

大家好,我是老吴。
今天是周一,大家工作顺利吗?
这篇文章给大家分享一点小知识:为什么中断里不能睡眠?
网上很多文章尝试解释这个问题,看后我觉得头皮发麻。
下面,我试着总结一下原因。
首先,让我们明确一下问题。
对于这个问题,稍微准确一点的问法是:为什么在 Linux 的中断里,不能 sleep?
但是这个问法仍然不准确。
中断 (interrupt) 和中断服务程序 (interrupt service routine, ISR,或者是 interrupt handler),是 2 个不同的概念。
前者是硬件相关的概念,后者是软件相关的概念。
所以,对于这个问题,最准确的问法是:为什么在 Linux 的 ISR 里,不能 sleep?
由于 sleep 意味着 call scheduler,所以更直白一点的问法是:
为什么在 Linux 的 ISR 里,不能 call scheduler?
最后,再加点限制条件会更准确:为什么在 Linux 的 ISR 里,即便 ISR 没有 hold 住任何 lock 的时候,都不能 call scheduler?
不能在 ISR 里睡眠的原因是:ISR 与任何 process context (进程上下文) 无关。
process context 是进程的状态信息,包括:
对于每一个进程,在内核都会有一个 pcb (process control, block,即 Linux 里的 task_struct 结构体) 来管理这些信息。
scheduler 可以访问所有这些信息,以抢占一个进程并运行另一个进程。
与此相反,取决于内核和迎接架构的版本,ISR 使用单独的中断栈或被中断的进程的内核栈,并且在中断中会有自己的 hardware context.
因此,由于在 ISR 里没有 process context,所以不能进行调度。
但是,这个说法描述的其实是当下设计的状况,而不是当初这样设计的原因。
在 Linux 的早期版本中,ISR 总是借用当前进程的栈。
所以如果内核想设计成允许在 ISR 里睡眠,是可以很自然地实现进程上下文切换的。
但是,Linux 采用的设计是:在 ISR 里禁止睡眠。
现在,我们的问题变成了:
为什么在 Linux 里,ISR 被设计成不能睡眠?
sleep 会导致 call scheduler 以选择另一个进程来运行。
内核代码里有大量的 critical section (临界区)。
critical section 本质上是一段会访问或操作共享资源的代码,例如:
static int copy_fs(unsigned long clone_flags, struct task_struct *tsk)
{
struct fs_struct *fs = current->fs;
if (clone_flags & CLONE_FS) {
/* tsk->fs is already what we want */
spin_lock(&fs->lock);
if (fs->in_exec) {
spin_unlock(&fs->lock);
return -EAGAIN;
}
fs->users++;
spin_unlock(&fs->lock);
return 0;
}
tsk->fs = copy_fs_struct(fs);
if (!tsk->fs)
return -ENOMEM;
return 0;
}
在 critical section 里,是不能 call scheduler 的。
因为已经有一个进程持有锁了,如果这时切换到另一个进程,最好的情况下是等待一段无法预测的时间后前一个进程会将锁释放出来,最坏的情况是死锁。
硬件中断是随时可能发生的,即便内核执行的路径正处于 critical section 中。
如果想在 ISR 里支持 sleep,也就是支持 call scheduler 的话,那么所有的 critical section 都必须得禁用中断,否则硬件中断一旦来临系统就会出现 race condition,接下来大概率是死锁。
Sleep 和 ISR:
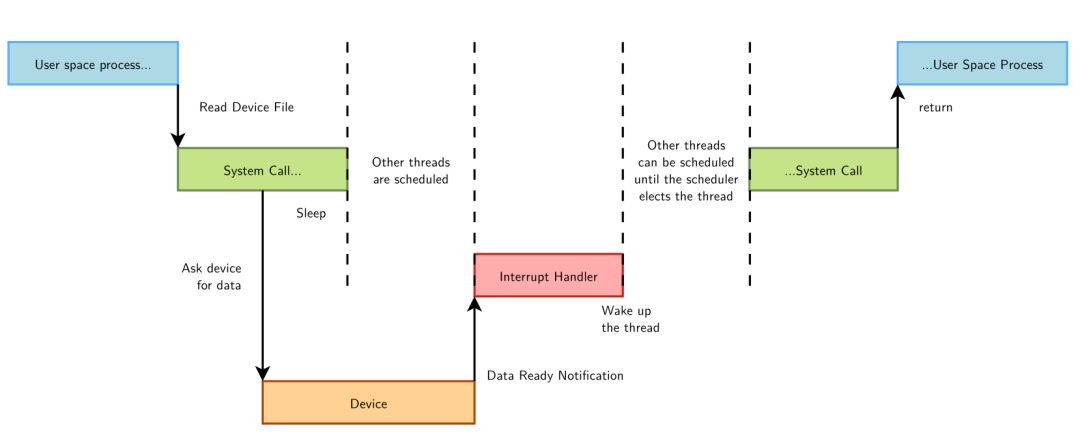
我查阅了一下 Linux 4.9 的代码,当你在一个不能调度的地方 call scheduler (例如 ISR 里 sleep) 的话,内核可以提示你写的代码有 BUG:
static inline void schedule_debug(struct task_struct *prev)
{
#ifdef CONFIG_SCHED_STACK_END_CHECK
