

上篇文章我们对mpy标准微库进行了简单的方法罗列,又因为mpy是从标准的Python库中退化而来,那就先简单的学习一下Python的库。

上面的文章说了这么多,那这篇就写这些
我这里就用3.8写了,使用jupyter环境
array是一个高效的数组模块,该模块定义了一个对象类型,它可以紧凑地表示一组基本值:字符、整数、浮点数。数组是序列类型,其行为与列表非常相似,只是其中存储的对象类型受到限制。类型是在创建对象时使用类型代码指定的, 类型代码是单个字符。定义了以下类型代码:
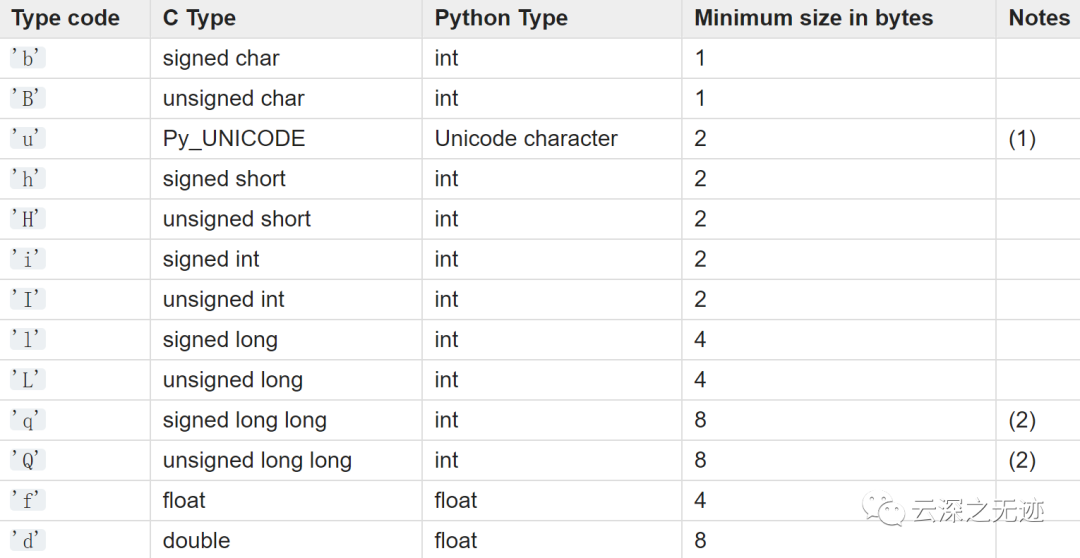
笔记,记好了
mpy中支持的格式代码:b, B, h, H, i, I, l, L, q, Q, f, d(后 2 种取决于浮点支持)。
那这个和list有什么区别呢?首先是一种序列类型,序列方法都可以在上面使用。然后数组类型的对象是固定的,不可以混合装载

使用要先导入,然后一开始要指定存储的数据类型

后面用元组传入存储的东西
IDE可以智能的给出方法

这里使用了一个列表的转换方法

这个比较简单,实验了mpy提供的一个添加方法
请看extend的方法
array.extend(iterable)
将来自 iterable 的项添加到数组末尾。如果 iterable 是另一个数组,它必须具有 完全 相同的类型码;否则将引发 TypeError。如果 iterable 不是一个数组,则它必须为可迭代对象并且其元素必须为可添加到数组的适当类型。
限制较多,其实数据类型相同就行。其实方法这么少,正好可以去看看实现,谁说不是呢?

