去年开始DPU火起来了,各种神仙开始盲人摸象,去年写过一篇关于网络报文处理的文章,想起IPv9的一段话:Those who do not study history, are doomed to repeat it. 有必要把此文改编一下,再次发出来。
去年旧文:>“网络编程” 还是 “可编程网络”?<
当时写这文的时候,其实恰逢我们和某厂一起定制某个DPU,产生了许多争议,甚至发现很多设计的资深工程师已经连很多最基本的东西都忘掉了,有些震惊。这些年亲历了网络芯片从软变硬又从硬变软的过程,有些感慨。
加上最近一段时间软件定义的网络,智能网卡,DPU,SRv6,P4等一系列技术对网络可编程性的体系结构上的改变,在此写一篇综述,一方面是回看历史,另一方面是告诉大家设计东西的时候别走弯路。
注:希望大家看此文的时候从三个维度来看待问题,即软件/硬件/网络报文编码
互联网的网络设备整个发展的历史,我把它分为5个阶段
报文编码 基于目的IP地址的最长匹配做查询软件结构 在软件算法上优化,使用Tree查找和Cache优化硬件结构大量基于MIPS指令集的CPU进行软件转发,后期逐渐出现了基于总线的分布式转发架构,例如Cisco的7500系列路由器
报文编码 MPLS简化核心路由表条目数软件结构 软件结构相对稳定没有太大变化硬件结构专用处理器繁荣的十年,各种专用芯片来做Offload,加密芯片,TCAM查表,各种基于微码的网络处理器,Fabric逐渐采用CLOS架构构建多机集群.报文编码 VXLAN和Overlay的兴起软件结构 软件转发的回归,DPDK/VPP等开源软件的出现硬件结构多核通用处理器性能越来越强,SR-IOV的出现,核心交换芯片越来越强并支持虚拟化报文编码 SegmentRouting,数据包即指令软件结构 容器技术的出现,CNI触发Host Overlay,尽量采用协处理器或者网络设备卸载负担, P4等通用网络编程语言的出现硬件结构可编程交换芯片的出现,各种SmartNIC方案盛行,低延迟通信的需求日益增加,特别是AI带来的快速I/O响应网络的本质其实就是快速,可靠,安全,可控,便捷,便宜的通信,无论哪个厂商设计产品,其实都是在这几个方向上做trade off,不同的时代,有着不同的软硬件选择,但人们常常因为知识受限和对客户使用场景的把握不够,做出错误的选择,或者是过分强调软件, 或者是过分优化硬件,其实从历史的长河来看,这只是一个反复迭代的过程,只希望这小小的一文能给一些在十字路口做决策的人一点点帮助
报文编码 以应用为中心,并兼顾软硬件一体化软件结构 软总线的出现,多云RPC的出现
硬件结构智能进一步下沉到边缘,网络开始变得简单,以直接内存交付为主,隐藏通信一开始的路由器其实是叫服务器的,1986年思科发布的AGS(Advanced Gateway Server)。而Cisco IOS本质上不就是一个软件的操作系统么。

其实从这个时代来看,网络通信数据量并不是太大,协议也相对复杂,更多的是通过IP协议和其它各种协议互通互联,通信需求来看也基本上是在100Mbps处理能力以内,用软件转发是相对较好的解决方案,这一时代的很多产品都是基于MIPS处理器实现的,所以本质上CPU内部还是执行的标准的MIPS指令集, 而路由器的升级更多的就是CPU的升级,从最早AGS使用的Motorola 68000,到后面开始采用 R4600, R4700,到后期的R5000, 总线结构从最早的私有的Cisco Cbus到后期标准的PCI总线的PA卡,以及CyBus这些东西,本质上结构并没有太多的变化:
