
正则表达式可以说是软件开发中最常用的功能之一。本文将以C++语言为例,介绍其中的正则表达式相关知识。
当你想要判断许多字符串是否符合某个特定格式;当你想在一大段文本中查找出所有的日期和时间;当你想要修改大量日志中所有的时间格式,在这些情况下,正则表达式都能帮上忙。
简单来说,正则表达式描述了一系列规则,通过这些规则,可以在字符串中找到相关的内容,规则使得搜索的能力更加强大。匹配的过程由正则表达式引擎完成。开发者通常不需要关心正则表达式引擎的实现细节,直接使用其提供的能力即可。
正则表达式非常的常用,但真正精通它的人却不多。本文试图给大家讲解一些对于C++语言使用正则表达式的基础知识。
本文中所贴出的代码示例可以到我的Github上获取:paulQuei/cpp-regex[1]。
或者,你也可以直接通过下面这条命令获取所有源码:
git clone https://github.com/paulQuei/cpp-regex.git
C++中正则表达式的API基本上都位于头文件中。
为了简化书写,本文中给出的代码都已经默认做了以下操作:
#include <iostream>
#include <regex>
using namespace std;
为了使大家有一个直观的感受,文章的开头先通过一些入门示例给大家一个直观的感受。在这个基础之上,再详细讲解其中的细节。
使用正则表达式的大致流程如下:首先你有一段需要处理的文本。这可能是一个字符串对象,也可能是一个文本文件,或者是一大堆日志。接下来你会有特定的目标,例如:找出文本中所有的时间和日期。这个时候你就需要根据可能的格式写出具体的正则表达式,例如,日期的格式是:2020-01-01,那么你的正则表达式可能是这样:\d{4}-\d{2}-\d{2}。(你现在不必纠结与这个正则表达式是什么意思,因为这是本文接下来要讲解的内容。)
有了正则表达式之后,你需要将你的文本和正则表达式交给正则表达式引擎 – 由C++语言(或者其他语言)提供。引擎会在文本中搜索到匹配的结果。这个结果的格式可能是包含了多个组,例如:你可能需要分离出年份和月份。有了引擎返回的结果之后,你就可以进一步处理了。
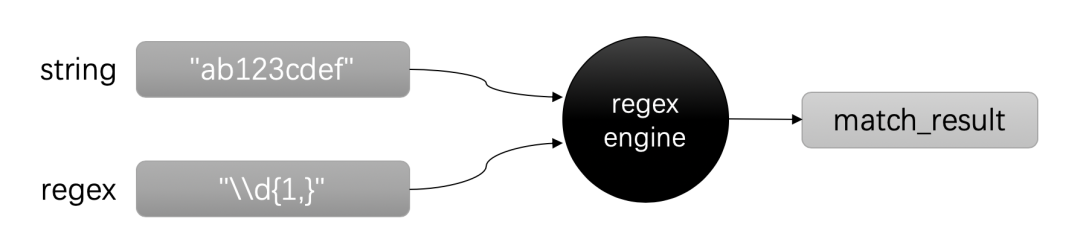
使用正则表达式的流程大体都是一致的,下面是最常见的三种使用方式。
匹配是判断给定的字符串是否符合某个正则表达式。例如:你想判断当前文本是否全部由数字构成。
下面是一段代码示例:
string s1 = "ab123cdef"; // ①
string s2 = "123456789"; // ②
regex ex("\\d+"); // ③
cout << s1 << " is all digit: " << regex_match(s1, ex) << endl; // ④
cout << s2 << " is all digit: " << regex_match(s2, ex) << endl; // ⑤
在这段代码中:
regex_match判断第一个字符串是否匹配,这里将返回falseregex_match判断第二个字符串是否匹配,这里将返回true这段代码输出如下:
ab123cdef is all digit: 0
123456789 is all digit: 1
请注意,正则表达式有它自身的语法。这与C++的语法是两回事。C++编译器只会检查C++代码的语法。因此,即便你的代码通过了C++编译器的语法检查,但在运行的时候,由于正则表达式的语义,还可能出现正则表达式的错误。正则表达式的错看起来类似这样:
terminating with uncaught exception of type std::__1::regex_error: The expression contained an invalid escaped character, or a trailing escape.。
还有一些时候,我们要判断的并非是文本的全体是否匹配。而是在一大段文本中搜索匹配的目标。
下面是一段代码示例,这段示例演示了在一个字符串中查找数字:
string s = "ab123cdef"; // ①
regex ex("\\d+"); // ②
smatch match; // ③
regex_search(s, match, ex); // ④
cout << s << " contains digit: " << match[0] << endl; // ⑤
std::smatch来保存匹配的结果。除了std::smatch,还有std::cmatch也很常用。前者是以std::string的形式返回结果,后者是以const char*的形式返回结果。regex_search函数搜索结果这段代码输出如下:
ab123cdef contains digit: 123
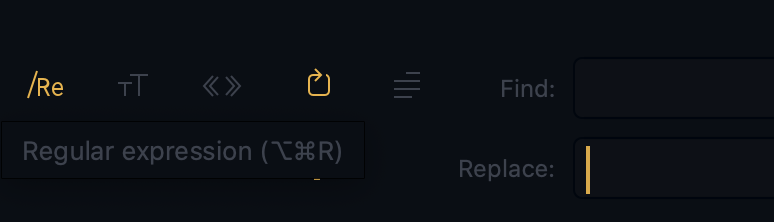
最后,使用正则表达式的还有一个常见功能是文本替换。很多的编辑器都有这样的功能。
例如,下图是我的Sublime编译器,在搜索替换文本的时候,可以使用正则表达式,这时搜索的能力就更加强大了。“Find:”部分可以通过正则表达式来描述待替换的字符串,“Replace:”部分填写替换的字符串。
下面是在C++中使用正则表达式完成字符串替换的代码示例:
string s = "ab123cdef"; // ①
regex ex("\\d+"); // ②
string r = regex_replace(s, ex, "xxx"); // ③
cout << r << endl; // ④
regex_replace完成替换cout输出结果最终输出的字符串如下:
abxxxcdef