二进制之间的转换方法,没有什么说的
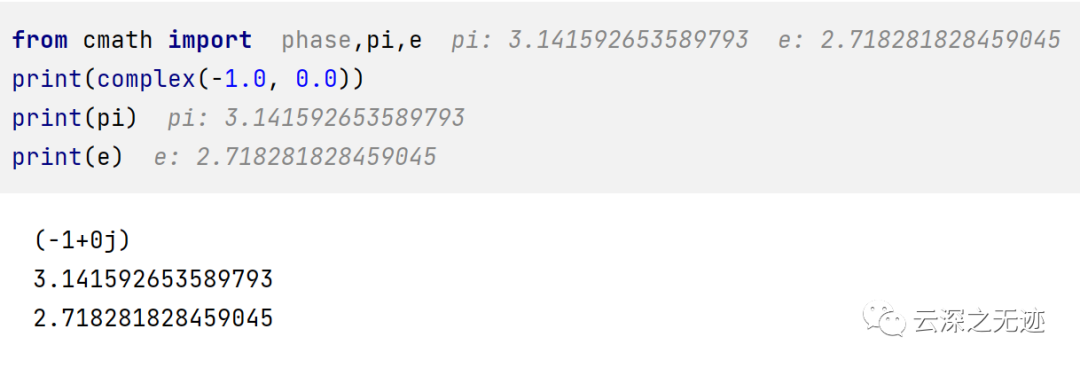
复数运算

这是完整的双端队列

mpy提供了两个方法
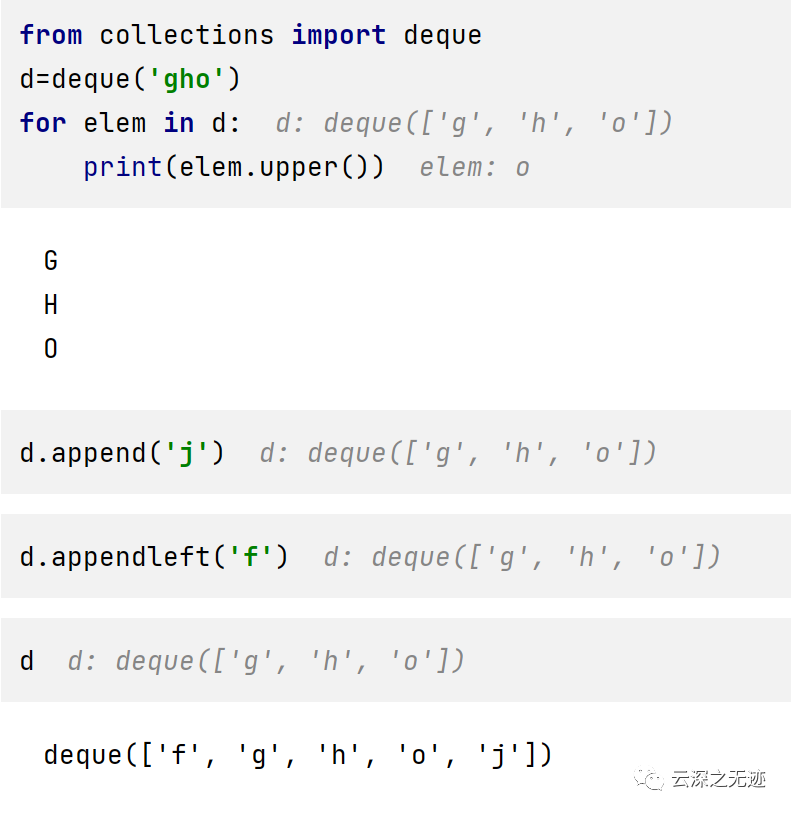
我这里就做简单的演示

这些方法mpy不支持而且很多方法是之后才加进来的
在看命名数组之前,需要知道一个概念,叫工厂函数:
工厂函数看上去有点像函数,实质上他们是类,当你调用它们时,实际上是生成了该类型的一个实例,就像工厂生产货物一样.
python核心编程
https://www.cr173.com/soft/10446.html书籍的下载位置