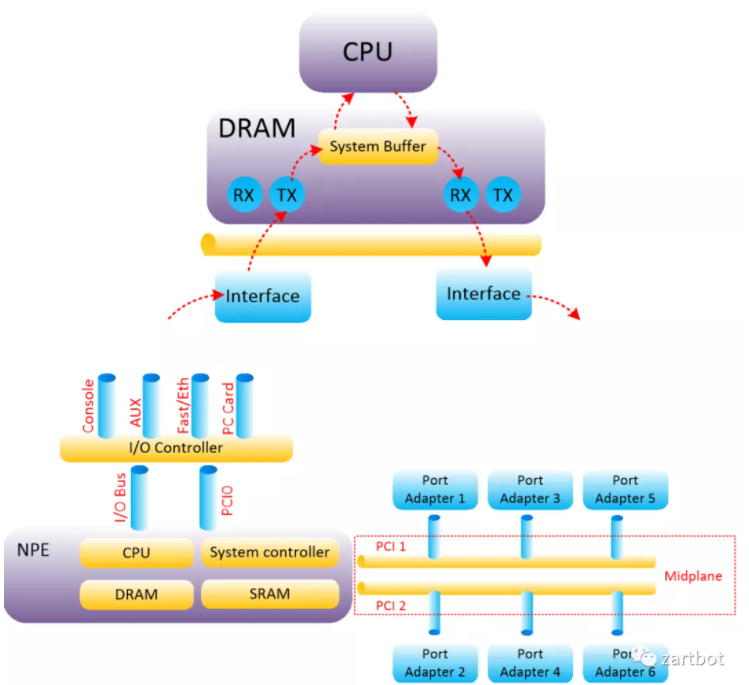
当然这种也是集中式的转发架构, 很多人就会自然而然的想到:性能不够那么就换成多个CPU来转发吧,当年Cisco 7500系列的推出便是这样,在所谓的线卡上放置了CPU,然后将转发表下载到线卡上成就了所谓的Distributed-CEF
报文编码 基于目的IP地址的最长匹配做查询软件结构 在软件算法上优化,使用Tree查找和Cache优化
硬件结构大量基于MIPS指令集的CPU进行软件转发,后期逐渐出现了基于总线的分布式转发架构,例如Cisco的7500系列路由器历史真的是看多了会打脸,最搞笑的是执行这个变革的主导者居然是日后硬件转软件定义网络的先驱,斯坦福老教授Nick Mckeown. 但是也不得不说,其实在不同的时间段人们根据现有的技术做取舍从而满足客户的需求,才是最重要的。
但是从软件到硬件转发,技术上还是有一些区别,一方面就是线卡的ASIC如何设计,另一方面就是Fabric的ASIC如何设计,下面分两章谈。
由于大量的通信来自同一网段的主机,广域网通信带宽本来就小很多, 所以伴随着一个叫“交换机”的东西的出现,思科连续收购了三家以太网交换的公司:Cresendo / Grand Junction / Kalpana,还有ATM交换LightStream,本质上这些公司都是在用ASIC进行特定的转发加速, 毕竟就精确匹配目的地址嘛,做个硬件查表肯定比CPU指令慢慢译码快吧。
但在处理上各家又有不同:直接检查目的MAC的Cut-Through交换,但是在传统的以太网中容易产生碰撞和残帧,所以又出现了检查前64B的Fragment-Free交换用来避免碰撞的碎片,当然还有更稳妥的store-forward机制,但是又会增加延迟。其实这些本质就是产生了一个交叉矩阵来控制开关,这也是switch这一词的由来:
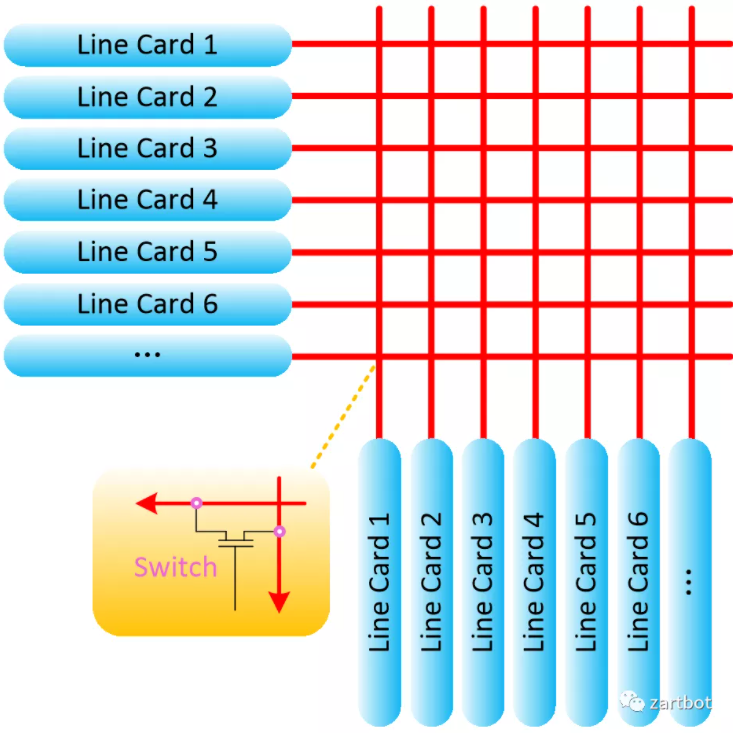
与此同时,总线型的分布式路由器平台也遇到了背板瓶颈,在很长一段时间, 从ISA-->EISA-->PCI总线的增长速度相对较为缓慢. 但是随着Internet的快速发展, 需要更快的backplane. 基于共享总线的交换方式虽然实现简单, 但无法避免内部产生冲突, 使得高速总线设计受到限制. 难度越来越大. 于是也就诞生了把各个接到总线上的分布式线卡换成交换机互联的想法。一个交换平面不够, 那么接多个?神奇的Nick教授正式登上他的舞台,Crossbar架构的路由器就是由斯坦福大学Nick Mckeown在论文《 Fast Switched Backplan for a Gigabit Switched Router》中提出. 该作者也在1995年开始成为Cisco Systems 设计GSR系列路由器的架构师. 随后Cisco推出了基于Crossbar架构的GSR 12000系列路由器.
