卷积神经网络(CNN)已被证明对复杂的图像识别问题非常有效。本白皮书讨论了如何使用BittWare公司的FPGA加速器产品对这些网络进行加速,使用英特尔OpenCL软件开发工具包进行编程。然后,本文介绍了如何通过降低计算精度来显著提高图像分类的性能。每降低一次精度,FPGA加速器就可以每秒处理越来越多的图像。
Caffe是一个以表达、速度和模块化为宗旨的深度学习框架。它是由伯克利视觉和学习中心以及社区贡献者开发的。
Caffe框架使用一个XML接口来描述特定CNN所需的不同处理层。通过实现不同的层的组合,用户能够根据他们的要求快速创建一个新的网络拓扑结构。
这些层中最常用的是。
卷积。卷积层用一组可学习的过滤器对输入图像进行卷积,每个过滤器在输出图像中产生一个特征图。
池化。Max-pooling将输入图像划分为一组不重叠的矩形,对于每个子区域,输出最大值。
Rectified-Linear: Given an input value x, The ReLU layer computes the output as x if x > 0 and negative_slope * x if x <= 0.
InnerProduct/Fully Connected。图像被视为单一的矢量,每个点都对新的输出矢量的每个点有贡献。
通过将这4层移植到FPGA上,绝大多数的前向处理网络都可以使用Caffe框架在FPGA上实现。
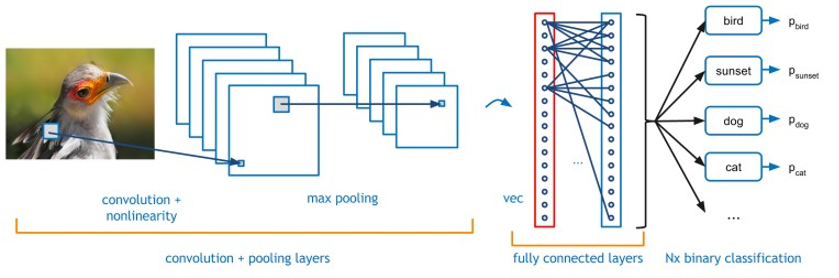
图1:典型的CNN-卷积神经网络的实例说明
AlexNet是一个众所周知且使用广泛的网络,有免费的训练数据集和基准。本文讨论了针对AlexNet CNN的FPGA实现,然而这里使用的方法也同样适用于其他网络。
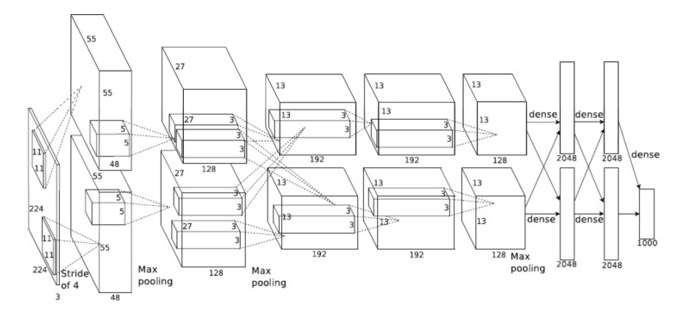
图2:AlexNet CNN - 卷积神经网络
图2说明了AlexNet CNN所需的不同网络层。其中有5个卷积层和3个全连接层。这些层占据了该网络99%以上的处理时间。不同的卷积层有3种不同的过滤器尺寸:11×11、5×5和3×3。为不同的卷积层创建不同的优化层将是低效的。这是因为每个层的计算时间取决于应用的过滤器的数量和输入图像的大小。由于处理的输入和输出特征的数量不同,每个层的计算时间也不同。然而,每个卷积需要不同数量的层和不同数量的像素来处理。通过增加应用于更多计算密集层的资源,可以平衡每一层在相同时间内完成。因此,有可能创建一个流水线进程,在任何时候都可以有几个图像在飞行,最大限度地提高所用逻辑的效率。也就是说,大多数处理元素在大多数时间内都很忙。
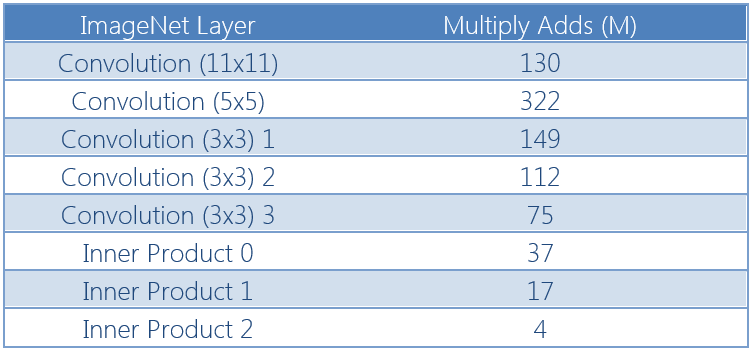
表1:ImageNet层的计算要求