书籍封面

当然java里面也有这样的概念,你可以看看

看这个,list这个函数本身就有工厂函数的能力
工厂函数是指这些内建函数都是类对象,当你调用它们的时候,实际上是创建了一个类实例,其实也可以理解成内建函数。
https://www.zhihu.com/question/20670869归根结底,它源于设计模式中的一种说法,就是指你不通过类来直接构造对象,而是通过一个函数来构造对象,这样允许你在函数中加入更多的控制。
懵了吗?要是就这就懵了,那别看了~
其中命名元组赋予每个位置一个含义,提供可读性和自文档性。它们可以用于任何普通元组,并添加了通过名字获取值的能力,通过索引值也是可以的。
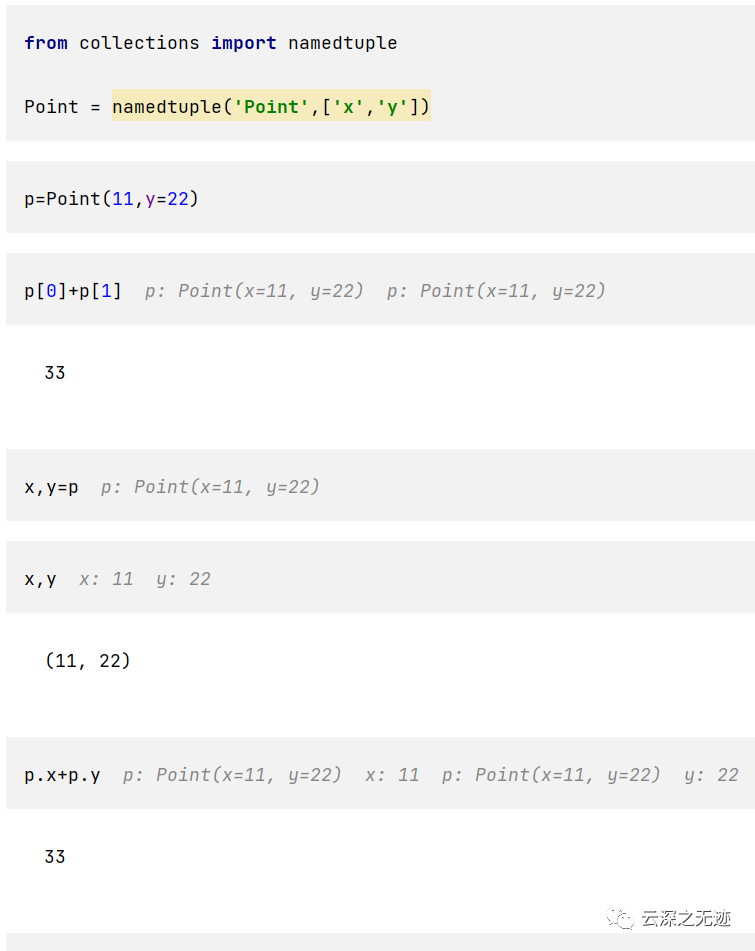
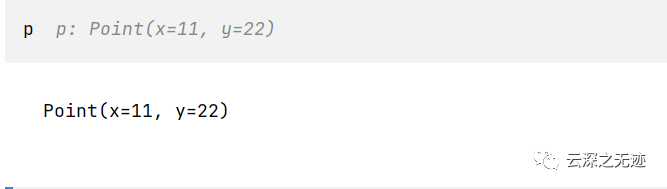
我觉得你看例子就能看懂
其中有使用位置和关键字实参,可以像普通元组一样去索引,字段可以用命去访问,加入了__repr__的值方法。
在mpy里面是这样使用的:
from collections import namedtupleMyTuple = namedtuple("MyTuple", ("id", "name"))t1 = MyTuple(1, "foo")t2 = MyTuple(2, "bar")print(t1.name)assert t2.name == t2[1]
命名元组实例没有字典,所以它们要更轻量,并且占用更小内存。
我这个ordereddict真的不知道怎么翻译了,反正就是可以迭代的时候(就是打印的时候可以按照你加进去的顺序打印)
它会返回一个 dict 子类的实例,支持常用的 dict 方法。Ordered Dict 是一种记录键首次插入顺序的 dict 。如果新条目覆盖现有条目,则原始插入位置保持不变。删除一个条目并重新插入它将把它移到末尾。