当然任何技术都会有利也有弊,一方面是如何利用和同步多个Crossbar?另一个是如何防止阻塞?Cell-Based switch和VOQ+iSLIP算法便是Nick教授的惊世骇俗之笔。而读过下面这个的人还在一线干活的估计已经不多了。

CLOS架构
新的做法便是使用多级交换架构来替代原有的基于单级架构的crossbar技术. 多级交换结构的基本组成单位叫交换单元, 每个交换单元具有输入和输出功能. 各个交换单元通过一定的逻辑顺序相互连接, 形成一个巨大的、可扩展的交换网络. 多级交换结构的形式有很多种, 包括Clos、Banyan、Butterfly和Benes等, 各种交换结构的不同主要在于交换单元的互联方式.
例如Cisco的CRS-1则采用了BENES架构:
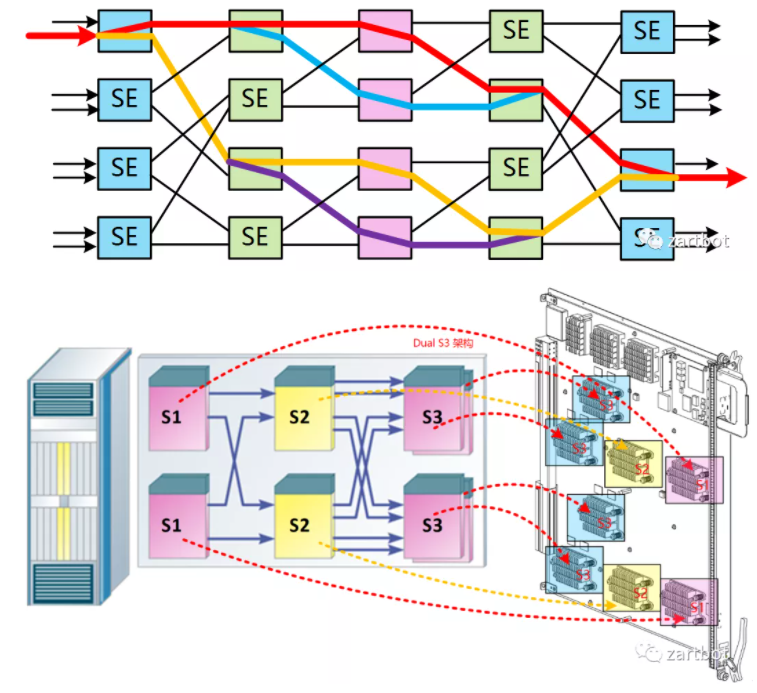
这样多个芯片构成的交换网可以作为并行作为多个fabric连接到线卡上,也可以做成路由器集群构建专门的Fabric机框。
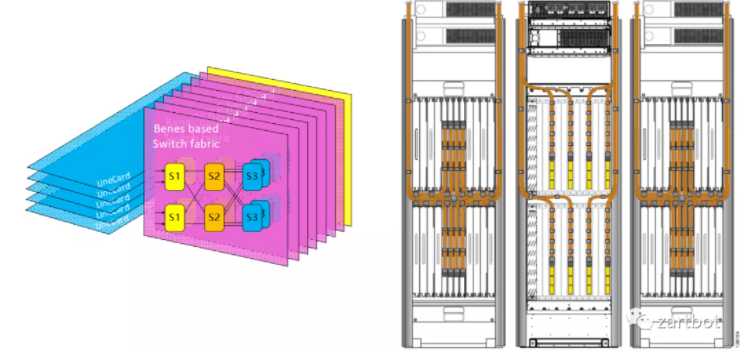
路由器就这样进入了集群的年代,而谁都不会想到10多年以后,一个1RU的pizzabox Silicon One会成为一个庞大集群的替代者。
Fabric设计是相对简单的,困难的还是在线卡上,一方面是路由表的容量越来越大,另一方面是对功能的需求越来越多了。线卡结构的发展历程参考Cisco可以清晰地看到, 从最早的路由器全部使用核心CPU转发. 到后来在总线上使用控制器调度. 再到后期Cisco 7500上使用VIP接口卡, 实现分布式的CPU处理; 然后在基于Crossbar的平台上使用ASIC进行处理. 例如7600上OSM线卡和Cisco 10000系列所使用的PXF. 到最后在线卡上使用网络处理器(NP), 例如Cisco的SPA/SIP架构. 后期例如在CRS-1使用的SPP处理器以及使用全新QuantumFlow网络处理器构建的ASR1000边缘路由器平台等。
其实那些年有很多的争论也有很多的实现,真是百花齐放的年代,而如今这样的争论又在DPU上再次上演:
不得不说的ASIC:TCAM
传统的表项查找方法都是基于SRAM的软件查找方法,共同特点是查找速度慢。线型查找法需要遍历表中的所有表项;二叉树查找法需要遍历树中大多数节点,而且查找速度受树的深度影响较大;基于硬件的TCAM查找法正是在这种背景下提出的,用此方法进行查找时,整个表项空间的所有数据在同一时刻被查询,查找速度不受表项空间数据大小影响。TCAM为啥叫Ternary Content呢,其实就是每个bit位有三种状态, 0,1,Don't care,这样不就很容易去做一些匹配了么,特别是路由器那样的Longest Prefix Match。