表1显示了Imagenet网络的每一层所需的计算量。从该表可以看出,5×5卷积层比其他层需要更多的计算。因此,这一层需要更多的FPGA的处理逻辑,以便与其他层保持平衡。
FPGA器件有两个处理 区域,DSP和ALU逻辑。DSP逻辑是用于乘法或乘法加法运算的专用逻辑。这是因为使用ALU逻辑进行浮点大(18×18位)的乘法运算成本很高。鉴于DSP操作中乘法的普遍性,FPGA供应商为此提供了专用逻辑。英特尔更进一步,允许重新配置DSP逻辑以执行浮动指针操作。为了提高CNN处理的性能,有必要增加FPGA中实现的乘法数量。一种方法是降低位精度。
大多数CNN的实现都使用浮点精度进行不同层的计算。对于CPU或GPGPU的实现,这不是一个问题,因为浮点IP是芯片结构的一个固定部分。对于FPGA来说,逻辑元素是不固定的。英特尔的Arria 10和Stratix 10器件有嵌入式浮动DSP块,也可以作为定点乘法使用。每个DSP组件实际上可以作为两个分离的18×19位乘法使用。通过使用18位固定逻辑进行卷积,与单精度浮点相比,可用运算器的数量增加了一倍。
图3:Arria 10浮点DSP配置
如果需要降低精度的浮点处理,可以使用半精度。这需要从FPGA结构中获得额外的逻辑,但是假设较低的位精度仍然足够的话,可以使浮点计算的数量增加一倍。
本白皮书中描述的管道方法的关键优势之一是能够在管道的不同阶段改变精度。因此,资源只在必要时使用,提高了设计的效率。
根据CNN的应用容限,位精度还可以进一步降低。如果乘法的位宽可以减少到10位或更少,(20位输出),那么乘法可以只用FPGA ALU逻辑有效地执行。与仅仅使用FPGA DSP逻辑相比,这可以使乘法的数量增加一倍。一些网络可能可以容忍更低的位精度。如果有必要,FPGA可以处理所有低至一位的精度。
对于AlexNet使用的CNN层,我们确定10比特的系数数据是一个简单的固定点实现所能获得的最小缩减量,同时保持相对于单精度浮点操作的误差小于1%。
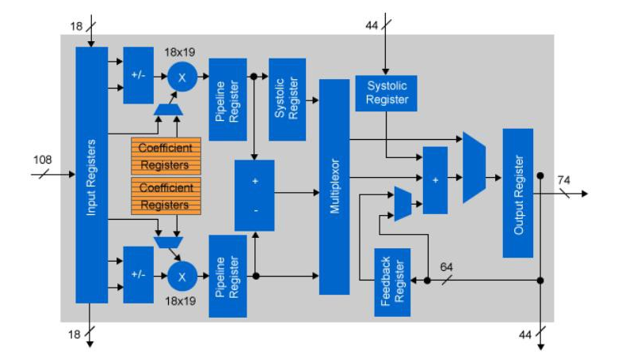
图4:Arria 10固定点DSP配置
使用滑动窗口技术,有可能创建对内存带宽要求极低的卷积核。
图5说明了数据是如何被缓存在FPGA存储器中的,允许每个像素被多次重复使用。数据重复使用的数量与卷积核的大小成正比。
由于每个输入层都会影响CNN卷积层中的所有输出层,因此有可能同时处理多个输入层。这将增加加载层所需的外部存储器带宽。为了减轻这种增加,所有的数据,除了系数,都存储在FPGA设备的本地M20K存储器中。器件上的片上存储器的数量限制了可以实现的CNN层的数量。
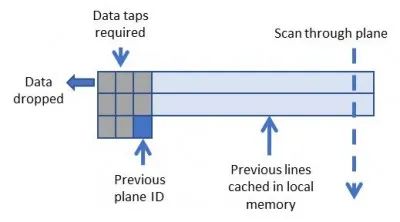
图5:3×3卷积的滑动窗口

图6:OpenCL全局内存带宽(AlexNet)
