作者:韩柳彤(中国科学院软件研究所智能软件研究中心博士研究生)
在2021年谷歌编程之夏(Google Summer of Code, GSoC)中,笔者使用RISC-V 向量扩展的Intrinsic函数优化了OpenCV DNN模块中多个函数,提高了OpenCV在RISC-V平台上的深度学习推理性能。
本文将简要介绍OpenCV DNN模块的架构和现有的RISC-V平台优化实现方式,之后给出使用Intrinsic函数优化DNN函数的思路,并举例说明实现方法。
OpenCV DNN
OpenCV的深度学习(DNN)模块是一个推理引擎,它支持大多数目前主流的深度学习框架所训练的模型,如TensorFlow、Caffe、Pytorch、ONNX等。DNN模块在2015年首次进入OpenCV项目,从2017年以来,DNN模块有了越来越多的特性,其中包括一系列推理引擎的后端(硬件平台)加速。目前,OpenCV DNN模块已经支持CUDA、Vulkan等GPU后端;在CPU后端方面,DNN模块使用了OpenCV 中的 Universal Intrinsics,已经支持SSE、AVX、Neon和RISC-V Vector等后端。
本项目基于之前的相关工作[1]为DNN模块进一步提供了面向RISC-V Vector平台的加速。下图是深度学习模块的整体架构图,本项目的主要工作在DNN层的实现部分。
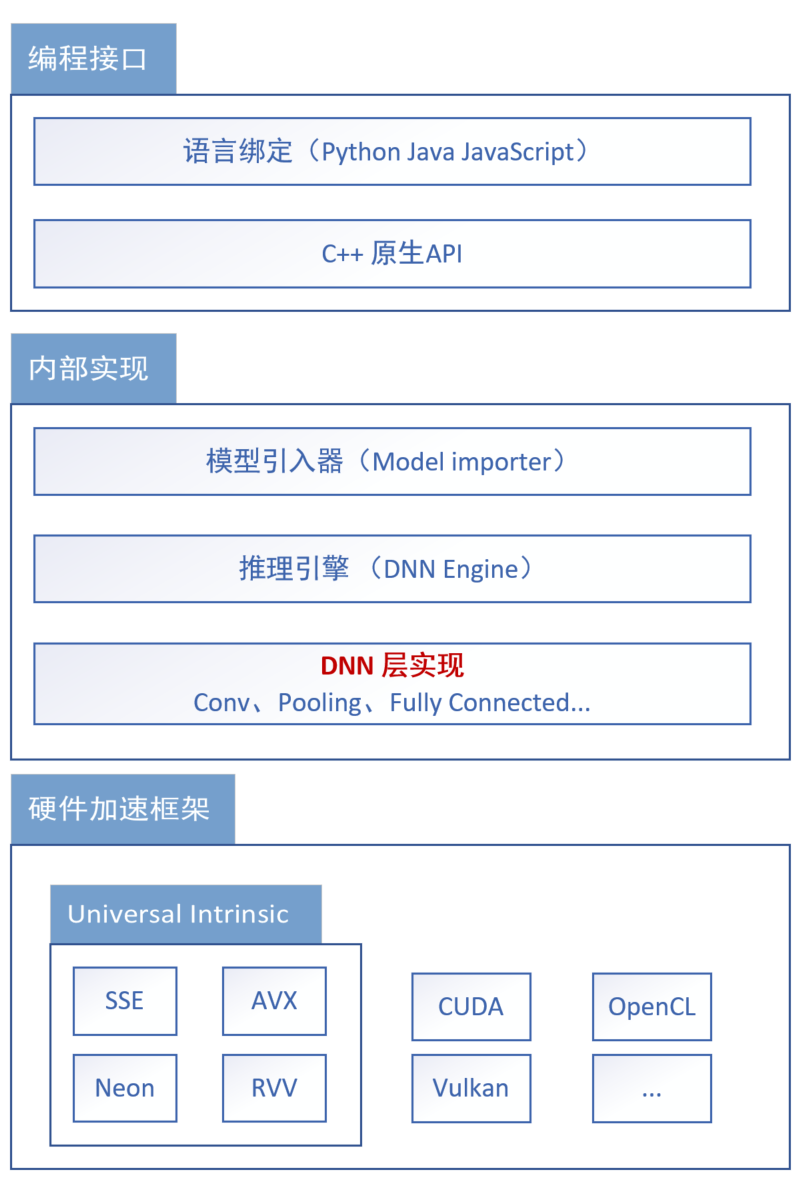
现有的面向RISC-V向量扩展平台的优化主要是基于Universal Intrinsics的循环向量化。
Universal Intrinsics[2]也称统一向量指令,是OpenCV 4 版本中提供的硬件加速层,它抽象了不同指令集的向量指令。使用Universal Intrinsics编写加速算法可以做到一份实现代码在各个硬件平台上都获得向量加速的特性。目前,Universal Intrinsics 已经支持了Intel MMX、SSE、AVX、AVX512、ARM Neon 和 RISC-V Vector后端。
以寄存器加载指令为例,在Intel SSE指令集中,可以使用Intrinsic函数__m128 _mm_loadu_ps(float const* mem_addr)实现将内存中一组32bit浮点数加载到向量寄存器里的操作,而ARM Neon中的 float32x4_t vld1q_f32(float32_t const * mem_addr)和RISC-V Vector中的vfloat32m1_t vle32_v_f32m1 (const float32_t *mem_addr, size_t vl)函数都可以在各自平台上实现相同的操作。但由于各平台的Intrinsic(我们称之为Native Intrinsic)并不统一,因此使用其编写加速代码时,同一个算法需要有多个平台相关版本的实现,且不易扩展和维护。在Universal Intrinsic中,则定义了统一的接口v_load(const _Tp * mem_addr),使用Universal Intrinsic编写的向量加速代码可以通过编译时调度在不同平台上调用各自的Native Intrinsic,从而实现一套加速代码跨平台使用。