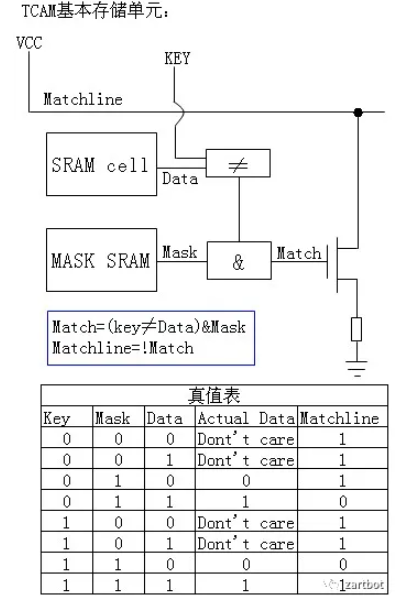
而这样的结构也成了很多公司P4实现的基础器件。
当我们开始对线卡处理器进行加速时,最先想到的便是将一些固定的功能Offload到硬件上批量执行,Cisco PXF(Parralled eXpress Forwarding)也就是在那个特定的年代诞生的, 所以那个年代非常成功的7200系列路由器便是基于这个架构实现的,也使得IOS第一次用上了类多核的转发。只可惜这个处理器不算是真正的处理器,还需要很多微码编程。
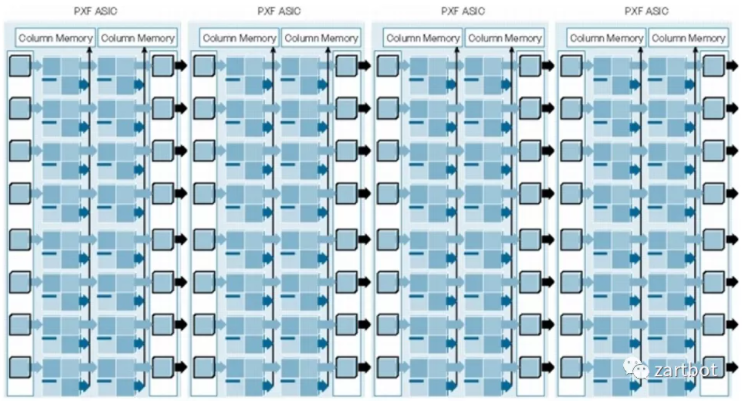
本质是是不是觉得和现在的P4ASIC类似了啊,其实就是一长串的流水线和内存构成的一个ASIC,第一级做A功能,第二级做B功能,一次性并发处理多个报文。
接下来,一个伟大的产品就诞生了,RTC和Pipeline的纷争也就是这个时候开始了
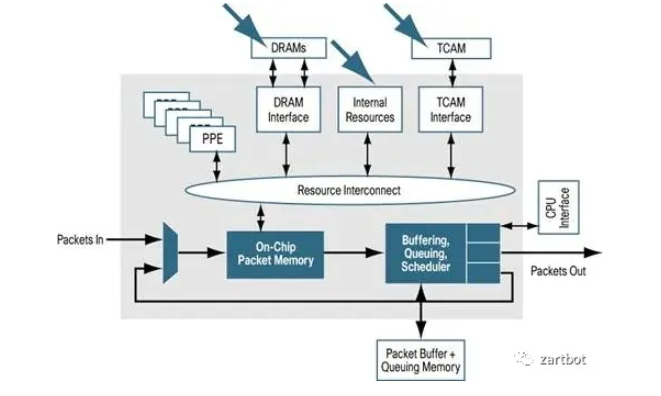
QFP的设计都是采用Run-To-Compile(RTC)的结构,即即便功能再多,一个处理器处理完一个包的所有功能, 然后编程上以C代码为主,内存操作也非常灵活, 它从逻辑上很好的把功能抽象分离了, 一部分是On-Chip Memory用于等待调度到网络处理器PPE中,PPE是一个多核心的专用指令集的处理器(Tensillica的一个精简指令集),这也是我需要强调的,提高性能的方法也可以把通用CPU的指令集精简获得,同时针对网络处理,内存访问的位宽并不一定需要64bit或者32bit,所以很多时候用8bit 16bit的内存访问可以获得很好的加速,然后针对加密和ACL查询采用了片外的TCAM和加密协处理器,QoS这些采用了专用的TM芯片,而路由表查询就是采用了前文所述的Tree Bitmap的算法直接使用DRAM来处理。
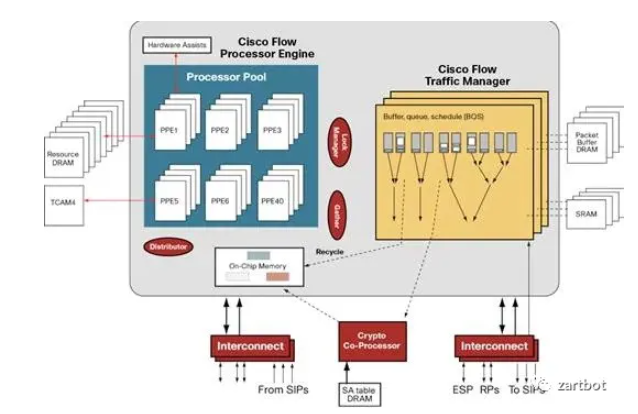
而这些技术也成了我们设计NetDAM的雏形,所有的I/O和CPU核之间有一块内存,而不是简简单单的一个Buffer,精髓就在于此
>NetDAM<
这样的做法在软件编程上就有足够的弹性了,想加什么功能加什么功能,后期基本上一台设备单挑了一堆盒子,成为名副其实的瑞士军刀。