通过上面的三个示例我们看到,regex_match,regex_search和regex_replace三个函数是正则表达式的核心,它们会运行正则表达式引擎完成匹配,查找和替换任务。
C++中内置了多种正则表达式文法,在创建正则表达式的时候可以通过参数来选择。
它们如下表所示:
| 文法 | 说明 |
|---|---|
| ECMAScript | ECMAScript正则表达式语法[2],默认选项 |
| basic | 基础POSIX正则表达式语法[3] |
| extended | 扩展POSIX正则表达式语法[4] |
| awk | awk工具的正则表达式语法[5] |
| grep | grep工具的正则表达式语法[6] |
| egrep | grep工具的正则表达式语法[7] |
不同的文法在表达上有一些不同,如果你原先已经很熟悉awk或者egrep文法的正则表达式,你可以直接使用它们。对于其他人来说,我们直接使用默认的ECMAScript文法即可(Javascript的正则表达式也是使用ECMAScript文法)。
grep的全称是Global Regular Expression Print。这个名字是在提示我们,它本身与正则表达式的历史有着特定的联系。
C++ 中的 ECMAScript 正则表达式文法是 ECMA-262 文法[8],你可以点击链接查看详细内容。
下文中,我们仅会讲解该标准下的正则表达式。
在代码中写字符串有时候是比较麻烦的,因为很多字符需要通过反斜杠转义。当有多个反斜杠连在一起时,就很容易写错或者理解错了。
当通过字符串来写正则表达式时,这个问题就更严重了。因为正则表达式本身也有一些字符需要转义。例如,对于这样一个字符串 "('(?:[^\\\\']|\\\\.)*'|\"(?:[^\\\\\"]|\\\\.)*\")|" 大部分人恐怕很难一眼看出其含义了。
在正则表达式很复杂的时候,推荐大家使用Raw string literal来表达。这种表达式是告诉编译器:这里的内容是纯字符串,因此不再需要增加反斜杠来转义特殊字符。
Raw string literal的格式如下:
R"delimiter(raw_characters)delimiter"
这其中:
也就是说,R"(content)"中的content是你需要的字符串本身。
下面是一个代码示例:
string s = R"("\w\\w\\\w)";cout << s << endl;
它将输出:
"\w\\w\\\w
可以看到,这里的双引号和反斜杠不会被解释成转义字符,而是当成字符串内容本身,因此会原样输出。这样就减少了转义字符的复杂度,于是更容易理解了。
正则表达式本身定义了一些特殊的字符,这些字符有着特殊的含义。它们如下表所示。
| 字符 | 说明 |
|---|---|
| . | 匹配任意字符 |
| [ | 字符类的开始 |
| ] | 字符类的结束 |
| { | 量词重复数开始 |
| } | 量词重复数结束 |
| ( | 分组开始 |
| ) | 分组结束 |
| \ | 转义字符 |
| \ | 转义字符自身 |
| * | 量词,0个或者多个 |
| + | 量词,1个或者多个 |
| ? | 量词,0个或者1个 |
| | | 或 |
| ^ | 行开始;否定 |
| $ | 行结束 |
| \n | 换行 |
| \t | Tab符 |
| \xhh | hh表示两位十六进展表示的Unicode字符 |
| \xhhhh | hhhh表示四位十六进制表示的Unicode字符串 |
这些字符并不少,刚开始接触可能记不住,但随着下文的讲解,相信你会逐渐熟悉它们。
字符类,顾名思义:是对字符的分类。
例如:1234567890这些都属于数字字符类。除此之外,还有其他的分类,它们如下表所示:
| 字符类 | 简写 | 说明 |
|---|---|---|
| [[:alnum:]] | 字母和数字 | |
| [_[:alnum:]] | \w | 字母,数字以及下划线 |
| [^_[:alnum:]] | \W | 非字母,数字以及下划线 |
| [[:digit:]] | \d | 数字 |
| [^[:digit:]] | \D | 非数字 |
| [[:space:]] | \s | 空白字符 |
| [^[:space:]] | \S | 非空白字符 |
| [[:lower:]] | 小写字母 | |
| [[:upper:]] | 大写字母 | |
| [[:alpha:]] | 任意字母 | |
| [[:blank:]] | 非换行符的空白字符 | |
| [[:cntrl:]] | 控制字符 | |
| [[:graph:]] | 图形字符 | |
| [[:print:]] | 可打印字符 | |
| [[:punct:]] | 标点字符 | |
| [[:xdigit:]] | 十六进制的数字字符 |
这里我们可以看到:
[]作为标识,因此这两个字符是正则表达式的中的特殊字符。如果是想使用这两个字符本身,需要对它们进行转义。[]内部,通过[:xxx:]来描述字符类的名称。[]中可以通过^表示否定,即:字符类的反面。接下来我们看一个代码示例:
#include <iostream>
#include <regex>
using namespace std;
static void search_string(const string& str,
const regex& reg_ex) { // ①
for (string::size_type i = 0; i < str.size() - 1; i++) {
auto substr = str.substr(i, 1);
if (regex_match(substr, reg_ex)) {