Universal Intrinsics 为OpenCV中的加速算法提供了硬件抽象,但也正因为这层抽象而产生的额外开销(多条Native Intrinsics实现某条Universal Intrinsic,对象的构造和析构等)和更多平台相关信息的缺失(如寄存器个数等),使用Universal Intrinsics编写的加速算法性能通常不及直接使用特定平台的Native Intrinsics。因此,我们需要在牺牲一部分性能的跨平台加速(使用Universal Intrinsics)和牺牲跨平台性的最佳性能(使用Native Intrinsics)之间做出取舍。
考虑两种极端情况,即全使用Universal Intrinsics和全使用Native Intrinsics:对于第一种情况,通常是可接受的。虽然我们没有得到最佳性能,但OpenCV开发者们只需要使用Universal Intrinsics实现一次算法,就可以在任何拥有向量扩展的平台上获得还算不错的性能提升了——即使是未来出现的新平台也可以,只需要添加新平台的Universal Intrinsics后端实现,而不必修改算法;对于第二种情况,我们不愿意这样做,因为它太繁杂了。我们需要对每一个算法和每一个后端的组合都实现一次特定算法,虽然能够获得最佳的性能,但同时会带来很大的工作量,也不利于维护。即使我们依旧可以通过条件编译让一套源代码在各个平台上运行,但当算法需要修改,我们不得不修改所有平台上的实现;同样的,当一个新的后端平台被引入时,我们要为该平台版本添加的所有算法实现。
但是,我们可以对一小部分算法采用特殊的策略:依赖条件编译,使用Native Intrinsics实现部分平台上的加速,以达到最佳性能。由于不同算法的调用次数和执行时间不同,我们显然希望进一步优化那些被频繁调用或执行时间更长的算法:在DNN中,我们选择了卷积和矩阵乘法。这样,我们仅需要维护特定平台上(目前有AVX和RVV)少量(在DNN中共4个)的算法,便能够得到可观的总体性能提升。
让我们具体看看这种策略是如何实现的,假设有两个数组进行点乘操作,公式为 c = a * b。我们可以给出下列四种实现方式[3]。
1. 使用标量实现
float a[16] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
float b[16] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
float c[16];
for(int i = 0; i < 16; i++){
c[i] = a[i] * b[i];
}
2. 使用Universal Intrinsics 实现
for(int i = 0; i < 16; i+=4){
v_float32x4 va = v_load(a+i); //从内存a装载4个float到寄存器va
v_float32x4 vb = v_load(b+i); //从内存b装载4个float到寄存器vb
v_float32x4 vc = va*vb; //通过C++运算符重载实现了向量乘法,4个float一次完成
v_store(c+i, vc); //从寄存器vc存储4个float到内存c
}
3. 使用Intel AVX/SSE Native Intrinsics 实现
