
来源 | 焉知智能汽车
智库 | 云脑智库(CloudBrain-TT)
云圈 | 进“云脑智库微信群”,请加微信:15881101905,备注研究方向
假设你想捉摸老板每天的心情是好是坏,以此选择一个合适的汇报时机。你每天中午都会和老板一起吃食堂,而食堂午餐只能从川菜、粤菜、东北菜和淮扬菜四种中选择一种。你感觉老板每天心情和午餐吃什么有关系,想通过观测老板每天选择的午餐来猜测他每天心情的好坏。
接下来我们聊聊如何利用隐马尔科夫模型(HMM)来处理这个问题。
讲隐马尔科夫模型之前先介绍马尔科夫模型。
马尔科夫模型是指序列中的任何一个随机变量的概率分布仅与其上一个变量有关,与更早的变量无关。
说人话就是假设老板是个善忘的人,他今天心情的好坏只与昨天心情好坏有关,与前天及再早前的心情无关。
设老板第n天的心情为xn,那么老板N天以来的心情概率分布p可以简化为:
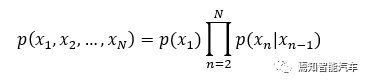
老板心情隐藏在心底,只有每天中午吃什么可以被我们观测。我们称为老板心情为隐变量,每天午餐选择的菜系为观测变量。使用隐马尔科夫模型时,有两个重要的假设:
(1)齐次马尔科夫性假设,隐变量具有马尔科夫性,即老板当天心情只与昨天心情有关。
(2)观测独立性假设,观测只和当前时刻状态有关,即老板当天选什么午餐只和当天心情有关。
设老板第n天的午餐选择为zn,那么满足这两个假设的隐马尔科夫模型可以如下图表示,
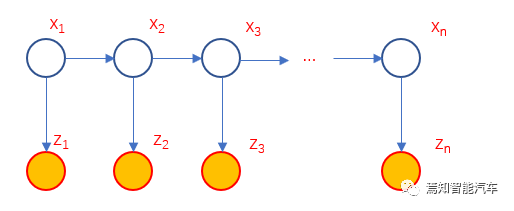
而其公式表达为:
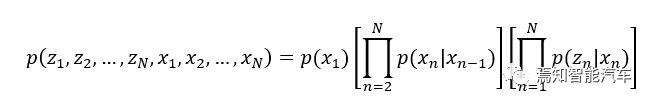
这个复杂的公式指的是N天以来,老板的心情序列(隐变量)分别为,以及每天中午选菜序列(观测变量)分别为的概率可以由等号右边的三部分的乘积来计算。这三部分分别是:
(1)初始概率模型,即,对应老板第一天心情的概率。假设可以有M种可能的状态,那么初始概率可以表示为1*M的概率矩阵。在我们的例子中M=2,这个向量的两个元素分别对应老板第一天心情好的概率和坏的概率。
(2) 转移概率模型,即公式中等号右边的第一套中括号内的乘积,对应老板每天心情转移的概率,亦即上面图片中上面一行状态从左往右的过程。假设可以有M种可能的状态,那么转移概率矩阵A的大小为M*M,表示为:
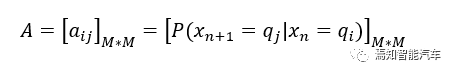
该矩阵中第i行第j列的元素对应的是第n天隐变量为时,第n+1天隐变量转移的条件概率。说人话就是第n天老板心情时的前提下,下一天老板心情变为的概率。
在我们的例子中,只有好和坏两种状态,M=2。那么转移概率矩阵就是一个2*2的矩阵,四个元素分别对应老板心情今好明好、今好明坏、今坏明好、今坏明坏的概率。
(3)发射概率模型,即公式中等号右边的第二套中括号内的乘积,对应老板每天心情和中午选菜的概率,亦即上面图片中每次上面一行状态从上往下跳转到下面一行的过程。假设观测变量有T种状态,那么发射概率矩阵B的大小为M*T,表示为:
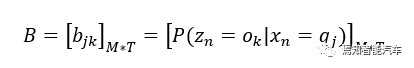
该矩阵中第j行第k列的元素对应的是第n天隐变量为时,观测变量为的概率。说人话就是第n天老板心情为时,他选择午餐为的概率。
在我们例子中,有川菜、粤菜、东北菜和淮扬菜四种状态,T=4。那么发射概率矩阵就是一个2*4的矩阵。矩阵每个元素分别对应老板当天心情好或者坏时,分别选择每种菜系当午餐的概率。
通过转移概率和发射概率的分拆,具有马尔科夫性的只有隐变量,而观测变量之间不再具有马尔科夫性,这其实刚好对应之前说的模型假设。这也是它为什么叫“隐马尔科夫模型”的原因,具有马尔科夫性的变量是“隐藏”起来的不被观测的变量。而观测变量通过每个时刻都独立地与隐变量关联,实际上也将观测变量与之前的历史状态关联起来了。这就是“隐马尔科夫”的厉害之处。
隐马尔科夫模型可以用来解决三大问题:
(1)第一种是计算概率:已知整个模型和观测序列,计算出现该观测序列的概率。说人话就是已知模型和参数,而且已经观察到上一周老板每天中午都吃了什么菜系,推算老板一周里选择这种菜系的概率。
(2)第二种是学习问题:已知观测序列和模型,调整模型参数使出现观测序列的概率最大。说人话就是,已经建好模型而且观察到老板上一周吃了什么,通过调参优化模型。
(3)第三种是预测问题:已知整个模型和观测序列,推算隐状态序列。说人话就是按照模型参数推算老板的心情。
回到我们开头的生活中的例子,利用隐马尔科夫模型推算老板心情,大致需要进行以下步骤:
(1)建立公用的隐马尔科夫模型
(2)隐马尔科夫模型初始参数确定
(3)初始模型参数训练,直到模型收敛为止
(4)将观察到的老板的历史午餐选择序列代入(3)中得到的模型参数进行训练,使用迭代方法调整模型参数达到最优
(5)利用(4)中优化的模型和参数,根据老板今天中午吃什么菜系,推算老板今天心情是好是坏。
第(1)步实际上就是对应这一章节介绍的数据建模。对(2)到(5)步,下面以Python的Hmmlearn为例,进一步学习马尔科夫模型。
Hmmlearn的安装很简单,"pipinstall hmmlearn"即可完成。
Hmmlearn实现了三种隐马尔科夫模型类,按照观测状态是连续状态还是离散状态,可以分为两类。GaussianHMM和GMMHMM是连续观测状态的模型,而MultinomialHMM是离散观测状态的模型。针对本文开头的例子,我们采用离散的MultinomialHMM。
(1)导入MultinomialHMM并定义变量:

