

☝ 点击上方蓝字,关注我们


如图1所示,意法半导体AI解决方案涵盖了整个STM32产品组合,借助预训练神经网络,嵌入式开发人员可以在任何基于Cortex M4、M33和M7的STM32上进行移植、优化和验证。STM32Cube.AI是STM32CubeMX的AI扩展包,让客户能够更高效地开发自己的AI产品。

▲图1运行机器学习和深度学习算法的STM32产品组合
本文概述了计算机视觉开发框架FP-AI-VISION1,附有在STM32H7上运行的视觉应用代码示例。
从FP-AI-VISION1代码示例起步,可以轻松实现运行在边缘的不同计算机视觉用例,比如:
生产线上的目标分类,根据目标类型调整皮带的速度
检测产品的典型缺陷
将不同类型的螺栓、意式面食、乐高零件进行分类,并归类到不同的容器中
将设备或机器人操作的材料分类,并相应地调整其行为
将食品分类,以便于烹饪/烧烤/酿造、或重新订购货架上的新产品

食品识别:识别18种常见食物
人员在场检测:确定是否有人出现在图像中
人数统计:基于目标检测模型统计场景中的人数。

▲图2 用于评估FP-AI-VISION1示例的设备
一个在彩色(RGB 24位)帧图像上运行的食品识别应用
一个在彩色(RGB 24位)帧图像上运行的人员存在检测应用
一个在灰度(8位)帧图像上运行的人员存在检测应用
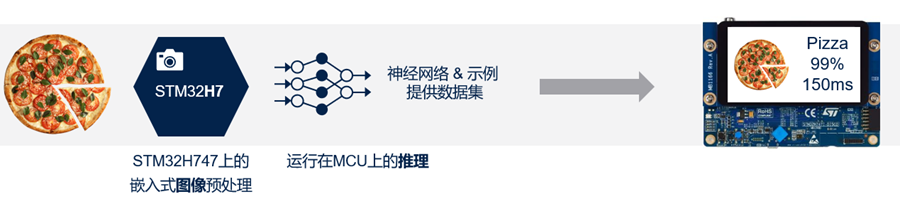
▲图3 食品识别模型的执行流程
一个示例应用基于低复杂度的CNN模型(所谓的Google_Model),作用于分辨率为96 × 96像素的灰度图像(8位/像素)。该模型可以从storage.googleapis.com下载。
另一个示例应用基于复杂度较高的CNN模型(所谓的MobileNetv2模型),作用于分辨率为128 × 128像素的彩色图像(24位/像素)。

