随着高层次综合工具的代代提升,RTL设计经验的设计者可以精准控制AXI 总线的突发读写,在Vitis HLS 工具中也可以逐步实现了。当一个C++加速函数的端口被指定为M_AXI时,HLS工具会生成一个AXI 总线适配器,精确地控制读写的。本文给大家分享系统级别的一些宏观概念以及如何预估 HLS 内核向 DDR 发送突发读写在各个步骤中的延迟。
突发读写系统级别的宏观概念介绍
Bursting Optimization 是一种基于AXI总线的突发读写效率优化,它可以尝试智能地将我们对 DDR 的内存访问的请求聚集起来,以最大化提升吞吐量带宽或者最小化延迟。 Bursting 通常对吞吐量可以提供 4-5 倍的改进空间,而其他优化(比如扩展访问端口或 确保DDR数据读写没有依赖性)可以提供更大的性能改进。通常,在有多个内内核在对DDR 数据的读取有竞争关系并发生争用时,突发读写就有更大的优势。
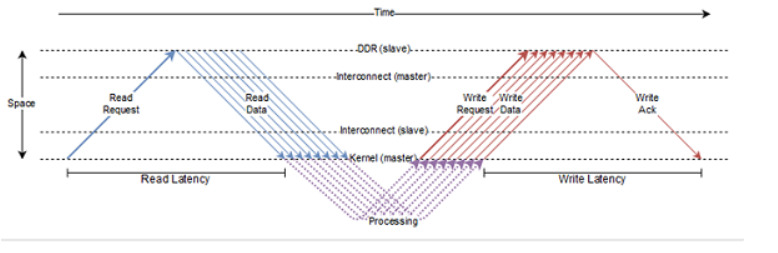
上图显示了 AXI 协议处理brust length 为8时,AXI总线数据传输的工作原理。读延迟(Read Latency)定义为从发送读请求突发到第一次读突发中的请求被内核接收。类似地,写延迟(Write Latency)被定义为写突发中最后一次写的数据被发送到内核收到写确认之间所花费的时间。读取请求通常在第一个可用机会时发送,而写入请求则排队等待,直到突发中每个写入的数据可用。
为了帮助我们了解系统中可能存在的各种延迟,下图显示了当 HLS 内核向 DDR 发送突发读写时会发生什么。
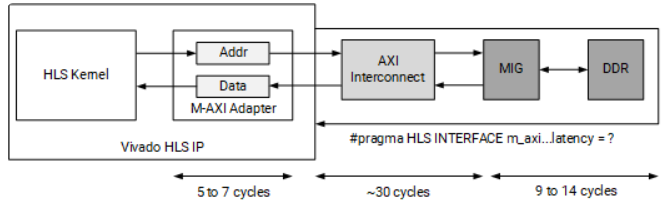
当我们的设计发出读/写请求时,该请求将通过几个专门的辅助模块发送到 DDR。首先,M-AXI 适配器(Adapter)时在 HLS 内核创建的请求的缓冲区。内核中的适配器主要有两大功能:
1、将大脉冲串切割成较小脉冲串的逻辑(它需要这样做以防止占用通道或如果请求跨越 4 KB 边界,请参阅 AXI 参考指南 (UG1037))。
2、停止发送突发请求(取决于最大未完成outstanding请求参数),以便它可以安全地缓冲每个内核的全部数据。这可能会略微增加写入延迟,但可以解决由于内存子系统上的并发请求(读取或写入)而导致的deadlock。我们可以通过配置config_interface -m_axi_conservative_mode 参数使得 M-AXI 接口先hold所有写入请求,直到所有数据都可用。
通过M-AXI 适配器将花费几个周期的延迟,通常情况为 5 到 7 个周期。然后,请求进入 AXI 互连,该互连将内核的请求发到 MIG,然后最终给到 DDR。通过互连的延迟成本很高,可能需要大约 30 个周期。最后,往返 DDR 可能需要 9 到 14 个周期的成本。以上数据不是对延迟的精确测量,而是用于显示这些专用模块的相对延迟成本的估计值。要进行更精确的测量,我们需要编写特定系统的应用程序,生成时间线报告(timeline report)来测试和观察这些延迟。
从II的角度估算系统延迟的方法如下:在HLS内核端的数据处理II=1的前提下,互连的平均 II 为 2,而 DDR 控制器的平均 II 为 4-5 个请求周期。
另外需要提醒大家的是:AXI互连仲裁的策略基于读/写请求的长度大小,因此请求具有较长突发长度的数据优先于具有较短突发的请求(从而导致更大的信道带宽被分配给较长的突发,以防发生争用)。当然,较长的突发请求具有阻止其他任何人访问 DDR 的副作用,所以我们在做系统级别的规划的时候,必须在突发长度和减少 DDR 端口争用之间进行取舍。幸运的是,较大的延迟有助于防止某些端口争用,并且请求的有效流水线可以显着提高系统中可用的带宽吞吐量。
下一篇文章将从理论层面分析HLS编译器如何寻找理解突发访问出发,如何区分区域突发和循环突发两种概念,并分析了哪些错误的代码风格会阻止突发推理。