cout << substr;
}
}
}
static void search_by_regex(const char* regex_s,
const string& s) { // ②
regex reg_ex(regex_s);
cout.width(12); // ③
cout << regex_s << ": \""; // ④
search_string(s, reg_ex); // ⑤
cout << "\"" << endl;
}
int main() {
string s("_AaBbCcDdEeFfGg12345 \t\n!@#$%"); // ⑥
search_by_regex("[[:alnum:]]", s); // ⑦
search_by_regex("\\w", s); // ⑧
search_by_regex(R"(\W)", s); // ⑨
search_by_regex("[[:digit:]]", s); // ⑩
search_by_regex("[^[:digit:]]", s); // ⑪
search_by_regex("[[:space:]]", s); // ⑫
search_by_regex("\\S", s); // ⑬
search_by_regex("[[:lower:]]", s); // ⑭
search_by_regex("[[:upper:]]", s);
search_by_regex("[[:alpha:]]", s); // ⑮
search_by_regex("[[:blank:]]", s); // ⑯
search_by_regex("[[:graph:]]", s); // ⑰
search_by_regex("[[:print:]]", s); // ⑱
search_by_regex("[[:punct:]]", s); // ⑲
search_by_regex("[[:xdigit:]]", s); // ⑳
return 0;
}
这段代码稍微有些长,但还是比较好理解的。
search_by_regex将调用search_string进行字符的匹配。cout.width(12); 是为了控制输出格式的缩进。search_string进行字符的匹配。[[:alnum:]]匹配字母和数字类字符。\w是[_[:alnum:]]的简写方式,它与字符数字的区别在与:它还包含了_。当通过字符串定义正则表达式时,反斜杠需要转义。R"(\W)"是一个Raw string literal,因此,这里的反斜杠不再需要转义。[[:digit:]]匹配数字类字符。[^[:digit:]]是非数字类正则表达式,它与⑩正好相反。[[:space:]]匹配空白类字符,该表达式将包含换行符。\S是非空白类字符类。[[:lower:]]小写字母,[[:upper:]]下一行是大写字母。[[:alpha:]]匹配所有字母字符。[[:blank:]]是空白字符类,它与[[:space:]]的区别是:它不包含换行符。[[:graph:]]是图形类字符。[[:print:]]是可打印字符。[[:punct:]]是标点符号字符。[[:xdigit:]]是十六进制的数字字符。该程序的输出如下:
[[:alnum:]]: "AaBbCcDdEeFfGg12345"
\w: "_AaBbCcDdEeFfGg12345"
\W: "
!@#$"
[[:digit:]]: "12345"
[^[:digit:]]: "_AaBbCcDdEeFfGg
!@#$"
[[:space:]]: "
"
\S: "_AaBbCcDdEeFfGg12345!@#$"
[[:lower:]]: "abcdefg"
[[:upper:]]: "ABCDEFG"
[[:alpha:]]: "AaBbCcDdEeFfGg"
[[:blank:]]: " "
[[:graph:]]: "_AaBbCcDdEeFfGg12345!@#$"
[[:print:]]: "_AaBbCcDdEeFfGg12345 !@#$"
[[:punct:]]: "_!@#$"
[[:xdigit:]]: "AaBbCcDdEeFf12345"
请仔细看一下这个输出,并确认与你的认知是否一致。这里的有些字符类包含了换行符,因此在输出的结果中也是换行的。
上面的示例中,我们一次只匹配了一个字符。这样做效率是很低的。
在很多时候,我们当然是想一次性匹配出一个完整的字符串。例如:一个手机号码。这种情况下,其实是多个数字字符的重复。
下面就是在正则表达式中描述重复的方式。它们通常跟在字符类的后面,描述该字符出现多次。
| 字符 | 说明 |
|---|---|
| {n} | 重复n次 |
| {n,} | 重复n或更多次 |
| {n,m} | 重复[n ~ m]次 |
| * | 重复0次或多次,等同于{0,} |
| + | 重复1次或多次,等同于{1,} |
| ? | 重复0次或1次,等同于{0,1} |
知道重复的方法之后,正则表达式的查找能力就更强大了。看一下下面这个代码示例:
#include <iostream>
#include <regex>
using namespace std;
static void search_by_regex(const char* regex_s,
const string& s) { // ①
regex reg_ex(regex_s);
smatch match_result; // ②
cout.width(14); // ③
if (regex_search(s, match_result, reg_ex)) { // ④