▲图4 人员存在检测概述
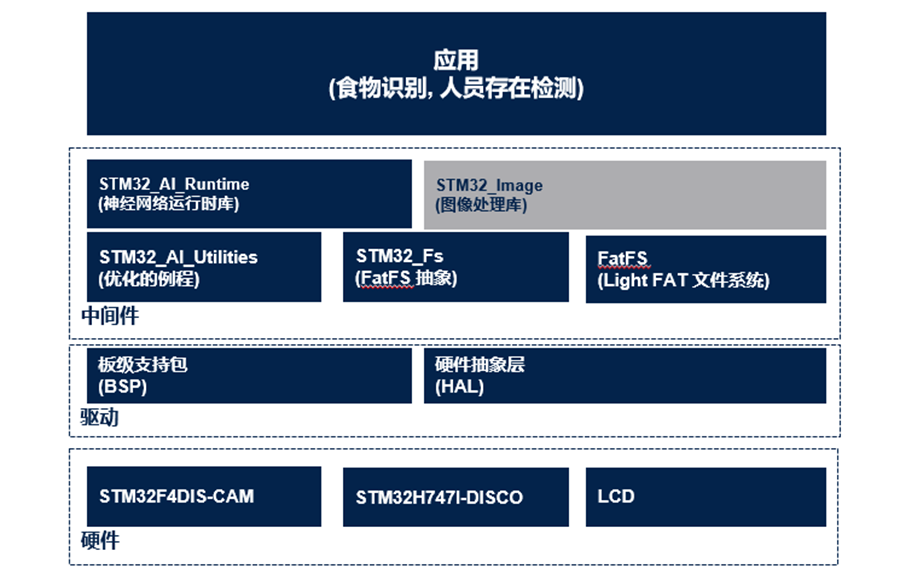
▲图5 FP-AI-VISION1架构
直接从浮点CNN模型生成浮点C代码
或者对浮点CNN模型进行量化以得到8位模型,然后生成相应的量化C代码
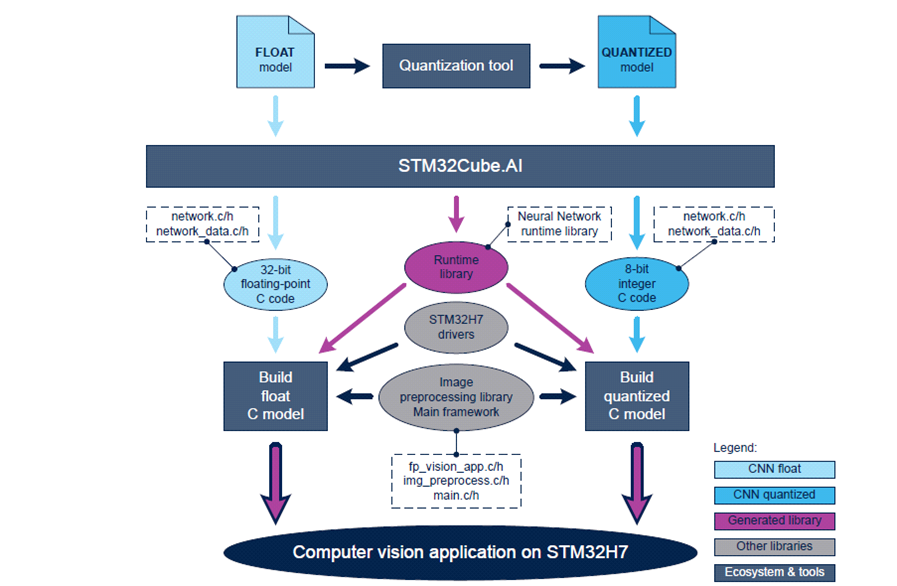
▲图6 FP-AI-VISION1运行架构
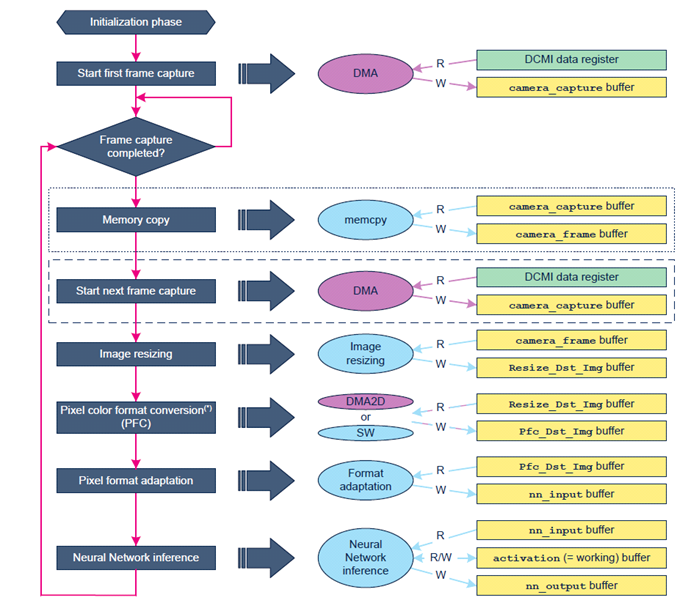
▲图7 执行流程中的数据缓冲区
在camera_capture缓冲区中获取相机帧(通过DMA引擎从DCMI数据寄存器获取)。
此时,根据所选的内存分配配置,将camera_capture缓冲区内容复制到camera_frame缓冲区,并启动对后续帧的捕获。
将camera_frame缓冲区中包含的图像重新缩放到Resize_Dst_Img缓冲区,以匹配预期的CNN输入张量维度。例如,食品识别NN模型需要像‘高度 × 宽度 = 224 × 224像素’这样的输入张量。
执行从Resize_Dst_Img缓冲区到Pfc_Dst_Img缓冲区的像素颜色格式转换。
将Pfc_Dst_Img缓冲区内容中包含的每个像素的格式调整到nn_input缓冲区中。
运行NN模型的推理:nn_input缓冲区以及激活缓冲区作为NN的输入。分类结果存储在nn_output缓冲区中。
对nn_output缓冲区内容进行后处理,并在LCD显示器上显示结果。
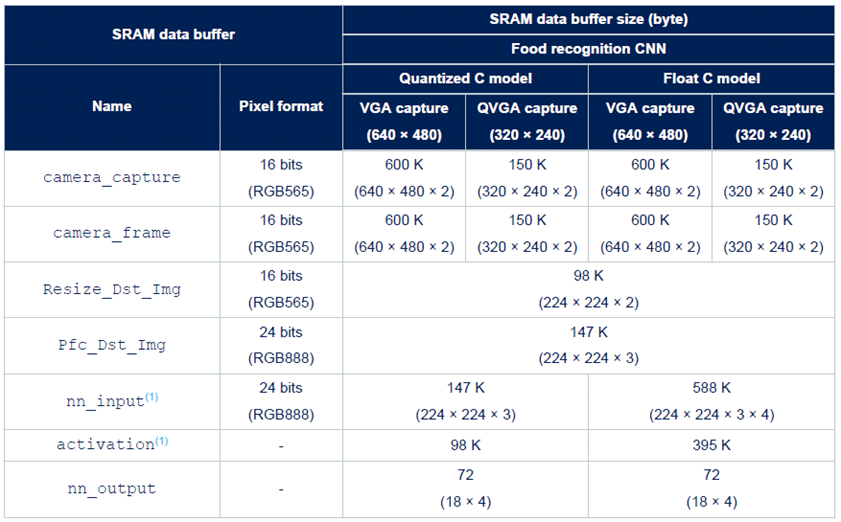
▲表1食品识别应用的SRAM内存缓冲区



 我们将策划一系列AI主题文章,详细介绍意法半导体在Deep Edge AI领域的努力成果。 欢迎您在文后积极留言,告诉我们想了解意法半导体AI的哪些方面,我们将为您呈现更多精彩内容。
我们将策划一系列AI主题文章,详细介绍意法半导体在Deep Edge AI领域的努力成果。 欢迎您在文后积极留言,告诉我们想了解意法半导体AI的哪些方面,我们将为您呈现更多精彩内容。▷ 学知识赢好礼!AI技术专题之一:意法半导体人工智能解决方案概述
▷ AI技术专题之二:机器学习模型设计过程和MEMS MLC【文末留言好礼】
▷ AI技术专题之三:嵌入式机器学习核心运行决策树分类器【文末留言好礼】
▷ AI技术专题之四:AI在Deep Edge领域中的应用
▷ AI技术专题之五:专为STM32 MCU优化的STM32Cube.AI库


点击“阅读原文”,查看更多STM32 AI相关资讯