这是标准Python库
from collections import OrderedDictd = OrderedDict([("z", 1), ("a", 2)])# More items can be added as usuald["w"] = 5d["b"] = 3for k, v in d.items():print(k, v)
使用前记得初始化,以上为mpy
z 1a 2w 5b 3
输出
接下来是文章中最有技术含量的东西,堆队列算法,这个东西讲起来就有学术味道了,而且还需要补充一些知识才可以。
容器:
在计算机科学中,容器是一个类或数据结构,其实例(运行实体)是其他对象的集合。换句话说,它们以遵循特定访问规则的有组织的方式存储对象。容器的大小取决于它包含的对象(元素)的数量。各种容器类型的底层(继承)实现的大小和复杂性可能不同,并为任何给定场景选择正确的实现提供了灵活性。
容器可以通过以下三个属性来表征:
1.access,即访问容器对象的方式。在数组的情况下,访问是通过数组索引完成的。在堆栈的情况下,根据LIFO(后进先出)顺序进行访问,而在队列的情况下,根据FIFO(先进先出)顺序进行访问;
2.storage,即容器对象的存储方式;
3.traversal,即遍历容器对象的方式。
容器类应该实现方法来执行以下操作:
1.创建一个空容器(构造函数);
2.将对象插入容器;
3.从容器中删除对象;
4.删除容器中的所有对象(清除);
5.访问容器中的对象;
6.访问容器中的对象数量(计数)。
7.容器有时与迭代器一起实现。
注意,容器其实是一种组织形式,就是特定的操作定义。它不单单是一种数据结构,它是一种更加高层的对数据结构的表达。
堆又是属于队列这种结构:
在计算机科学中,队列是按序列维护的实体集合,可以通过在序列的一端添加实体和从序列的另一端删除实体来修改。按照惯例,添加元素的序列末尾称为队列的后部、尾部或后部,删除元素的末尾称为队列的头部或前部,类似于以下使用的词人们排队等候商品或服务。
将元素添加到队列尾部的操作称为入队,而从队列中移除元素的操作称为出队。也可能允许其他操作,通常包括查看或前端操作,该操作返回下一个要出队的元素的值而不将其出队。
队列的操作使其成为先进先出 (FIFO) 数据结构。在 FIFO 数据结构中,添加到队列的第一个元素将是第一个被删除的元素。这相当于要求一旦添加了新元素,必须先删除之前添加的所有元素,然后才能删除新元素。队列是线性数据结构的一个例子,或者更抽象地说是一个顺序集合。队列在计算机程序中很常见,它们被实现为与访问例程耦合的数据结构、抽象数据结构或在面向对象的语言中作为类。常见的实现是循环缓冲区和链表。
队列在计算机科学、传输和运筹学领域提供服务,其中存储和保存各种实体(如数据、对象、人员或事件)以供以后处理。在这些上下文中,队列执行缓冲区的功能。队列的另一个用途是实现广度优先搜索。

大O表示
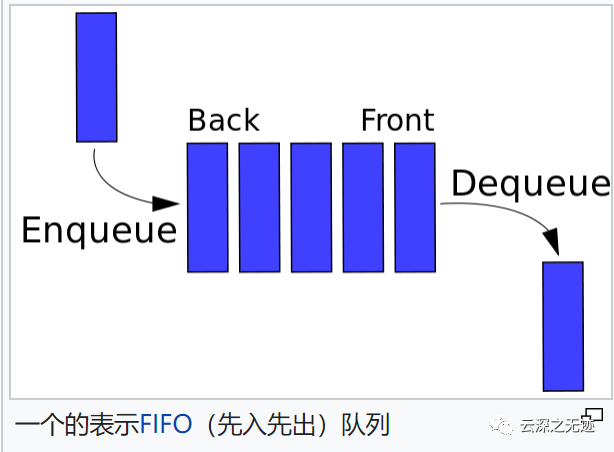
这个东西算是最出名的东西
那我们的堆是队列中的优先级队列:
在计算机科学中,优先级队列是一种抽象数据类型,类似于常规队列或堆栈数据结构,其中每个元素还具有与其关联的“优先级”。在优先级队列中,优先级高的元素在优先级低的元素之前被服务。在某些实现中,如果两个元素具有相同的优先级,则根据它们入队的顺序为它们提供服务,而在其他实现中,具有相同优先级的元素的排序是不确定的。
虽然优先级队列通常用堆实现,但它们在概念上与堆不同。优先级队列是一个类似于“列表”或“地图”的概念;正如列表可以用链表或数组实现一样,优先队列可以用堆或各种其他方法(例如无序数组)来实现。
上面这么多就够了,这里只说一下。堆是一种称为优先级队列的抽象数据类型的最高效率实现,实际上,优先级队列通常称为“堆”,无论它们如何实现。在堆中,最高(或最低)优先级的元素总是存储在根。但是,堆不是排序结构;它可以被认为是部分有序的。当需要重复删除具有最高(或最低)优先级的对象时,堆是一种有用的数据结构。
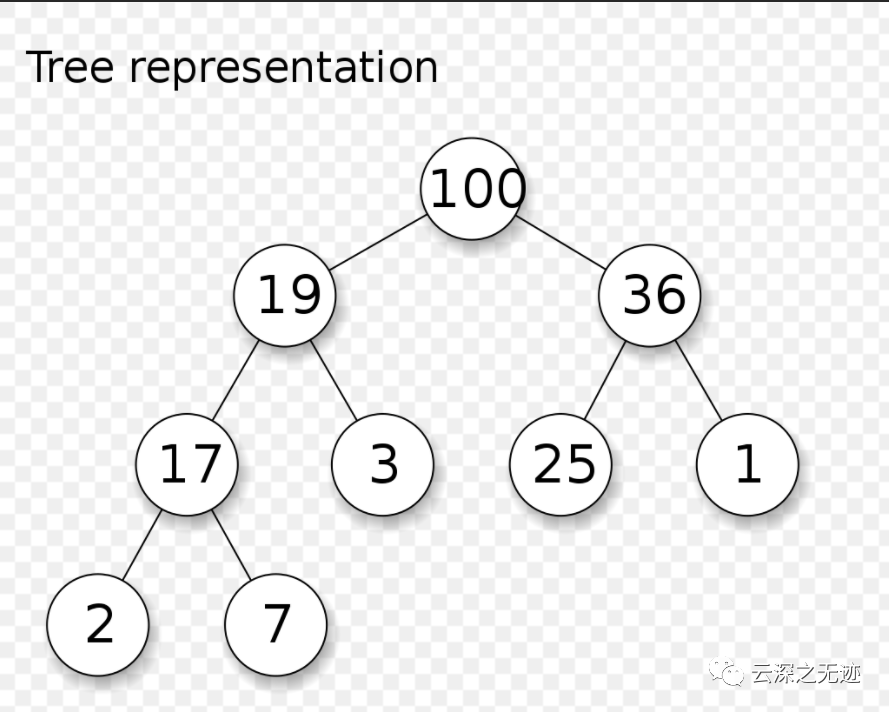
一个图解决战斗,看节点的数字大小