opt_AVX::fastMul(float* a, float* b, float* c, size_t n) {
for(int i = 0; i < n; i+=4){
__mm128 va = _mm_loadu_ps(a+i); //从内存a装载4个float到寄存器va
__mm128 vb = _mm_loadu_ps(b+i); //从内存b装载4个float到寄存器vb
__mm128 vc = _mm_mul_ps(va,vb); //调用Intrinsics实现向量乘法
_mm_store_ps (c+i, vc); //从寄存器vc存储4个float到内存c
}
}
4. 使用RISC-V Vector Native Intrinsics 实现(假设向量寄存器长度为128bit,下同)
opt_RVV::fastMul(float* a, float* b, float* c, size_t n) {
for(int i = 0; i < n; i+=4){
vfloat32m1_t va = vle32_v_f32m1(a+i, 4); //从内存a装载4个float到寄存器va
vfloat32m1_t vb = vle32_v_f32m1(b+i, 4); //从内存b装载4个float到寄存器vb
vfloat32m1_t vc = vfmul_vv_f32m1(va, vb, 4); //调用Intrinsics实现向量乘法
vse32_v_f32m1 (c+i, vc, 4); //从寄存器vc存储4个float到内存c
}
}
使用c++的条件编译,我们可以编写如下代码:
float a[16] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
float b[16] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
float c[16];
#if CV_TRY_AVX //如果面向AVX平台,就使用AVX Native Intrinsics 实现的版本
opt_AVX::fastMul(a, b, c, 16);
#elif CV_TRY_RVV //如果面向RVV平台,就使用RVV Native Intrinsics 实现的版本
opt_RVV::fastMul(a, b, c, 16);
#elif CV_SIMD128 // 如果面向其他支持SIMD的平台,则使用 Universal Intrinsics 实现的版本
for(int i = 0; i < 16; i+=4){
v_float32x4 va = v_load(a+i); //从内存a装载4个float到寄存器va
v_float32x4 vb = v_load(b+i); //从内存b装载4个float到寄存器vb
v_float32x4 vc = va*vb; //通过C++运算符重载实现了向量乘法,4个float一次完成
v_store(c+i, vc); //从寄存器vc存储4个float到内存c
}
#else //否则,没有向量扩展可用,我们只好使用标量实现
for(int i = 0; i < 16; i++){
c[i] = a[i] * b[i];
}
#endif
