这样就有指针的地址&p,指针和变量的关系可以用如下图表示:
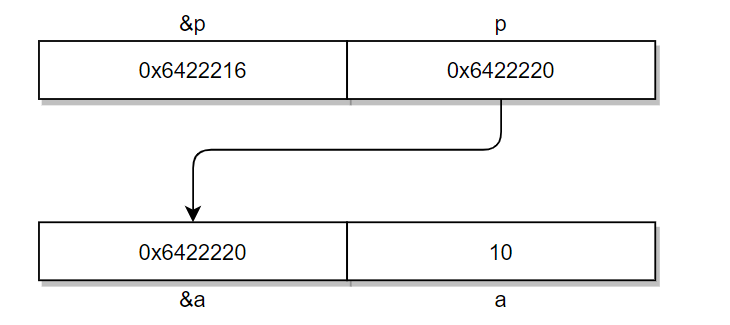
从上图可以看到&p是指针的地址,用来存放指针p,而指针p来存放变量a的地址,也就是&a,还有一个*p在C语言中是解引,意思是告诉编译器取出该地址存放的内容。

上面提到过关于指针类型的问题,针对32位编译器而言,既然任何指针都只占用4个字节,那为何还需要引入指针类型呢?仅仅是为了约束相同类型的变量么?实际上这里不得不提到指针操作,先思考如下两个操作:
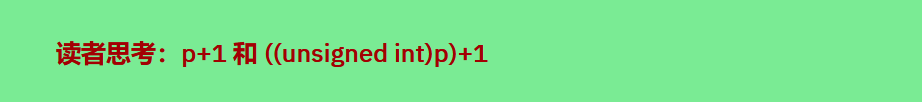
上面两个操作的意思是不同的,先说下第一种:p+1操作,如下图所示:
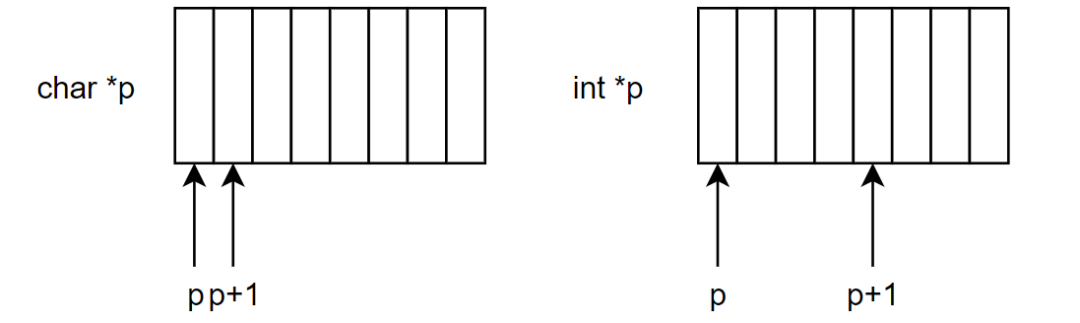
对于不同类型指针而言,其p+1所指向的地址不同,这个递增取决于指针类型所占的内存大小,而对于((unsigned int)p)+1,该意思是将地址p所指向的地址的值直接转换为数字,然后+1,这样无论p是何种类型的指针,其结果都是指针所指的地址后一个地址。
从上述可以看到,指针的存在使得程序员可以相当轻松的操作内存,这也使得当前有些人认为指针相当危险,这一观点表现在C#和Java语言中,然而实际上用好指针可以极大的提高效率。下面深入一点来通过指针对内存进行操作,现在我们需要对内存6422216中填入一个数据125,我们可以如下操作:
unsigned int *p=(unsigned int*)(6422216);
*p=125;
当然,上面的代码使用了一个指针,实际上C语言中可以直接利用解引操作对内存进行更方便的赋值,下面说下解引操作*。
所谓解引操作,实际上是对一个地址操作,比如现在想将变量a进行赋值,一般操作是a=125,现在我们用解引操作来完成,操作如下:
*(&a)=125;
上面可以看到解引操作符为*,这个操作符对于指针有两个不同的意义,当在申明的时候是申明一个指针,而当在使用p指针时是解引操作,解引操作右边是一个地址,这样解引操作的意思就是该地址内存中的数据。这样我们对内存6422216中填入一个数据125就可以使用如下操作:
*(unsigned int*)(6422216)=125;
上面需要将6422216数值强制转换为一个地址,这个是告诉编译器该数值是一个地址。值得注意的是上面的所有内存地址不能随便指定,必须是计算机已经分配的内存,否则计算机会认为指针越界而被操作系统杀死即程序提前终止。
结构体指针和普通变量指针一样,结构体指针只占4个字节(32位编译器),只不过结构体指针可以很容易的访问结构体类型中的任何成员,这就是指针的成员运算符->。
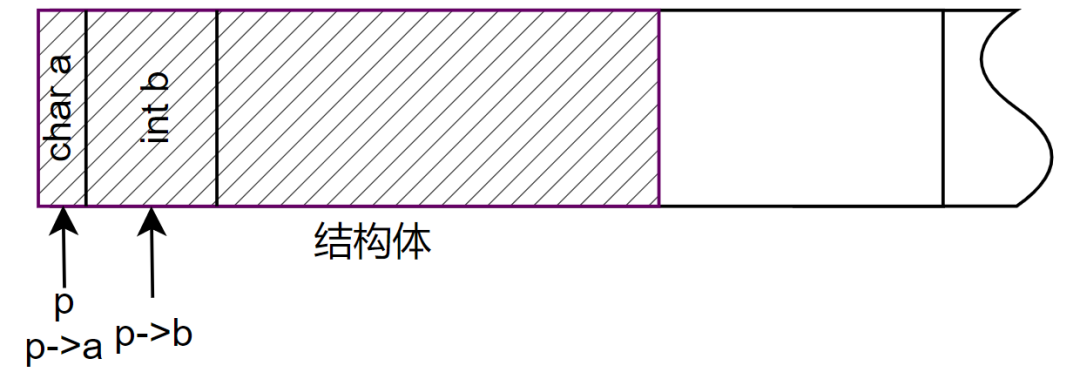
上图中p是一个结构体指针,p指向的是一个结构体的首地址,而p->a可以用来访问结构体中的成员a,当然p->a和*(p)是相同的。
为何要在这里提强制类型转换呢,上面的测试代码可以看到编译器会报很多警告,意思是告诉程序员数据类型不匹配,虽然并不影响程序的正确运行,但是很多警告总会让人感到难受。因此为了告诉编译器代码这里没有问题,程序员可以使用强制类型转换来将一段内存转换为需要的数据类型,例如下面有一个数组a,现在将其强制转换为一个结构体类型stu:
#include
typedef struct STUDENT
{
int name;
int gender;
}stu;
int a[100]={10,20,30,40,50};
int main(int argc, char **argv)
{
stu *student;
student=(stu*)a;
printf("student->name=%d\n",student->name);
printf("student->gender=%d\n",student->gender);
return 0;
}
上面的程序运行结果如下:

可以看到a[100]被强制转换为stu结构体类型,当然不使用强制类型转换也是可以的,只是编译器会报警报。
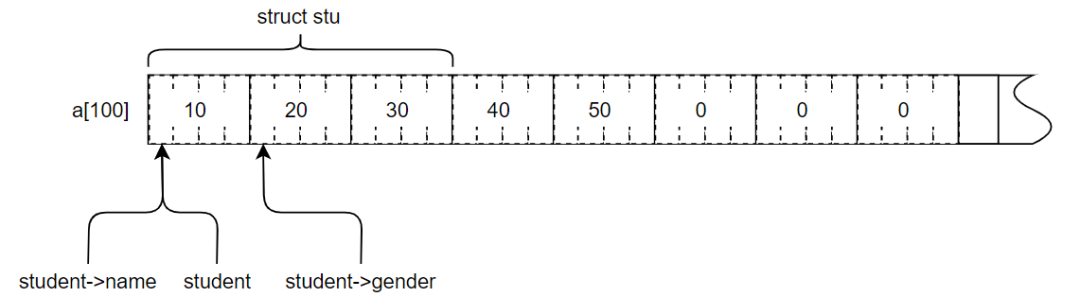
上图为程序的示意图,图中数组a[100]的前12个字节被强制转换为了一个struct stu类型,上面仅对数组进行了说明,其它数据类型也是一样的,本质上都是一段内存空间。
为何在这里单独提到空指针类型呢?,主要是因为该指针类型很特殊。void类型很容易让人想到是空的意思,但对于指针而言,其并不是指空,而是指不确定。在很多时候指针在申明的时候可能并不知道是什么类型或者该指针指向的数据类型有多种再或者程序员仅仅是想通过一个指针来操作一段内存空间。这个时候可以将指针申明为void类型。但是问题来了,由于void类型原因,对于确定的数据类型解引时,编译器会根据类型所占的空间来解引相应的数据,例如int p,那么p就会被编译器解引为p指针的地址的4个字节的空间大小。但对于空指针类型来说,编译器如何知道其要解引的内存大小呢?先看一段代码:
#include
int main(int argc, char **argv)
{
int a=10;
void *p;
p=&a;
printf("p=%d\n",*p);
return 0;
}
编译上面的程序会发现,编译器报错,无法正常编译。

