

在最近的Hot Chips大会上,IBM宣布了新的Z系列处理器主机。IBM Z以拥有大型L3缓存而闻名,同时拥有一个全局L4缓存芯片,服务于多个处理器。IBM全新Telum芯片不但取消了L4缓存,L3缓存也不见踪影。这一架构可能成为片上缓存设计的未来趋势。
缓存(cache)基础
任何现代处理器都有与之关联的多级缓存。这些缓存按容量、延迟和功率区分:最接近CPU的缓存速度最快、容量最小,离CPU远点的缓存容量变大、速度变慢,然后在进入主存之前可能还有一级更大的缓存。之所以设计缓存是因为CPU核心需要快速得到数据,如果所有数据都保存在DRAM中,那么每次取数据需要300多个周期。
一个现代CPU核心会提前预测需要什么数据,把这些数据从DRAM中取出,放到缓存中,然后当CPU需要数据的时候,可以更快地获取数据。一旦L1缓存线(cache line)被占用,该缓存线数据通常会被“驱逐”到L2缓存;如果L2缓存已满,L2中最古老的缓存线将被“驱逐”到L3缓存以腾出空间。这样如果CPU再次使用被移走的数据线,数据也不会离CPU太远。

从作用域上还区分私有和共享缓存。现代处理器设计有多个核,每个核至少有一个私有缓存(即L1 cache),只有该核才能访问。除此之外,一个缓存可以是某个核的私有缓存,也可以是所有核都可以使用的共享缓存。例如,Intel Coffee Lake处理器有8个核,每个核都有一个256kB的私有L2缓存;但在芯片范围内,所有核之间有一个16MB的共享L3缓存。这意味着,当某个核中L2数据想要被重用时,可以不断地将数据从较小的L2“驱逐”到较大的L3中。不仅如此,如果两个核需要共享一些数据,也可以通过共享的L3缓存实现。其实,“共享”缓存不一定在所有内核之间共享,也可能只在特定的几个内核之间共享。
权衡
既然缓存有助于减少执行时间,为什么处理器上没有1GB的L1或L2缓存?这里需要考虑多种因素,包括die面积、实用性和延迟。
首先是die面积——每个缓存结构在芯片上对应一块定义好的空间。设计芯片时,可能有一个最好的方法来放置核,以便获得最快的关键路径。但是缓存,尤其是L1缓存,必须靠近需要数据的地方;设计一个128KB的L1缓存和一个4KB的L1缓存的布局是非常不同的。除此之外,L2缓存有时占很大的die面积,虽然它通常不受核心设计其余部分的限制,但它仍然要与芯片需要保持平衡。任何大型共享缓存,无论是作为L2还是L3,通常都是芯片面积的大头。有时我们只关注核心中逻辑晶体管的密度,但对于超大缓存,也许缓存密度在最终使用的工艺节点中更为重要。
实用性也是一个关键因素:虽然我们主要谈论通用处理器,特别是那些为pc和服务器构建的x86处理器,或为智能手机和服务器构建的Arm处理器;但也有很多专用设计,用于特定的工作量或任务。如果处理器核心需要做的只是处理数据,例如一个摄像头AI引擎,那么工作负载就是一个定义良好的问题。这意味着可以对工作负载进行建模,并且可以优化缓存大小以获得最佳性能/功耗。如果缓存的目的是将数据接近核心,那么需要数据时缓存中的数据还没有准备好,被称为一个cache miss。任何CPU设计的目标是减少cache miss,以换取性能或功耗,所以用一个定义良好的工作量,核心可以围绕最佳性能/cache miss ratio所需的缓存构建。
延迟也是设计缓存大小的一个重要因素。缓存容量越大,访问所需的时间就越长;不仅因为缓存物理大小和到内核的距离,还因为需要搜索的缓存更多。例如,小的L1缓存可以在3个周期内访问数据,而大的L1缓存可能需要5个周期的延迟。一个小的L2缓存可以低至8个周期,而一个大的L2缓存可能需要19个周期。
一般情况下,如果缓存做得更大,延迟会更大,但缓存miss率会更低。这又回到了前面已定义工作负载的段落。我们看到,像AMD、英特尔、Arm等公司会对他们的大客户进行大量的工作量分析,以确定多大的cache工作效果最好,以及他们的核心设计应该如何发展。
IBM到底做了什么具有革命性的事情呢?