所以我现在都在开玩笑,路由器分两种,一种叫思科企业级路由器,一种叫其它路由器,因为很多人或许都没有想过一个报文需要经历 IPSec加解密、然后路由查询、隧道解封装、内层TLS卸载、压缩、防火墙、DPI、流量调度、计费等一系列流程,时至今日DPU开始需要把它们融合在一起,看到各路只做过皮毛的神仙号称什么都能干,真的是笑而不语...
当年思科是拿C写网络处理器程序,而大家都在用微码写其它家的网络处理器...而这些代表人物基本上又在十年后的DPU时代登场了,例如Intel IXP十几年后就变成了芯启源, Cavium 十多年以后收到Marvell门下诞生了CN10K,RMI被BRCM收购后,然后整个团队被裁掉,倒也诞生了神龙的早期团队和现在的云豹,而Tilera几经流转进了EzChip然后去了Mellanox最后投到nVidia旗下成了如今的BlueField。这个圈子就这么小的渊源...
1995~2010是一个百花齐放的年代,伴随着软件算法遇到瓶颈, 一方面各个厂商从协议上采用MPLS标签来降低查表的复杂度,另一方面则是大量的ASIC和网络处理器的出现,在指令集上针对网络处理进行精简指令集,使用TCAM加速查询,使用Tree Bitmap+DRAM和TCAM解决方案容量上和速度上做取舍, 多核心处理器和片上网络架构在网络处理器中逐渐出现,这也为以后商用处理器出现多核心架构打下了基础。这一章讲了这么多,给大家灌输的观念只有一个,在软件出现瓶颈后,可以通过硬件和报文编码的方式解决, 这个故事过十年又会再重演一次。
报文编码 MPLS简化核心路由表条目数软件结构 软件结构相对稳定没有太大变化硬件结构专用处理器繁荣的十年,各种专用芯片来做Offload,加密芯片,TCAM查表,各种基于微码的网络处理器,Fabric逐渐采用CLOS架构构建多机集群.
分分合合,合合分分,谁都没想到随着虚拟化的兴起,虚拟机内互相通信的网络成为网络设备再一次软件化的开端,当然开始的时候只有交换机, 于此同时为了大量的虚拟交换机编程和转发方便,openflow和openvswtich诞生了,然后公有云和私有云的部署使得网络设备进一步虚拟化,虚拟云路由器也随之诞生, 后面伴随着VDC/VPC的发展,更多的设备虚拟化了:
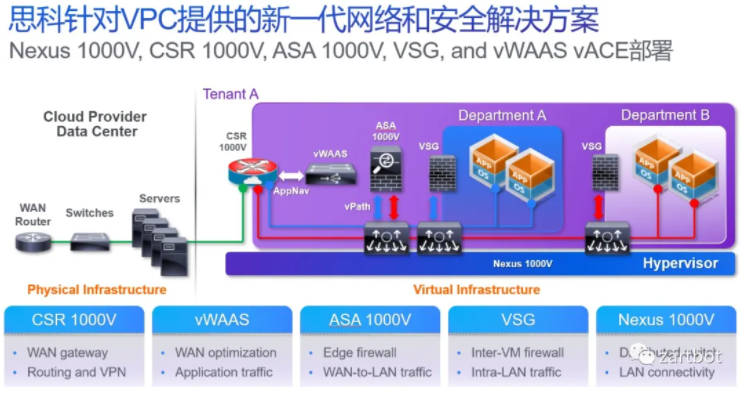
而这个图,在十年后就成为所有的DPU厂商需要集成的功能概括图了...OVS Offload、防火墙、压缩、VPN加密等等...