cout << regex_s << ": \"" << match_result[0] << "\"" << endl; // ⑤
}
}
int main() {
string s("_AaBbCcDdEeFfGg12345!@#$% \t"); // ⑥
search_by_regex("[[:alnum:]]{5}", s); // ⑦
search_by_regex("\\w{5,}", s); // ⑧
search_by_regex(R"(\W{3,5})", s); // ⑨
search_by_regex("[[:digit:]]*", s); // ⑩
search_by_regex(".+", s); // ⑪
search_by_regex("[[:lower:]]?", s); // ⑫
return 0;
}
在这段代码中:
match_result用来存储查找的结果。regex_search在字符串中查找匹配字符。[[:alnum:]]{5}是指:字符或者数字出现5次。\\w{5,}是指:字母,数字或者下划线出现5次或更多次。R"(\W{3,5})"是指:非字母,数字或者下划线出现3次到5次。[[:digit:]]*是指:数字出现任意多次。.+是指:任意字符出现至少1次。[[:lower:]]?是指:小写字母出现0次或者1次。该程序输出如下:
[[:alnum:]]{5}: "AaBbC"
\w{5,}: "_AaBbCcDdEeFfGg12345"
\W{3,5}: "!@#$%"
[[:digit:]]*: ""
.+: "_AaBbCcDdEeFfGg12345!@#$% "
[[:lower:]]?: ""
接下来我们会看到更多的示例。同时,也会看到C++正则表达式API的更多功能。
为了便于下文示例的讲解,我们以维基百科上对于正则表达式的介绍文本为基础。
A regular expression, regex or regexp ((sometimes called a rational expression)) is a sequence of characters that define a search pattern. Usually such patterns are used by string searching algorithms for “find” or “find and replace” operations on strings, or for input validation. It is a technique developed in theoretical computer science and formal language theory.
The concept arose in the 1950s when the American mathematician Stephen Cole Kleene formalized the description of a regular language. The concept came into common use with Unix text-processing utilities. Different syntaxes for writing regular expressions have existed since the 1980s, one being the POSIX standard and another, widely used, being the Perl syntax.
Regular expressions are used in search engines, search and replace dialogs of word processors and text editors, in text processing utilities such as sed and AWK and in lexical analysis. Many programming languages provide regex capabilities either built-in or via libraries.
我们将这段文字保存在名称为content.txt的文本文件中。下面几个示例会在这个文本上操作。
在上文中,为了从字符串中查找出所有匹配的字符,我们的做法是遍历原始字符串的每一个子字符串来进行查找,这样做很明显效率很低。更好的做法当然是使用迭代器。
正则表达式迭代器一共有四种,分别对应了是否是宽字符,是否是字符串类型:
| 类型 | 定义 |
|---|---|
| cregex_iterator | regex_iterator<const char*> |
| wcregex_iterator | regex_iterator<const wchar_t*> |
| sregex_iterator | regex_iteratorstd::string::const_iterator |
| wsregex_iterator | regex_iteratorstd::wstring::const_iterator |
在一大段文本中查找所有匹配的目标,这是一个非常常见的需求。而迭代器正好满足这一需求,它会依次返回它从文本中找到的匹配内容。
[[:alpha:]]字符类来表达,一个单词至少有一个字母,因此这个正则表达式可以写成:[[:alpha:]]+。然后借助迭代器便可以统计出总数量。代码示例如下:
#include <fstream>
#include <iostream>
#include <regex>
using namespace std;
int main() {
regex word_regex("[[:alpha:]]+"); // ①