DNN层实现中的热点算法的优化思路可以总结为:优先尝试特定平台的优化;如果没有实现或平台不匹配,则尝试Universal Intrinsics的优化;均不可用则使用最基础的标量版本。如下图所示:

当我们使用Native Intrinsics编写加速代码时,我们还可以针对RISC-V Vector平台的特性进一步优化。例如,我们可以尽可能多的使用寄存器:考虑之前描述的数组乘法操作,在一次循环中,我们只用到了va, vb, vc三个向量寄存器。而在RISC-V Vector平台中,我们最多可以使用32个向量寄存器。显然,如果我们可以在每次循环中使用更多的寄存器,就可以处理更多的数据,以减少循环次数并提高性能。在RISC-V Vector平台中,多个向量寄存器可以被组合使用[4],从而让单条向量指令操作多个(一组)向量寄存器。
同样以处理数组点乘为例,假设待处理数组中各有64个float,在不使用寄存器分组时,每次可以处理4个float,需要循环16次;当将8个寄存器分为一组时,代码如下:
opt_RVV::fastMul(float* a, float* b, float* c, size_t n) {
for(int i = 0; i < n; i+=4*8){
vfloat32m1_t va = vle32_v_f32m8(a+i, 4*8); //将8个向量寄存器视为一个,装载32个float到va
vfloat32m1_t vb = vle32_v_f32m8(b+i, 4*8); //将8个向量寄存器视为一个,装载32个float到vb
vfloat32m1_t vc = vfmul_vv_f32m8(va, vb, 4*8); //调用Intrinsics实现向量乘法
vse32_v_f32m1 (c+i, vc, 4*8); //存储到内存c
}
}
在这种情况下,我们一共使用了24个向量寄存器,每次循环可以处理32个float,原本需要执行16次的循环仅需执行2次即可。
但随之而来的问题是,如果待处理的数组长度不是32的倍数,则最后一次循环将试图读取和写入超过数组边界的内存地址,我们将这类问题的解决方法称为尾端处理。通常,有两种策略处理尾端:放弃最后一次循环,转而使用标量;引入掩码。在实际中(如AVX版本的实现)都采用第一种策略,即在n-1向量循环后追加1个标量循环,这是因为掩码运算的开销通常很大,但追加标量循环的方式也会损失一部分性能,同时增加代码体积。而在RISC-V Vector平台中,我们可以使用向量长度寄存器vl解决这个问题[5]。
vl寄存器保存一个无符号整数,用于控制向量指令所操作寄存器内的元素个数。例如,vle32_v_f32m1(a,2)函数将从a内存空间加载两个float到向量寄存器中,而不是4个。在调用Intrinsics时,我们可以显式给出vl参数,从而在不增加开销的情况下更好的处理尾端:
opt_RVV::fastMul(float* a, float* b, float* c, size_t n) {
int vl = 4*8;
for(int i = 0; i < n; i+=vl){
if (i + vl > n) // 如果再处理32个元素就要越界了(说明本次循环是最后一次,即尾端)
vl = n - i; // 则只处理剩下的(n-i)个
