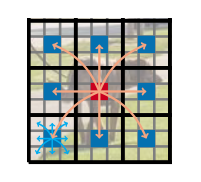
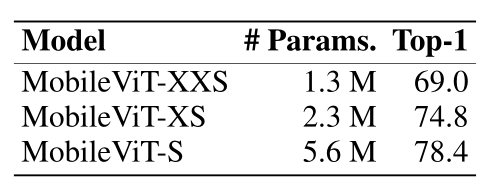
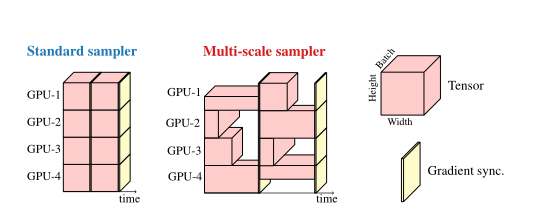
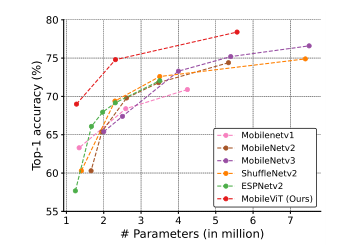
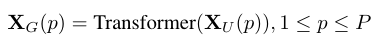点击上方↑↑↑“OpenCV学堂”关注我来源:公众号 我爱计算机视觉 授权
点击上方↑↑↑“OpenCV学堂”关注我
来源:公众号 我爱计算机视觉 授权
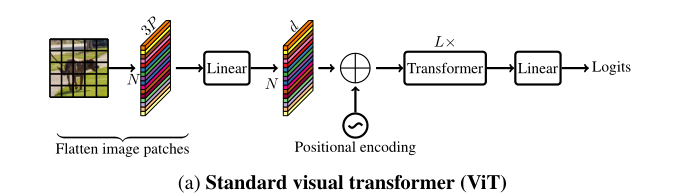
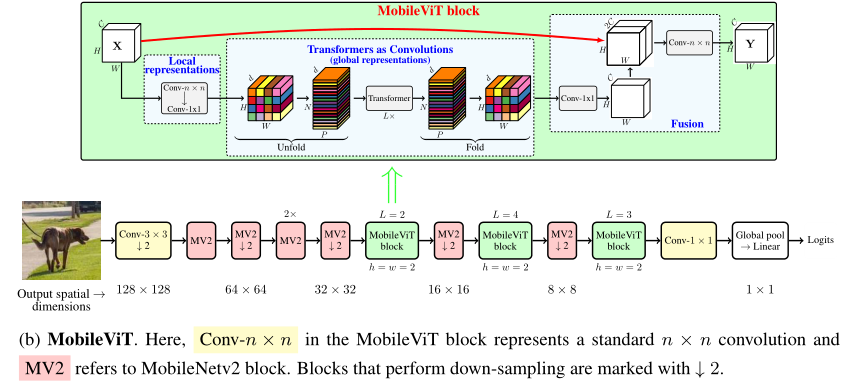
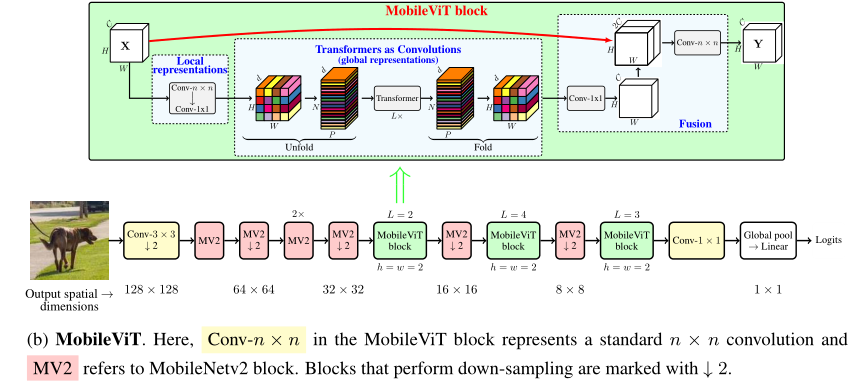
论文链接:https://arxiv.org/abs/2110.02178
复现代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch
01
02
03
04