ifstream file("./content.txt"); // ②
string line;
int word_count = 0;
while(getline(file, line)) { // ③
auto iter_begin = sregex_iterator(line.begin(),
line.end(),
word_regex); // ④
auto iter_end = sregex_iterator(); // ⑤
for (auto iter = iter_begin; iter != iter_end; iter++) { // ⑥
word_count++; // ⑦
// cout << iter->str() << endl; // ⑧
}
}
cout << "It contains " << word_count << " words" << endl; // ⑨
return 0;
}
这段代码的说明如下:
ifstream读取文本文件这段代码输出如下:
It contains 153 words
接下来的几个代码示例的主体结构和这里会很相似,我们总是先打开文本文件,然后读取每一行来进行处理。
前面的示例中我们已经看到,通过std::regex并传递字符串就可以构造正则表达式对象。实际上,除了std::regex,还有宽字符版本的std::wregex。它们都源自std::basic_regex
| 类型 | 定义 |
|---|---|
| regex | basic_regex |
| wregex | basic_regex<wchar_t> |
在创建正则表达式对象的时候,除了描述规则本身的字符串之外,还可以传递一个flag_type类型的参数,该参数的值定义在std::regex_constants::syntax_option_type中。它们中与“文法”[9]相关的已经在上文介绍过了。
剩下的还有几个说明如下:
| 值 | 效果 |
|---|---|
| icase | 以不考虑大小写进行字符匹配。 |
| nosubs | 进行匹配时,将所有被标记的子表达式 (expr) 当做非标记的子表达式 (?:expr) 。不将匹配存储于提供的 std::regex_match 结构中,且 mark_count() 为零 |
| optimize | 指示正则表达式引擎进行更快的匹配,带有令构造变慢的潜在开销。例如这可能表示将非确定 FSA 转换为确定 FSA 。 |
| collate | 形如 “[a-b]” 的字符范围将对本地环境敏感。 |
| multiline(C++17) | 若选择 ECMAScript 引擎,则指定^匹配行首,$应该匹配行尾。 |
这其中,第一个是我们最常用的。
[Rr]来匹配大写或者小写的R字母,但实际上,使用icase无疑会更方便。代码示例:
#include <fstream>
#include <iostream>
#include <regex>
using namespace std;
int main() {
regex word_regex("regular expressions?", regex::icase);
ifstream file("./content.txt");
string line;
while(getline(file, line)) {
auto iter_begin = sregex_iterator(line.begin(),
line.end(),
word_regex);
auto iter_end = sregex_iterator();
for (auto iter = iter_begin; iter != iter_end; iter++) {
cout << iter->str() << endl;
}
}
return 0;
}
这段代码与前面的结构是一样的,我们最需要关注的可能就是下面这一行:
regex word_regex("regular expressions?", regex::icase);
通过std::regex::icase我们指定了这个正则表达式是不区分大小写的。
另外还有一个值得注意的就是正则表达式末尾的...s?,它意味着单词可能是单数或者复数,因此结尾的“s”可以出现0次或者1次。
这段代码输出如下:
regular expression
regular expressions
Regular expressions
std::match_results用来存储匹配结果。与迭代器类似,匹配结果也有四种类型:
| 类型 | 定义 |
|---|---|
| std::cmatch | std::match_results<const char*> |
| std::wcmatch | std::match_results<const wchar_t*> |
| std::smatch | std::match_resultsstd::string::const_iterator |
| std::wsmatch | std::match_resultsstd::wstring::const_iterator |
当我们使用正则表达式时,我们的目标常常不单单是判断或者查找完整匹配的内容。而是需要捕获匹配结果中的子串。例如:我们不仅要匹配出日期,还要捕获日期中的年份,月份等信息。这个时候就要使用分组功能。
我们在介绍正则表达式特殊字符的时候,提到过圆括号(和)。它们的作用就是分组。当你在正则表达式中配对的使用圆括号时,就会形成一个分组,一个正则表达式中可以包含多个分组。分组通过编号0, 1, 2, …来区分。编号0的分组是匹配的整体,其他编号根据括号的顺序来确定。