if (task_stack_end_corrupted(prev))
panic("corrupted stack end detected inside scheduler\n");
#endif
// 错误的时机 call sheduler ?
if (unlikely(in_atomic_preempt_off())) {
__schedule_bug(prev);
preempt_count_set(PREEMPT_DISABLED);
}
[...]
}
我在某个设备驱动的中断处理函数 XXX_ISR() 里加了 msleep(10) 之后:
[ 27.221560] BUG: scheduling while atomic: swapper/0/0x00010002
[ 27.221609] Modules linked in: 8021q garp stp mrp llc usb_f_eem g_ether usb_f_rndis u_ether exfat(O)
[ 27.221712] CPU: 0 PID: 0 Comm: swapper Tainted: G O 4.9.203 #640
[ 27.224736] Hardware name: Samsung Device
[ 27.230575] [] (unwind_backtrace) from [] (show_stack+0x10/0x14)
[ 27.238267] [] (show_stack) from [] (__schedule_bug+0x64/0x84)
[ 27.245802] [] (__schedule_bug) from [] (__schedule+0x3fc/0x550)
[ 27.253512] [] (__schedule) from [] (schedule+0x50/0xb4)
[ 27.260533] [] (schedule) from [] (schedule_timeout+0x114/0x1e8)
[ 27.268246] [] (schedule_timeout) from [] (msleep+0x2c/0x38)
[ 27.275612] [] (msleep) from [] (XXX_ISR+0x34/0x8c)
[ 27.282982] [] (XXX_ISR) from [] (__handle_irq_event_percpu+0x88/0x124)
[ 27.292075] [] (__handle_irq_event_percpu) from [] (handle_irq_event_percpu+0x1c/0x58)
[ 27.301693] [] (handle_irq_event_percpu) from [] (handle_irq_event+0x38/0x5c)
[ 27.310532] [] (handle_irq_event) from [] (handle_edge_irq+0xe0/0x1a4)
[ 27.318764] [] (handle_edge_irq) from [] (generic_handle_irq+0x24/0x34)
[ 27.327091] [] (generic_handle_irq) from [] (exynos_irq_eint0_15+0x44/0x98)
[ 27.335751] [] (exynos_irq_eint0_15) from [] (generic_handle_irq+0x24/0x34)
[ 27.344415] [] (generic_handle_irq) from [] (__handle_domain_irq+0x54/0xa8)
[ 27.353080] [] (__handle_domain_irq) from [] (vic_handle_irq+0x58/0x94)
[ 27.361398] [] (vic_handle_irq) from [] (__irq_svc+0x6c/0xa8)
[ 27.368847] Exception stack(0xc0d01f58 to 0xc0d01fa0)
总结一下:
硬件中断是超级宝贵的资源,想在中断里睡眠的话就得在大量的 critical section 中关闭中断才能避免 race condition,而关闭硬件中断将会大大地增加中断响应的延迟,降低系统的反应速度,这是操作系统的用户所无法接受的, 因此内核开发者采用的设计是在中断里不允许睡眠,并且 ISR 应尽快执行并返回以便系统里的进程继续运行。
那么,那些很耗时的工作该怎么处理呢?
