几年来,预训练大模型逐渐从一个AI领域内的技术语言,变成了强势出圈的产业热点与社会关注话题。但如果大家关注这一话题,会很容易注意到越来越多的声音开始反思大模型的发展之路。比如,大模型是不是应该一味追求庞大的训练参数?在发展路径上我们是不是只能严格对标GPT-3等国际著名大模型产品?
当中国科技企业与研究机构纷纷投入大模型竞争时,是不是有可能探索出一条属于自己的道路?
在科技自立的需求愈发严峻与明确时,透过大模型竞赛,我们可以看到更多关于AI的产业启示与战略思考。

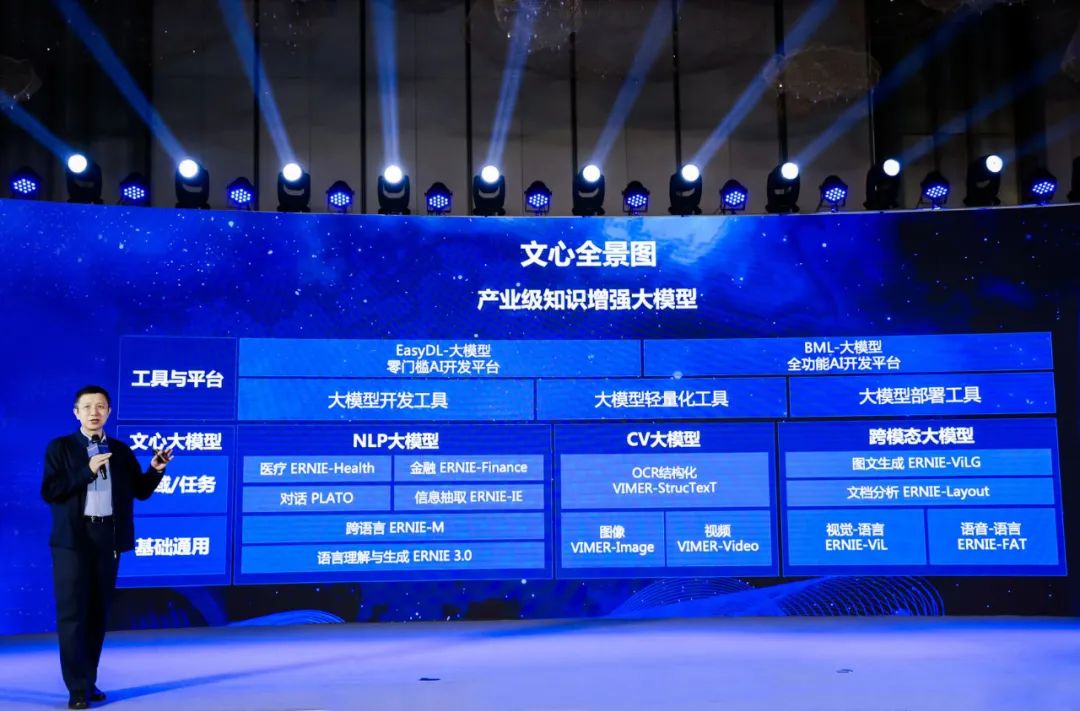
12月8日,鹏城实验室与百度联合召开发布会,正式发布双方共同研发的全球首个知识增强千亿大模型——鹏城-百度·文心。这一大模型参数规模达到2600亿,并且在全球60多项NLP任务中取得了最佳效果。同时,百度产业级知识增强大模型“文心”家族也首次亮相。
早在2019年,百度就开始布局文心预训练模型,如今它也率先走向了差异化拐点。当大众对知识增强这一概念的熟稔远不如大模型本身时,百度文心选择了这条听上去陌生,但却至关重要的产业新径。
大模型为什么重要?为什么我们应该在大模型上探索出新的方向?透过百度文心大模型,我们看到的是科技自立的远方,看到的是中国AI的飞翔之地。
大模型不是军备竞赛,
而是教育竞赛
首先来看大模型本身的行业意义与发展背景。
如今,似乎每家AI企业和研究机构都在做大模型。这种火热局面经常被称为“大模型的军备竞赛”。但如果我们要理解的是,大模型本身是一种产业基础设施和辅助工具,并不是企业与机构的“不传之秘”。
AI产业发展大模型,就像是国家发展教育事业,本身是为了培养更多人才和创新能力,增强整个社会的能动性。
通过海量数据的预训练集成,大模型可以有效降低个体企业与具体行业的AI应用门槛,解决数据标注与行业差异化适配的问题。大模型就像一间间学校,培养了具有通识能力与高素质的人才,从而避免了企业需要从小学知识开始重新培养人才。