这说明编译器确实是在解引时无法确定*p的大小,因此这里必须告诉编译器p的类型或者*p的大小,如何告诉呢?很简单,用强制类型转换即可,如下:
*(int*)p
这样上面的程序就可以写为如下:
#include
int main(int argc, char **argv)
{
int a=10;
void *p;
p=&a;
printf("p=%d\n",*(int*)p);
return 0;
}
编译运行后:

可以看到结果确实是正确的,也和预期的想法一致。由于void指针没有空间大小属性,因此void指针也没有++操作。

函数指针在Linux内核中用的非常多,而且在设计操作系统的时候也会用到,因此这里将详细讲解函数指针。既然函数指针也是指针,那函数指针也占用4个字节(32位编译器)。下面以一个简单的例子说明:
#include
int add(int a,int b)
{
return a+b;
}
int main(int argc, char **argv)
{
int (*p)(int,int);
p=add;
printf("add(10,20)=%d\n",(*p)(10,20));
return 0;
}
程序运行结果如下:

可以看到,函数指针的申明为:

函数指针的解引操作与普通的指针有点不一样,对于普通的指针而言,解引只需要根据类型来取出数据即可,但函数指针是要调用一个函数,其解引不可能是将数据取出,实际上函数指针的解引本质上是执行函数的过程,只是这个执行函数是使用的call指令并不是之前的函数,而是函数指针的值,即函数的地址。其实执行函数的过程本质上也是利用call指令来调用函数的地址,因此函数指针本质上就是保存函数执行过程的首地址。函数指针的调用如下:

为了确认函数指针本质上是传递给call指令一个函数的地址,下面用一个简单例子说明:
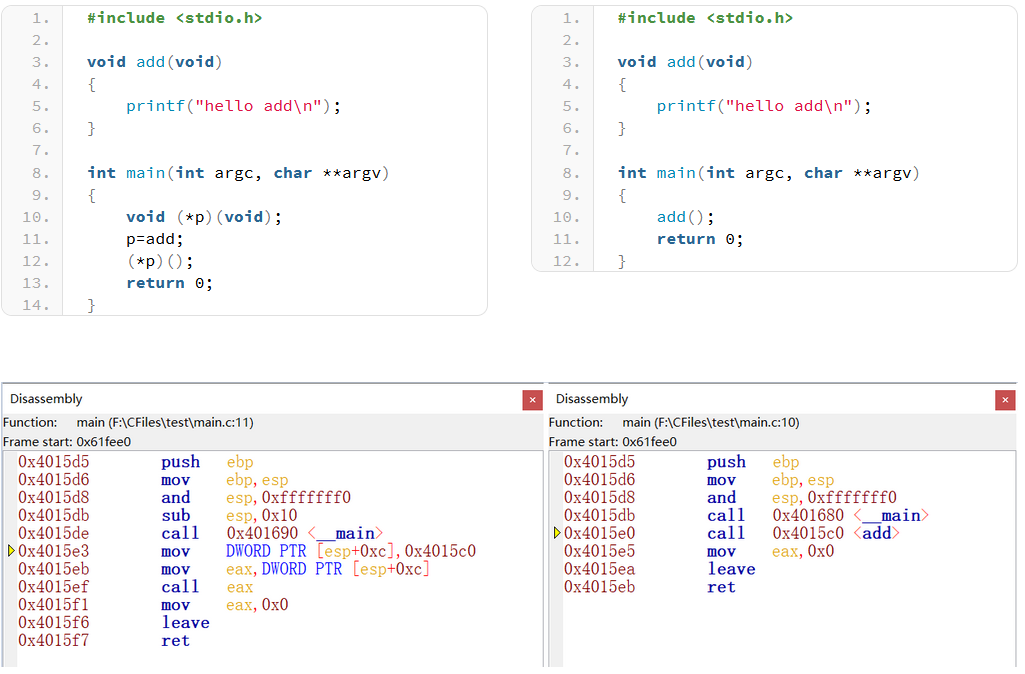
上面是编译后的汇编指令,可以看到,使用函数指针来调用函数时,其汇编指令多了如下:
0x4015e3 mov DWORD PTR [esp+0xc],0x4015c0
0x4015eb mov eax,DWORD PTR [esp+0xc]
0x4015ef call eax
分析:第一行mov指令将立即数0x4015c0赋值给寄存器esp+0xc的地址内存中,然后将寄存器esp+0xc地址的值赋值给寄存器eax(累加器),然后调用call指令,此时pc指针将会指向add函数,而0x4015c0正好是函数add的首地址,这样就完成了函数的调用。细心的读者是否发现一个有趣的现象,上述过程中函数指针的值和参数一样是被放在栈帧中,这样看起来就是一个参数传递的过程,因此可以看到,函数指针最终还是以参数传递的形式传递给被调用的函数,而这个传递的值正好是函数的首地址。
从上面可以看到函数指针并不是和一般的指针一样可以操作内存,因此作者觉得函数指针可以看作是函数的引用申明。
在linux驱动面向对象编程思想中用的最多,利用函数指针来实现封装,下面以一个简单的例子说明:
#include
typedef struct TFT_DISPLAY
{
int pix_width;
int pix_height;
int color_width;
void (*init)(void);
void (*fill_screen)(int color);
void (*tft_test)(void);
}tft_display;
static void init(void)
{
printf("the display is initialed\n");
}
static void fill_screen(int color)
{
printf("the display screen set 0x%x\n",color);
}
tft_display mydisplay=
{
.pix_width=320,
.pix_height=240,
.color_width=24,
.init=init,
.fill_screen=fill_screen,
};
int main(int argc, char **argv)
{
mydisplay.init();
mydisplay.fill_screen(0xfff);
return 0;
}
上面的例子将一个tft_display封装成一个对象,上面的结构体成员中最后一个没有初始化,这在Linux中用的非常多,最常见的是file_operations结构体,该结构体一般来说只需要初始化常见的函数,不需要全部初始化。上面代码中采用的结构体初始化方式也是在Linux中最常用的一种方式,这种方式的好处在于无需按照结构体的顺序一对一。
有时候会遇到这样一种情况,当上层人员将一个功能交给下层程序员完成时,上层程序员和下层程序员同步工作,这个时候该功能函数并未完成,这个时候上层程序员可以定义一个API来交给下层程序员,而上层程序员只要关心该API就可以了而无需关心具体实现,具体实现交给下层程序员完成即可(这里的上层和下层程序员不指等级关系,而是项目的分工关系)。这种情况下就会用到回调函数(Callback Function),现在假设程序员A需要一个FFT算法,这个时候程序员A将FFT算法交给程序员B来完成,现在来让实现这个过程:
#include
int InputData[100]={0};
int OutputData[100]={0};
void FFT_Function(int *inputData,int *outputData,int num)
{
while(num--)
{
}
}
void TaskA_CallBack(void (*fft)(int*,int*,int))
{
(*fft)(InputData,OutputData,100);
}
int main(int argc, char **argv)
{
TaskA_CallBack(FFT_Function);
return 0;
}
上面的代码中TaskA_CallBack是回调函数,该函数的形参为一个函数指针,而FFT_Function是一个被调用函数。可以看到回调函数中申明的函数指针必须和被调用函数的类型完全相同。
往期推荐

长按识别二维码关注我