根据M20K的可用资源量,并不总是能够在单个FPGA上安装一个完整的网络。在这种情况下,多个FPGA可以使用高速串行互连进行串联。这使得网络管道可以被扩展,直到有足够的资源可用。这种方法的一个关键优势是它不依赖批处理来最大限度地提高性能,因此延迟非常低,这对延迟关键应用非常重要。
平衡各层之间的时间,使之相同,需要调整所实施的平行输入层的数量和平行处理的像素数量。
大多数CNN特征将适合于单个M20K存储器,由于在FPGA结构中嵌入了数千个M20K,可用于并行卷积特征的总存储器带宽是10兆兆字节/秒。
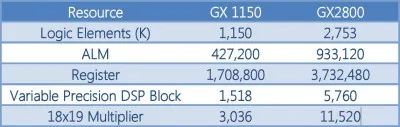
图7:Arria 10 GX1150 / Stratix 10 GX2800资源
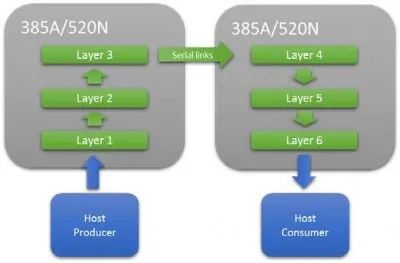
图8:在多个FPGA上扩展一个CNN网络
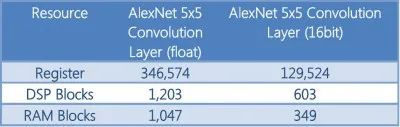
图9:Alexnet的5×5卷积层的资源
图9列出了Alexnet的5×5卷积层与48个并行内核所需的资源,在Intel Arria10 FPGA上的单精度和16位定点版本。这些数字包括OpenCL板逻辑,但说明了低精度对资源的好处。
全连接层的处理需要每个元素都有唯一的系数,因此随着平行度的增加,很快就会出现内存限制。与卷积层保持同步所需的并行量将很快使FPGA的片外存储器饱和,因此建议对输入层的阶段进行分批或修剪。
由于内积层的元素数量较少,批处理所需的存储量与卷积层所需的存储量相比也很小。批处理层允许每个批处理层使用相同的系数,从而减少了外部内存带宽。
修剪的作用是研究输入数据并忽略低于阈值的数值。由于全连接层被放置在CNN网络的后期阶段,许多可能的特征已经被消除了。因此,剪枝可以大大减少所需的工作量。
该网络的关键资源驱动因素是可用于存储每层输出的片上M20K存储器的数量。这一点是恒定的,与实现的并行量无关。将网络扩展到多个FPGA上会增加可用的M20K存储器的总量,因此可以处理CNN的深度。
FPGA结构独特的灵活性允许将逻辑精度调整到特定网络设计所需的最小值。通过限制CNN计算的位精度,每秒可以处理的图像数量可以大大增加,提高了性能并降低了功率。
FPGA实现的非批处理方法允许物体识别的单帧延迟,对于低延迟至关重要的情况是理想的。例如,物体回避。
对AlexNet使用这种方法(第1层为单精度,然后对其余各层使用16位固定),使用单个Arria 10 FPGA可以在大约1.2毫秒内处理每个图像,或者使用两个串联的FPGA可以在0.58毫秒内完成。
免责声明:本文转载自:Bittware,转载此文目的在于传播相关技术知识,版权归原作者所有,如涉及侵权,请联系小编删除(联系邮箱:service@eetrend.com )。

公众号商务合作联系