这也就将引出一个关键问题:既然大模型是一种“教育系统”,那么教育就应该贴合社会的实际需求。学校肯定不是以用掉了多少书本来评价质量,就像大模型不能仅以训练参数定优劣,更重要的是教育方法是不是与社会适配,能否培育出具有强大能力的人才。
从这个维度上思考,中国AI产业要一直跟随GPT-3等大模型的脚步,一味在训练参数上标榜自身吗?
中国的产业底座、应用需求、技术领导力,是否有可能培育出自己的差异化大模型之路?
此次百度发布的鹏城-百度·文心,以及亮相的百度文心大模型,或许就是答案的方向。
跳出藩篱:
知识增强大模型的差异化之路
2019年3月,在全球大模型的刚刚开始起步的时候,百度就发布了ERNIE 1.0版本,提出了知识增强的语义表示模型。2019年7月,ERNIE 2.0 则构建了持续学习语义理解框架,在中英文 16 个任务上取得了业界最佳效果。
面向NLP领域AI的探索,文心大模型跳出了以往大模型的窠臼,采用了知识增强这一全新技术路径。知识增强将百度在知识图谱、跨模态学习等领域的技术能力,与模型训练学习方面的产业积累结合,实现了更高效率的学习,令模型的理解与生成能力显著增强。
这也很像人类学习的过程,具体信息的学习固然重要,同时知识与逻辑的学习也必不可少。知识既构成了人的通识能力基础,也可以显著提升具体能力的学习与应用。在大模型领域,知识与深度学习的结合起到了事半功倍的效果。
与此同时,文心大模型还强化了跨语言、跨模态的学习能力。在技术的不断迭代之下,文心大模型的泛化能力更强,可以适应更具体真实的任务应用,尤其是处理小样本学习任务的能力。
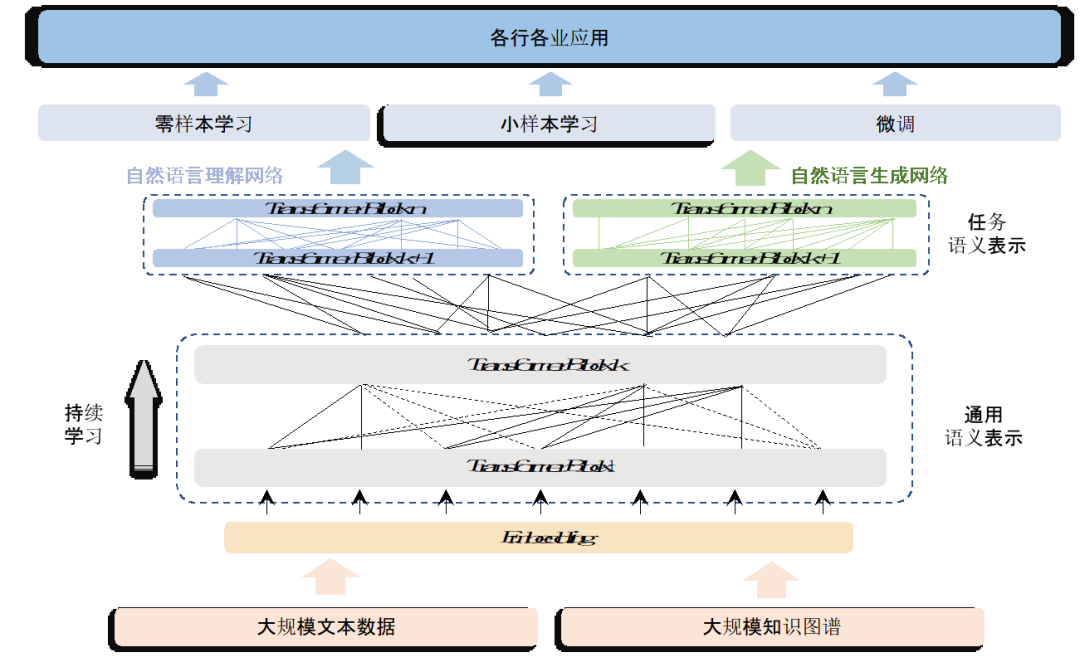
(鹏城-百度·文心模型结构图)
这条差异化之路,让鹏城-百度·文心千亿大模型可以实现更高效率的学习,并在同等参数空间下实现效果更优,并且符合真实场景的应用需求。而能够实现知识增强这条新路的开拓,得益于百度在知识、深度学习、以及模型开发训练并行且长期的布局积累,也得益于鹏城云脑Ⅱ提供的强大算力。