在由硬到软的过程中,传统的Linux转发遇到了瓶颈:
数据报文达到内核协议栈,进行高层处理。
所以本质上我们需要一套在X86多核处理器上的包快速处理机制,报文直接进入用户态,DPDK使用了轮询(polling)而不是中断来处理数据包。在收到数据包时,经DPDK重载的网卡驱动不会通过中断通知CPU,而是直接将数据包存入内存,交付应用层软件通过DPDK提供的接口来直接处理,这样节省了大量的CPU中断时间和内存拷贝时间。
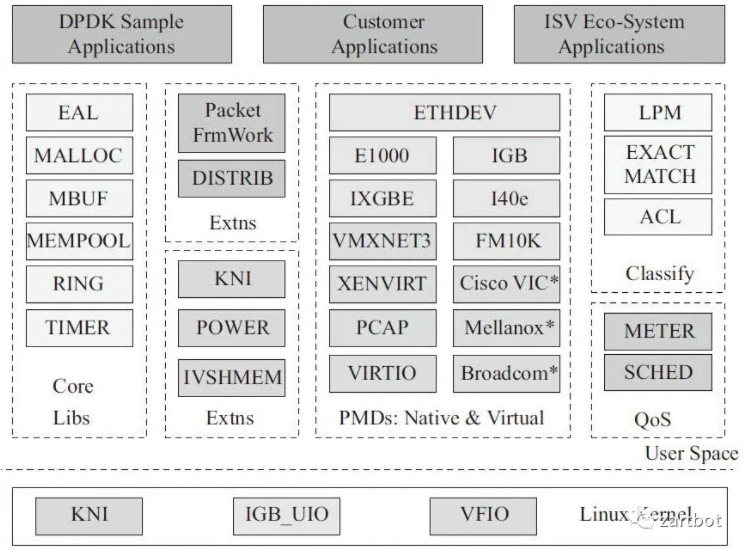
而十年后的DPU则是逐渐把这些功能再从CPU搬出来,而报文的用户态交付还是没有变化的,所以各位好好想想,DPU的最终目标是不是用户态内存交付?
在这个年代,报文编码的发展主要是为了解决虚拟化的问题,基于VXLAN和LISP的overlay技术逐渐兴起,并且随着虚拟化的进程,大量的网络设备被要求在X86的虚拟化平台下运行,虚拟路由器交换机防火墙逐渐出现。当然这个年代为了优化虚拟机的性能出现了DPDK/VPP等开源的软件库,伴随着BGP-EVPN和Yang/netconf等技术的控制器的兴起,SDN逐渐落地,一些专门的虚拟化交换机厂商出现,但似乎最终都没能过上好日子。倒是那些卖交换机的过的日子蛮舒服的, 硬件技术上在这个年代其实就是Serdes的加强,然后大家在Chip上堆料,MAC上定义到100G,似乎整个行业进入了一个简单粗暴的发展过程。
报文编码 VXLAN和Overlay的兴起软件结构 软件转发的回归,DPDK/VPP等开源软件的出现
硬件结构多核通用处理器性能越来越强,SR-IOV的出现,核心交换芯片越来越强并支持虚拟化历史真是一次次的打脸, 等大家全软件了,发现CPU资源的50%以上都被网络占用了,于是各位大爷们又不开心了,特别是公有云,得靠CPU资源挣钱啊, “Intel那糟老头子坏得很~ CPU价格贵贵的~” 于是轰轰烈烈的Offload运动开始了,大家突然又硬了。
渐渐的人们发现软件又不行了, 弄硬件又需要嗑药才能加速,于是所有的目光在软硬兼施都不行的时候,想到了指令集。一方面,通过SR对网络设备进行编码有了SID,然后再编码一个Function和Args, 这样传统的网络设备在执行包头的Destination Lookup的时候, 就可以有更灵活的一个函数Callback栈来实现更多灵活的功能了。
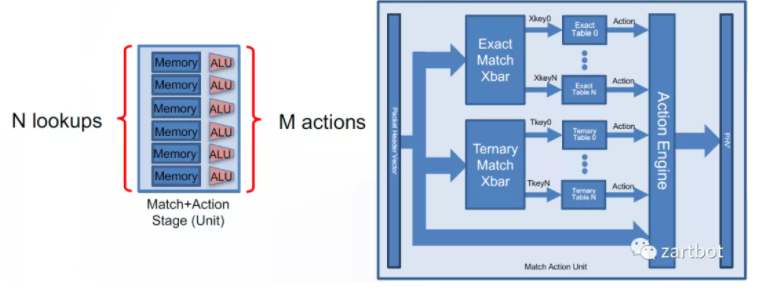
另一方面,我们对网络处理器的抽像可以表示成为大量的连续的Match-Action操作,可以弄成pipeline,于是P4也就顺理成章的诞生了。当然在此之前还有Cisco自己的UADP 芯片的实现就不多说了. 这里面也就诞生了几个公司, Barefoot后来被Intel收购了,Intel开始搞One API, Xilinx做了一个SDNet的库用来将P4重新编译成IPCore。