这些分组最终可以在匹配完成之后,可以通过std::match_results的API来获取。这些API如下表所示:
| API | 说明 |
|---|---|
| empty | 检查匹配是否成功 |
| size | 返回完成建立的结果状态中的匹配数 |
| max_size | 返回子匹配的最大可能数量 |
| length | 返回特定分组的长度 |
| position | 分会特定分组首字符的位置 |
| str | 返回特定分组的字符序列 |
| operation[] | 返回指定的分组 |
| prefix | 返回目标序列起始和完整匹配起始之间的分组 |
| suffix | 返回完整匹配结果和目标序列结尾之间的分组 |
在C++中,分组叫做子匹配(sub_match)。std::sub_match[10] 这个类型只有一个默认构造函数,通常你不会主动创建它,而是使用std::match_results的接口来获取它的对象。
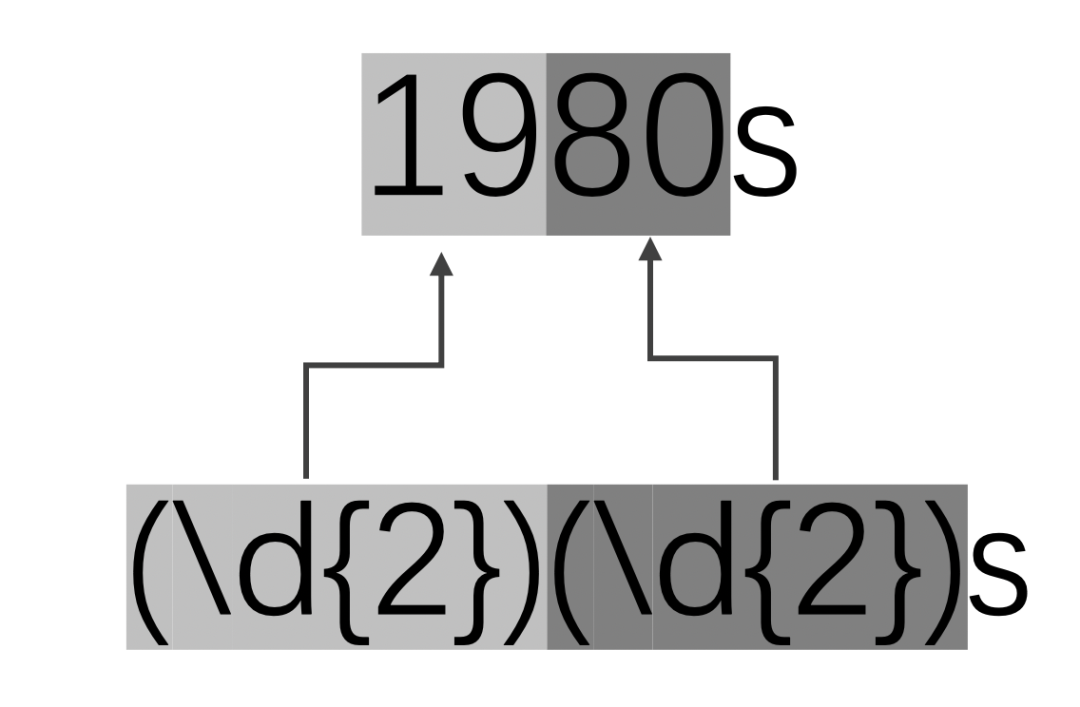
示例:查找出文本中所有的年代,并分离出世纪的部分和年份的部分。思路:年代的格式是四位数字加上“s”作为后缀。我们可以通过分组的形式分离出两个部分。图示如下:
代码示例:
#include <fstream>
#include <iostream>
#include <regex>
using namespace std;
int main() {
regex word_regex(R"((\d{2})(\d{2})s)"); // ①
ifstream file("./content.txt");
string line;
while(getline(file, line)) {
auto iter_begin = sregex_iterator(line.begin(),
line.end(),
word_regex);
auto iter_end = sregex_iterator();
for (auto iter = iter_begin; iter != iter_end; iter++) {
cout << "Match content: " << iter->str(0) << ", "; // ②
cout << "group Size: " << iter->size() << endl; // ③
cout << "Century: " << iter->str(1) << ", "; // ④
cout << "length: " << iter->length(1) << ", ";
cout << "position: " << iter->position(1) << endl;
auto year = (*iter)[2]; // ⑤
cout << "Year: " << year.str() << ", ";
cout << "length: " << year.length() << ", ";
cout << "position: " << iter->position(2) << endl;
cout << endl;
}
}
return 0;
}
这段代码说明如下:
sub_match这段代码输出如下:
Match content: 1950s, group Size: 3
Century: 19, length: 2, position: 25
Year: 50, length: 2, position: 27
Match content: 1980s, group Size: 3
Century: 19, length: 2, position: 277
Year: 80, length: 2, position: 279
前面的表格中[11],我们看到了正则表达式的特殊字符。但需要进一步说明的是,这些特殊字符在不同的环境可能有着不同的含义。
例如,特殊字符-只有在字符组[...]内部才是元字符,否则它只能匹配普通的连字符符号。并且,即便在字符组内部,如果连字符是在开头,它依然是一个普通字符而不是表示一个范围。
相反的,问号?和点号.不在字符组内部的时候才是特殊字符。因此[?.]中的这两个符号仅仅代表这两个字符自身。
还有,字符^出现在字符组中的时候表示的是否定,例如:[a-z]和[^a-z]表示的是正好相反的字符集。但是当字符^不是用在字符组中的时候,它是一个锚点[12],具体内容下文会说到。
还是以content.txt的内容为基础,现在假设我们的目标是:找出所有双引号中的内容。
根据之前的知识,你可能很轻松就写出了下面这个正则表达式:
regex content_regex("\"(.+)\"");
.+但是当你运行程序的时候却发现它可能有点问题。它捕获的结果是:
"find" or "find and replace"
为什么?其实很简单,因为双引号本身也可以与.匹配。上面这个正则表达式的含义是:匹配一个两端是双引号,中间是任意文字的内容。
当然,你马上想到一个改进方法那就是:将正则表达式圆括号中的.+改为[^"]+,它的含义是:一个或多个非双引号字符。这么做是可以的。但其实我们还有更好的做法。
我们再回头看一下原先的正则表达式,不考虑分组和转义,它可以写成:".+"。其实我们知道下面这三个字符串都是与其匹配的:
"find""find and replace""find" or "find and replace"而将整个文本交给正则表达式的时候,它找出了最长的那个串。可见,原先的正则表达式太过“贪婪”(greedy)。是的,量词在默认情况都是贪婪的。即:它们会尽可能多的占有内容。
那我们能不能控制量词让其尽可能少的占有内容,只要满足匹配要求就可以呢?