中国AI的积累、实力与需求,共同构成了差异化之路的起点。从这个意义上来看,知识增强大模型的价值并不仅仅在大模型本身。
走向通用:
百度文心的应用拓展空间
BERT、GPT-3等大模型确实取得了惊人的效果,但大模型也经常因为应用上的滞后性引发质疑。其原因主要来自两方面:一是大模型的算力需求过大,成本高昂;二是大模型的泛化能力欠佳,经常难以解决应用场景中复杂多变的实际问题。
面对这些问题,鹏城-百度·文心实现了更强的应用能力。在场景化应用方案中,鹏城-百度·文心可以实现多尺寸的模型蒸馏,甚至以极小尺寸适配具体需求,降低大模型使用门槛与成本。
在通用能力上,通过与知识的结合加上跨语言、跨模态能力的融入,文心大模型可以适配更加多样化、通用化的任务,在通信、金融、医疗等领域具备广泛的应用前景与想象空间。
鹏城-百度·文心在60多项国际著名任务上取得了领先优势,其中有30多项是小样本、零样本学习的任务,表明了鹏城-百度·文心的泛化应用能力更强,可以低门槛适配行业需求与行业能力。

(鹏城-百度·文心小样本学习效果)
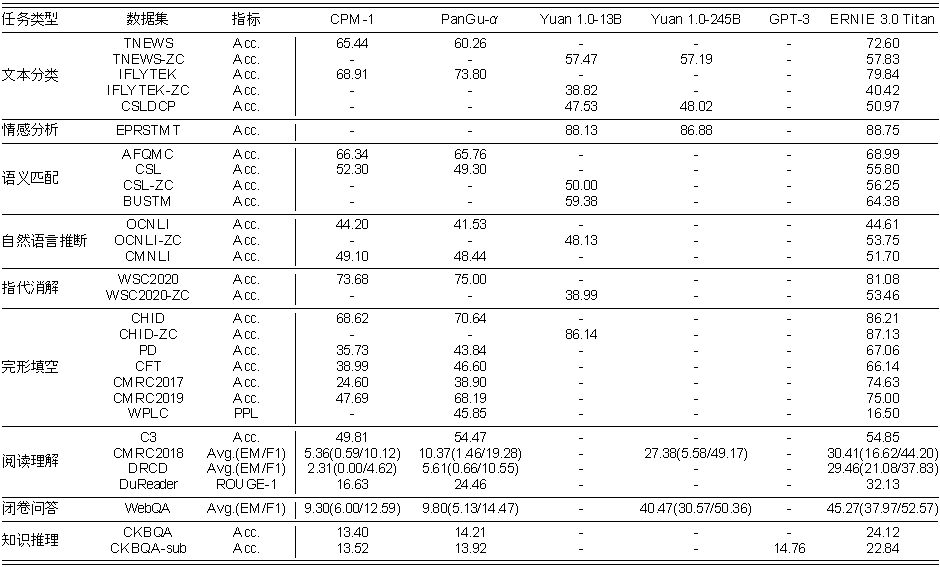
(鹏城-百度·文心零样本学习效果)
在金融领域,文心大模型赋能可以结合百度全流程AI开发平台BML提供的模型再训练能力,基于定制的保险合同条款“智能解析模型”,完成一份合同内近40个类目条款的智能分类,让业务员处理单份合同文本的时长缩短到1分钟,速度提升几十倍。在智能客服领域,文心大模型可以有效提升服务的精准性。这一能力目前已经在浦发银行、中国联通等国内众多企业中得到应用。
整体而言,文心大模型在相对复杂、有考验性的应用场景具备更加强大的表现。比如媒体创作、医疗文本分析、金融信息研判、合同分析等等,这些应用空间非常广阔,并且能够适配的AI技术净值很高,具有明确的商业化动力。
AI正在走向工业大生产,其中核心就是让实验室中的强大AI能力,走入产业,拥抱真实需求。而这就需要大模型具备更强的通用化能力,鹏城-百度·文心正是踏出了这样的关键一步。