由于硬件中断可能随时发生,ISR 随时会执行。因此,它必须快速运行并退出,以便尽快恢复被中断代码的执行。在操作系统看来,无论是硬件中断还是被中断的代码,两者都是很重要的,因此,ISR 应在尽可能短的时间内执行完毕。
但是,现实情况是,许多 ISR 有大量工作要执行。例如网络设备的 ISR 除了响应硬件之外,还需要 将网络数据包从硬件复制到内存中,处理它们,并将数据包向下分发到适当的协议栈或应用程序。
Linux 如何解决这种活多钱少的问题?
答:将 ISR 分为 top half 和 bottom half。
top half 在收到中断后立即运行,仅执行时间紧迫的工作,例如确认收到中断或重置硬件,执行完 top half 后,如果进入 ISR 前是处于 critical section 且内核抢占是被关闭 ( 例如 spinlock ) 的话,就会返回到 critical section 里继续运行,不会产生 race condition 的问题。
void irq_exit(void)
{
#ifndef __ARCH_IRQ_EXIT_IRQS_DISABLED
local_irq_disable();
#else
WARN_ON_ONCE(!irqs_disabled());
#endif
account_irq_exit_time(current);
preempt_count_sub(HARDIRQ_OFFSET);
// 内核抢占没被关闭、已经没有其他 hardirq 了、有 softirq 在 pending 等条件都被满足时,才会处理 softirq
if (!in_interrupt() && local_softirq_pending())
invoke_softirq();
[...]
}
而晚一点执行也没问题的工作将推迟到 bottom half。bottom half 将在某个未来更方便的时间运行,并且是在使能所有中断、使能内核抢占的情况下进行,那时我们想怎么折腾就怎么折腾吧。
Linux 提供了许多 bottom half 的机制,例如 softirqs、tasklets、workqueues。
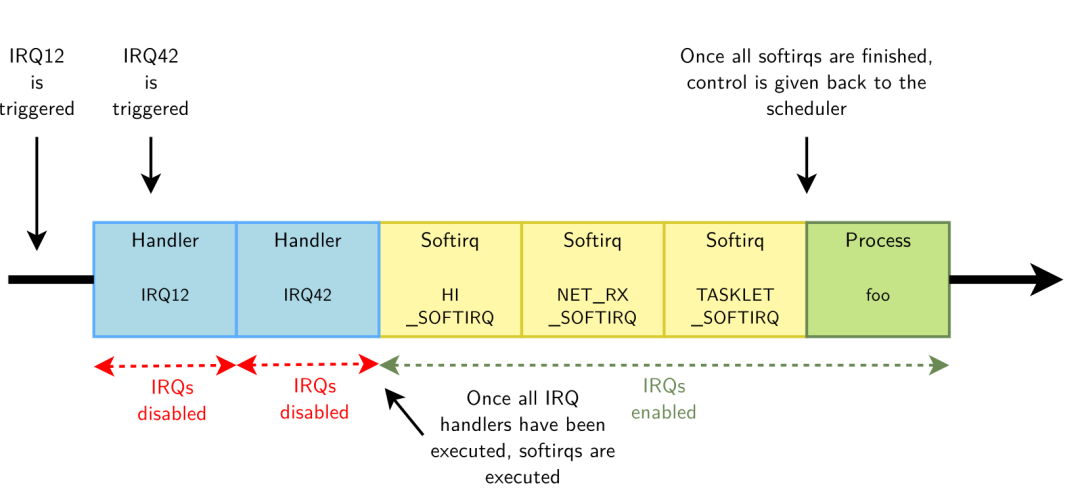
所以,有了 bottom half 之后,在 ISR 里睡眠这种需求,其实是完全没有必要的。
到此,这个问题就解释完毕了,感谢大家的阅读。

欢迎转发、留言、点赞、分享给您的朋友,感谢您的支持!