vfloat32m1_t va = vle32_v_f32m8(a+i, vl); //将8个向量寄存器视为一个,装载vl个float到va
vfloat32m1_t vb = vle32_v_f32m8(b+i, vl); //将8个向量寄存器视为一个,装载vl个float到vb
vfloat32m1_t vc = vfmul_vv_f32m8(va, vb, vl); //调用Intrinsics实现向量乘法
vse32_v_f32m1 (c+i, vc, vl); //存储到内存c
}
}
通过使用RISC-V Vector平台的Intrinsic实现加速算法,并使用寄存器分组和向量长度寄存器vl进一步优化,OpenCV DNN模块可以在RISC-V Vector平台上获得更好的推理性能。
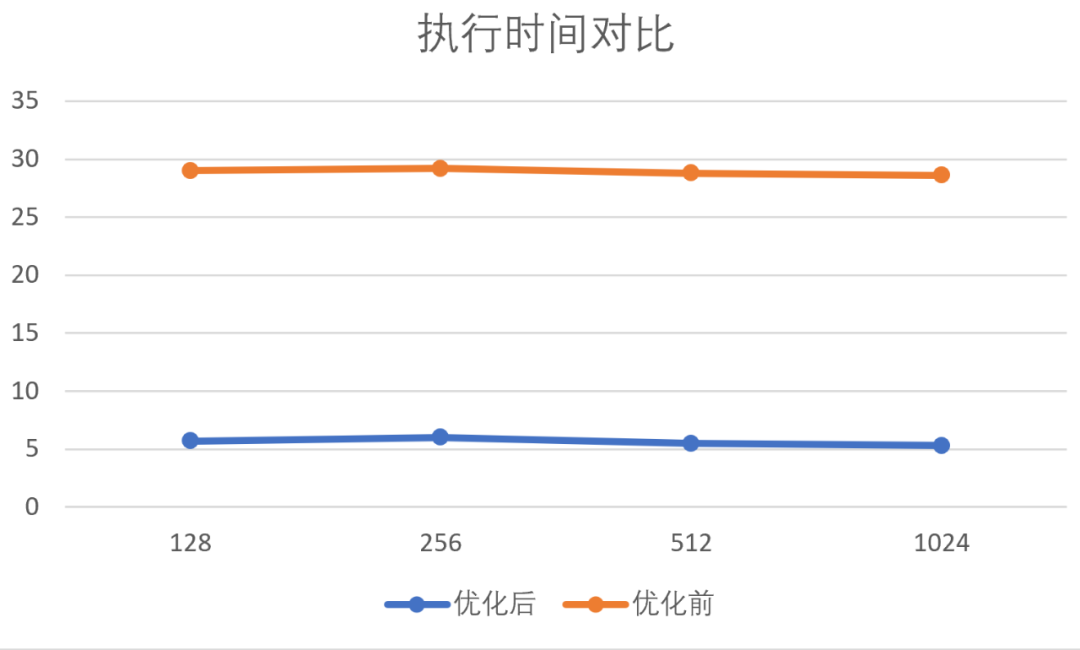
在实际中,我们实现了卷积(Conv)、深度可分卷积(DepthwiseConv)、矩阵乘法(GEMM)和转置矩阵乘法(GEMM1T)四个算法,并在QEMU模拟器上验证了正确性。性能提升方面,由于缺少支持(0.10及以上版本)向量扩展的硬件设备或架构/指令级别的模拟器,目前仅使用 OpenCV DNN 测试集在 QEMU 模拟器上的执行时间作为性能指标。由于 QEMU 是功能仿真的模拟器,该性能指标仅具有十分有限的参考意义。
以下图表是在不同向量寄存器长度下,该优化工作与优化前的执行时间对比,以小时为单位。

以上是对GSoC 2021 优化面向RISC-V平台的OpenCV DNN模块项目的一个背景和实现思路简介,欢迎大家关注2021年11月16日的OpenCV Webinar网络直播,届时笔者会和大家分享包括卷积和矩阵乘法实现在内的更多项目细节,并介绍RISC-V Vector平台中向量长度不可知(Vector-Length Agnostic,VLA)特性在本项目中的应用。
[1] 张尹同学的GSoC 2020项目 Optimize OpenCV for RISC-V 为 Universal Intrinsics 增加了RISC-V Vector后端
[2] 详见 OpenCV Docs: Universal intrinsics
https://docs.opencv.org/4.x/df/d91/group__core__hal__intrin.html#ga05bb5c33c35c2aa1d1c5809b9220d268
[3] 该例子和1,2两种实现代码摘自OpenCV中国团队文章:使用OpenCV中的universal intrinsics为算法提速 (1) ,作者为于仕琪老师。
[4] 详见RISC-V-Spec(https://github.com/riscv/riscv-v-spec/blob/master/v-spec.adoc#sec-inactive-defs): 3.4.2章节:Vector Register Grouping
[5] 详见RISC-V-Spec(https://github.com/riscv/riscv-v-spec/blob/master/v-spec.adoc#sec-inactive-defs): 5.4章节:Prestart, Active, Inactive, Body, and Tail Element Definitions