(2)用MultinomialHMM建模。其函数的变量n_components是隐状态的数量,变量n_iter是最大的迭代次数,tol是收敛阈值。

(3)与其他机器学习类似,隐马尔科夫模型的训练也分为监督学习和非监督学习。监督学习是指学习样本包含观测序列和隐状态序列,非监督是指样本只有观测序列。
说人话就是如果除了观察老板每天午餐,你还能通过其他同事获知过往老板的实际心情,那么就可以用监督学习。否则只知道老板每天午餐选择,但无从确认过往老板实际心情的,就用非监督学习。实际应用中,监督学习往往需要更多的数据标注量,建议优先选择非监督。这里Python例子也是选用非监督。


(4)用MultinomialHMM的decode函数来推测老板的心情。这里采用的预测算法是Viterbi算法,本文不详细展开。简单来说,该算法就是用动态规划解概率最大路径,即在每个时刻递推计算每个状态转移的最大概率路径,递推到终点后再回溯最大概率路径的每个状态。
说人话就是每天推算时,只基于昨天推算出来的老板心情好坏的概率以及今天老板吃了什么午餐来推算老板今天的心情。当天算出来的不是最大概率的其他路径就把它们忘记(删除)掉。如此类推,到按照最后一天的老板午餐就可以推算出老板心情,而且往前的心情历史路径也只会剩下一条。当然不用Viterbi算法,也可以暴力计算所有路径找出概率最大的,但对样本数量多的情况来说明显效率更低。
假设前6天老板午餐分别是(川,川,粤,东北,淮,粤),今天午餐老板选了粤菜。那么模型推算出来这7天老板的心情就是[坏, 坏, 好, 好, 坏, 好, 好]。当然初始


当然本文的实例只是方便初学者理解,隐状态只是一阶的马尔科夫链,观测状态也是离散的,实际问题往往更复杂。例如老板今天的心情可能和之前的M天的心情都有关,这种就对应M阶马尔科夫模型。观测序列也可能是连续的,比如方向盘转角。
实际上隐马尔可夫模型可以有更高阶的建模,结合其他数据处理方法,拓展到智能汽车,还可以用于很多方面,例如:
参考来源:
Hidden Markov ModelsFundamentals,http://cs229.stanford.edu/section/cs229-hmm.pdf
https://hmmlearn.readthedocs.io/en/latest/api.html#hmmlearn-base
- The End -
声明:欢迎转发本号原创内容,转载和摘编需经本号授权并标注原作者和信息来源为云脑智库。本公众号目前所载内容为本公众号原创、网络转载或根据非密公开性信息资料编辑整理,相关内容仅供参考及学习交流使用。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请跟我们联系。我们致力于保护作者知识产权或作品版权,本公众号所载内容的知识产权或作品版权归原作者所有。本公众号拥有对此声明的最终解释权。
投稿/招聘/推广/合作/入群/赞助 请加微信:15881101905,备注关键词

微群关键词:天线、射频微波、雷达通信电子战、芯片半导体、信号处理、软件无线电、测试制造、相控阵、EDA仿真、通导遥、学术前沿、知识服务、合作投资.
“阅读是一种习惯,分享是一种美德,我们是一群专业、有态度的知识传播者.”
↓↓↓ 戳“阅读原文”,加入“知识星球”,发现更多精彩内容.
/// 先别走,安排点个“赞”和“在看” 吧!↓↓↓