AWS最早在2011年引入的智能网卡,主要提供的SRIOV一类的VF,随后推出了收购annapurna设计的25G智能网卡, 主要功能就是:承担了原本物理机内虚拟交换机的路由、contrack匹配、ACL过滤、VTEP查表、MAC代答、tunnel建立等工作负载,大幅度降低了网络延时,提高了网络吞吐量。同时硬件实现了虚拟机粒度的、严格的带宽以及五元组流的QoS,保证基本所有类型以及规格的云主机都有稳定可预测的网络性能。
微软的智能网卡的论文就有些多了,并且图文并茂,例如< Large-Scale Reconfigurable Computing in a Microsoft Datacenter >不光是智能网卡这块,连AI的Offload也一起在玩,专门的论文有一篇《A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services》
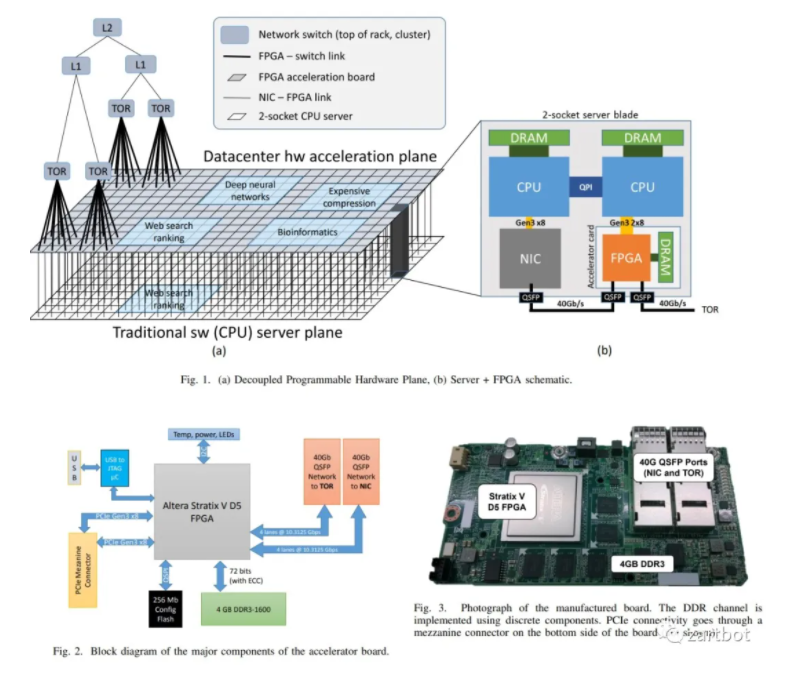
而FPGA的网卡就是在微软的风潮下慢慢火起来的....
一个CPU几十个核,拆分了卖也就是对应的虚拟化架构,例如以Nitro为例,AWS最早基于Xen的虚拟化I/O路径太长,消耗太大,因此逐渐的开始进行优化,例如C3开始使用SR-IOV ,然后C4开始将远端的存储(EBS Volumes)通过新收购的Annapurna以NVMe的形式呈现给虚机。然后X1开始将VPC的一些功能加入,同时也负责磁盘的监控、加密和QoS等业务。最后到了2016~2017这个时间段,唯一的问题就是原来的hypervisor了,最终裸金属出现了.然后到了这个时间段,基本上网卡、存储、各种加速卡、外设都可以虚拟成PCIe设备了。所以你会看到最近AWS发布的基于Apple M1的虚机,直接一根雷电线查到MAC mini上。
而组合则是将多个CPU socket连接,并attach相应的内存和存储按需构建,也就是Fungible一直强调的DPU概念,但是这个概念的最大问题来自于整个Fabric需要Fungible的私有协议,无法多厂商互联,特别是内存如何以池化的方式加载,这便是IBM提出OMI的原因,以及AMD Zen4逐渐也会采用类似的处理方式:
这个年代是一个美好的年代, 是一个体系结构大改的年代,虚拟机都逐渐的被抛弃,更轻量级的容器,Service-Mesh和serverless的架构出现给这个年代带来了太多的机会,人工智能的兴起,高速分布式存储的繁荣,Persistent RAM,一切都为新的时代铺好了基石。人们在一波波的炼丹比分比速度的过程中,终于又想到了网络,开始对网络编程,开始利用ROCE、RDMA降低延迟,体系结构的变革,P4的出现为报文编码的扩充也提供了良好的机遇,这真是一个非常美好的时代~
>包处理的艺术(3)-RTC vs Pipeline<
>包处理的艺术(4)-低延迟智能网卡设计<
>智能网卡的智障需求<
报文编码 SegmentRouting,数据包即指令软件结构 容器技术的出现,CNI触发Host Overlay,尽量采用协处理器或者网络设备卸载负担, P4等通用网络编程语言的出现