答案是肯定的,而且做法很简单:在量词的后面加上一个?。即,将圆括号中.+修改为.+?即可。量词的默认形式称之为“匹配优先量词”,现在这种写法称之为“忽略优先量词”。
现在它找到的是下面两个匹配:
"find"
"find and replace"
小结一下:
*,+,?,{num, num}*?,+?,??,{num, num}?锚点是一类特殊的标记,它们不会匹配任何文本内容,而是寻找特定的标记。你可以简单理解为它是原先表达式的基础上增加了新的匹配条件。如果条件不满足,则无法完成匹配。
锚点主要分为三种:
^,行/字符串的结束位置:$\b例如:
^\d+在字符串"123abc"中能找到匹配,在字符串"abc123"却找不到。some\b在字符串"some birds"中能找到匹配,在字符串"sometimes wonderful"中却找不到。下面是代码示例:
#include <iostream>
#include <regex>
using namespace std;
void findIn(const char* content, const char* reg_ex) {
cout << "Search '" << reg_ex << "' in '" << content << "': ";
smatch match;
string s(content);
regex reg(reg_ex);
if(regex_search(s, match, reg)) {
cout << match[0] << endl;
} else {
cout << "NOTHING" << endl;
}
}
int main() {
findIn("123abc", "^\\d+");
findIn("abc123", "^\\d+");
cout << endl;
findIn("some birds", "some\\b");
findIn("sometimes wonderful", "some\\b");
return 0;
}
它的输出如下:
Search '^\d+' in '123abc': 123
Search '^\d+' in 'abc123': NOTHING
Search 'some\b' in 'some birds': some
Search 'some\b' in 'sometimes wonderful': NOTHING
现在假设我们有下面两个需求:
对于第一个问题,我们可以分两步:先找出所有的单词sometimes,然后取前四个字符。对于第二个问题,我们可以先找出所有的单词“some”,然后把后面是“birds”的丢掉。
以上的解法都是分两步完成。但实际上,借助环视(lookaround)我们可以一步就完成任务。
环视是对匹配位置的附加条件,只有条件满足时才能完成匹配。环视有:顺序(向右),逆序(向左),肯定和否定一共四种:
| 类型 | 正则表达式 | 匹配条件 |
|---|---|---|
| 肯定顺序环视 | (?=...) | 子表达式能够匹配右侧文本 |
| 否定顺序环视 | (?!...) | 子表达式不能匹配右侧文本 |
| 肯定逆序环视 | (?<=...) | 子表达式能够匹配左侧文本 |
| 否定逆序环视 | (?<!...) | 子表达式不能匹配左侧文本 |
C++中的环视只支持顺序环视,不支持逆序环视。
环视说起来有些拗口,但看具体的例子就容易理解了:
#include <iostream>
#include <regex>
using namespace std;
void isMatch(const char* content, const char* reg_ex) {
cout << "Is '" << reg_ex << "' match '" << content << "': ";
smatch match;
string s(content);
regex reg(reg_ex);
if(regex_search(s, match, reg)) {
cout << "YES" << endl;
} else {
cout << "NO" << endl;
}
}
int main() {
isMatch("sometimes", "(?=sometimes)some");
isMatch("something", "(?=sometimes)some");
cout << endl;
isMatch("some eggs", "(?!some birds)some");
isMatch("some birds", "(?!some birds)some");
return 0;
}
这段代码并不复杂所以就不多做说明,它的输出结果如下:
Is 'sometimes' match '(?=sometimes)some': YES
Is 'something' match '(?=sometimes)some': NO
Is 'some eggs' match '(?!some birds)some': YES
Is 'some birds' match '(?!some birds)some': NO