文心之路,自立之路:
中国AI的飞翔之地
从技术差异和应用场景出发,我们其实可以从鹏城-百度·文心和百度文心大模型里看到更远。如今,科技自立成为了时代潮流与企业责任,而到底什么是真正的科技自立呢?从鹏城-百度·文心中,我们或许能找到一些新的经验与标准。
在全球瞩目的大模型领域中,知识增强大模型成功打破了固有边界,跳出了“质变没有就拼量变”的传统逻辑。科技自立不是你有什么我也要照猫画虎,你有千亿参数我有万亿参数,而是结合自己的特点与需求,走出能够引领潮流,有独特发展空间的差异化之路。
此次百度的大模型最新发布亮相,可以看到中国AI厚积薄发,学中能变的时代脚步。
在前沿探索上,百度文心大模型在知识增强这个关键点上打破了大模型的产业壁垒,探索全新的技术可能与应用特性,并且将跨语言、跨模态等前沿技术融入其中,构筑更具领导力的技术创新,让中国AI不再仅仅成为模仿者。

在产业协作,百度与鹏城云脑Ⅱ的合作,可以说是集合了中国AI的“最强实力组合”。“鹏城云脑Ⅱ”是自主研发的E级AI算力平台,曾在多个国际性能测试比赛中夺冠。鹏城-百度·文心将基础设施与前沿产业探索进行了有效适配。这种产学一体,软硬件协作,有效利用鹏城云脑Ⅱ作为创新底座的方式可以说是中国AI所独有,在未来很长一段时间将是中国AI产业的特殊优势。
在战略协同中,鹏城-百度·文心可以有效融入百度云智一体的战略架构,大模型通过飞桨的技术创新特性带来高效的训练结果,同时大模型也天然与百度智能云结合,构成了开发者和企业选择百度的动力。云智一体,指向泛化应用与产业需求的AI发展策略,也是中国AI的独特一面。
从源头技术创新,到大模型的知识增强之路;从飞桨核心技术的有效利用,到与鹏城云脑的软硬件合作,鹏城-百度·文心千亿大模型的每一步都根基于自主,每一个选择都趋向于自立。这种既能破壁求变,也能务实协同的发展方法,就是中国AI的飞翔之地。
最近有个话题频频登上热搜,叫做“中国有伟大的知识宝库”。在知识增强的创新之路中,鹏城-百度·文心指向的,就是中国AI这样一个伟大的知识宝库。