只实现了这三个
这个模块提供了堆队列算法的实现,也称为优先队列算法。
堆是一个二叉树,它的每个父节点的值都只会小于或大于所有孩子节点。它使用了数组来实现:从零开始计数,对于所有的 k ,都有``heap[k] <= heap[2*k+1]`` 和 heap[k] <= heap[2*k+2] 。为了便于比较,不存在的元素被认为是无限大。堆最有趣的特性在于最小的元素总是在根结点:heap[0] 。
这个API与教材中堆算法的实现不太一样,在于两方面:
(a)我们使用了基于零开始的索引。这使得节点和其孩子节点之间的索引关系不太直观,但是由于Python使用了从零开始的索引,所以这样做更加合适。
(b)我们的 pop 方法返回了最小的元素,而不是最大的
(这在教材中叫做 “最小堆”;而“最大堆”在课本中更加常见,因为它更加适用于原地排序)。
基于这两方面,把堆看作原生的Python list也没什么奇怪的: heap[0] 表示最小的元素,同时 heap.sort() 维护了堆的不变性!

注意堆的实现,是一个单独的模块
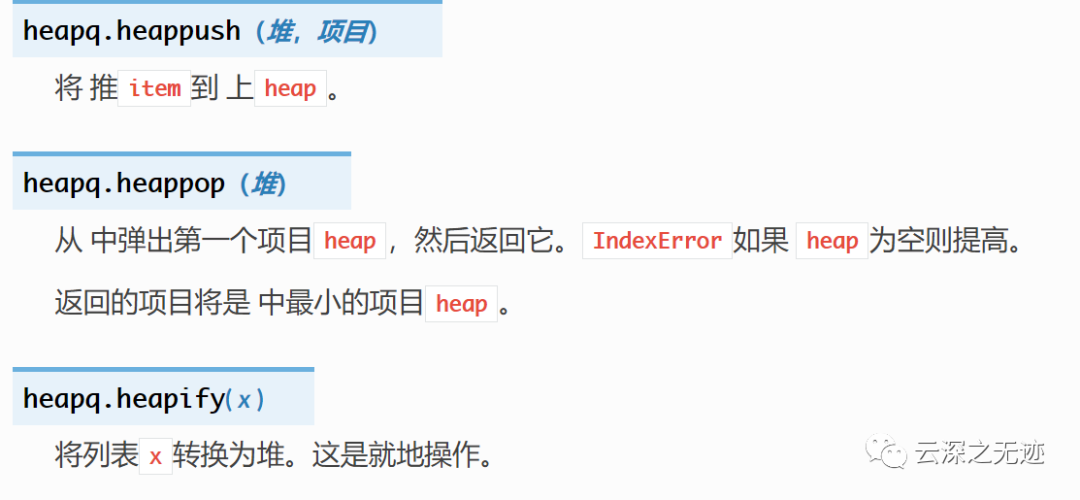
mpy中的堆操作,之后在使用的时候做说明