对于包含环视的正则表达式来说,环视之外的内容是匹配的主体,环视本身只是一个附件条件。(?=sometimes)这个肯定顺序环视要求从这个位置开始,接下来的字符串必须是"sometimes"才能完成匹配。(?!some birds)这个否定顺序环视要是接下来的字符串一定不能是"some birds"才能完成匹配。
为了进一步帮助你理解,我们以图示的方式将(?=sometimes)some匹配"something"的过程描述出来。
图示中,虚线的上面是待匹配的文本,下面是正则表达式。对于环视,我们可以将其环视条件和主体分开来看。我们以一个下标三角箭头表示当前匹配的搜索位置。
刚开始的时候,搜索的位置是第一个字符的前面:

接下来,搜索位置往后走一个字符:

这个过程可以一直进行,直到匹配完"some":
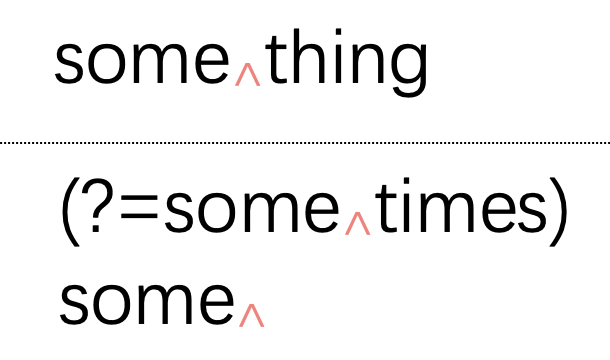
虽然正则表达式的主体"some"完成了匹配,但是接下来环视的条件却无法满足,于是匹配失败:

但是,如果要匹配内容正好是"sometimes",则条件是满足的,于是就完成了匹配。
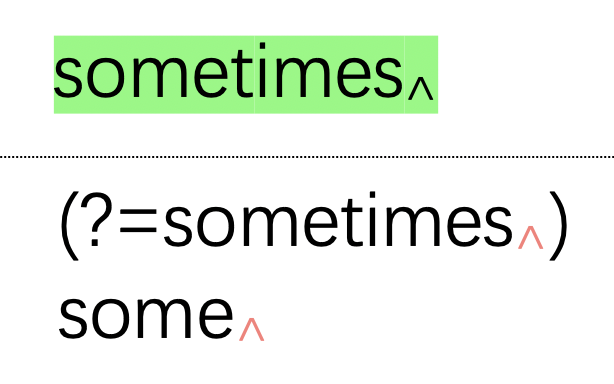
因为是入门的文章,所以本文中所举例的正则表达式都很简单。但实际应用的时候,我们常常会写出非常复杂的正则表达式。你可以点击这里浏览一些示例:Regular Expression Library[13]。
复杂的正则表达式常常很难理解,你可能需要借助工具来帮助分析,下面两个工具也许能帮上忙:
想要很好的掌握正则表达式,多使用多练习是最好的方法。想要深入学习正则表达式,Jeffrey E.F. Friedl的《精通正则表达式》[16]可能是最好的选择。
paulQuei/cpp-regex: https://github.com/paulQuei/cpp-regex
[2]ECMAScript正则表达式语法: https://en.cppreference.com/w/cpp/regex/ecmascript
[3]基础POSIX正则表达式语法: http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_03
[4]扩展POSIX正则表达式语法: http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_04
[5]awk工具的正则表达式语法: http://pubs.opengroup.org/onlinepubs/9699919799/utilities/awk.html#tag_20_06_13_04
[6]grep工具的正则表达式语法: https://www.gnu.org/software/findutils/manual/html_node/find_html/grep-regular-expression-syntax.html
[7]grep工具的正则表达式语法: https://www.gnu.org/software/findutils/manual/html_node/find_html/posix_002degrep-regular-expression-syntax.html#posix_002degrep-regular-expression-syntax
[8]ECMA-262 文法: http://ecma-international.org/ecma-262/5.1/#sec-15.10
[9]“文法”: https://paul.pub/cpp-regex/#id-文法
[10]std::sub_match: https://en.cppreference.com/w/cpp/regex/sub_match
[11]前面的表格中: https://paul.pub/cpp-regex/#id-特殊字符
[12]a-z]和[^a-z]表示的是正好相反的字符集。但是当字符^`不是用在字符组中的时候,它是一个[锚点: https://paul.pub/cpp-regex/#id-锚点
Regular Expression Library: http://regexlib.com/DisplayPatterns.aspx
[14]https://regex101.com: https://regex101.com/
[15]https://www.debuggex.com: https://www.debuggex.com/
[16]文章链接:https://paul.pub/cpp-regex/
1.25万研究所和40万996大厂去哪个?
2.单片机串口最底层的本质!
3.在MCU开发中如何充分利用各种类型的断点?(上)
4.在MCU开发中如何充分利用各种类型的断点?(下)
5.MCU在线调试功能正常而离线工作异常原因探究~
6.到底什么是“无源物联网”?

免责声明:本文系网络转载,版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将根据您提供的版权证明材料确认版权并支付稿酬或者删除内容。