硬件结构可编程交换芯片的出现,各种SmartNIC方案盛行,低延迟通信的需求日益增加,特别是AI带来的快速I/O响应这便是一个新的时代的开端,软件编码逐渐开始以应用为中心,通信协议本身兼顾软硬件一体。另一方面随着云的资源广泛部署,在边缘云或者更进一步的元宇宙中,真的存在华为在鸿蒙操作系统中提出的软总线的概念,把云的资源通过一个总线连接到端,而给与端更多智能的选择权。
在这个年代,硬件功耗墙决定了在高密度的地方已经无法再添加新的东西了,而Tofino-3或者说Cisco Silicon One或者BRCM这些可编程的交换机基本上也开始碰到物理瓶颈了,将他们的可编程能力释放出来赋予终端,才是未来。
另一方面,容器本身也带来了大量的挑战,网络协议栈消耗大,智能网卡PCIe SRIOV配置速度慢,直接的容器内存交付便成为未来的趋势,而Serverless的也将从概念走向商用。多云间的RPC和多云分布式数据库和存储都是这一系列变革的根本需求。
而解决这些的软件结构便是一个跨越多云的可靠传输协议,而如今不靠专线能做到200ms internet零丢包,除了我也就另一家借鉴Ruta架构的大厂了...
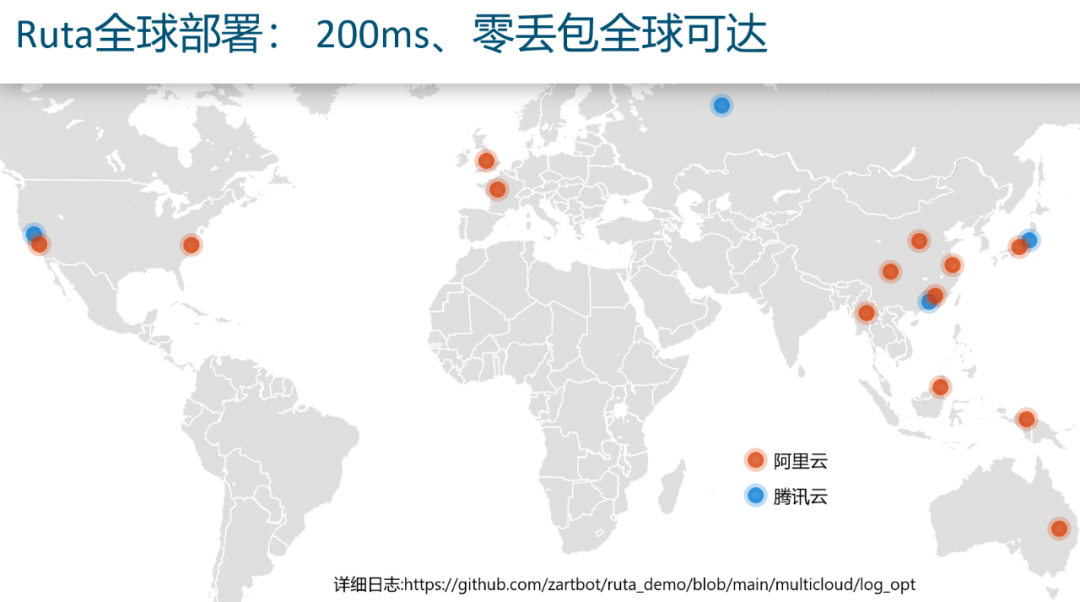
>Ruta实战及协议详解<
而硬件上,可编程网络的真理在哪?或许只在一句很简单的话。
网络的本质是承载数据流,而内存是数据流在某个时刻的快照,而计算是基于快照信息而产生新的数据流。 像NetDAM这样以内存直接交付的通信系统才是未来.
>DPU新范式: 网络大坝和可编程存内计算<
>洞见:下一个十年的云计算架构<
报文编码 以应用为中心,并兼顾软硬件一体化软件结构 软总线的出现,多云RPC的出现
硬件结构智能进一步下沉到边缘,网络开始变得简单,以直接内存交付为主,隐藏通信It was the best of times, it was the worst of times,it was the age of wisdom, it was the age of foolishness,it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair,we had everything before us, we had nothing before us,we were all going direct to Heaven, we were all going direct the other way
--in short, the period was so far like the present period,that some of its noisiest authorities insisted on its being received,for good or for evil,in the superlative degree of comparison only.
免责声明:本文系网络转载,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请第一时间告知,我们将立即删除内容!本文内容为原作者观点,并不代表本公众号赞同其观点和对其真实性负责。