前面提到IBM Z是IBM的大型主机产品——也是业界的大拿。这些产品支撑着社会的关键要素,如基础设施和银行业。这些系统的停机时间每年以毫秒计,对于金融交易有大量的故障保险和故障转移;当系统运行时,必须保证所有数据库不发生故障,甚至在链上发生物理故障的情况下也是如此。
这就是IBM Z的切入点。它有很强的市场定位,同时有非常惊人的设计。
在上一代z15产品中,没有1个CPU 等同1个系统产品的概念。IBM Z的基本单位是5个处理器系统,使用两种不同类型的处理器。其中4个是计算处理器(CP),每个有12核和256MB共享L3缓存。这四个处理器分成两对,两对处理器连接到一个系统控制器(SC),系统控制器拥有960 MB的共享L4缓存,用于四个CP的数据。
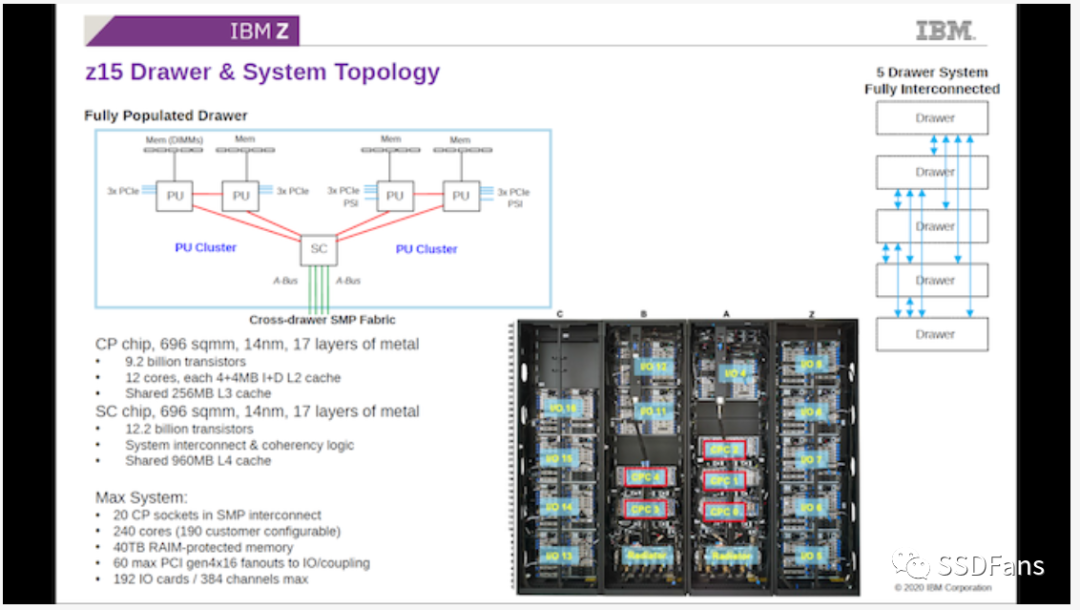
注意,这个系统没有一个“全局”DRAM,每个CP都有各自支持DDR的等效内存。IBM将这五个处理器作为一个组合,用五个组合组成一个系统。这意味着一个IBM z15系统有20 x 256 MB的L3缓存,同时也有5 x 960 MB的L4缓存,连接在一个all-to-all的拓扑结构中。
IBM z15是一头猛兽。但是下一代IBM Z,被称为IBM Telum而不是IBM z16,采用了完全不同的方法来处理所有缓存。
IBM怎么处理缓存
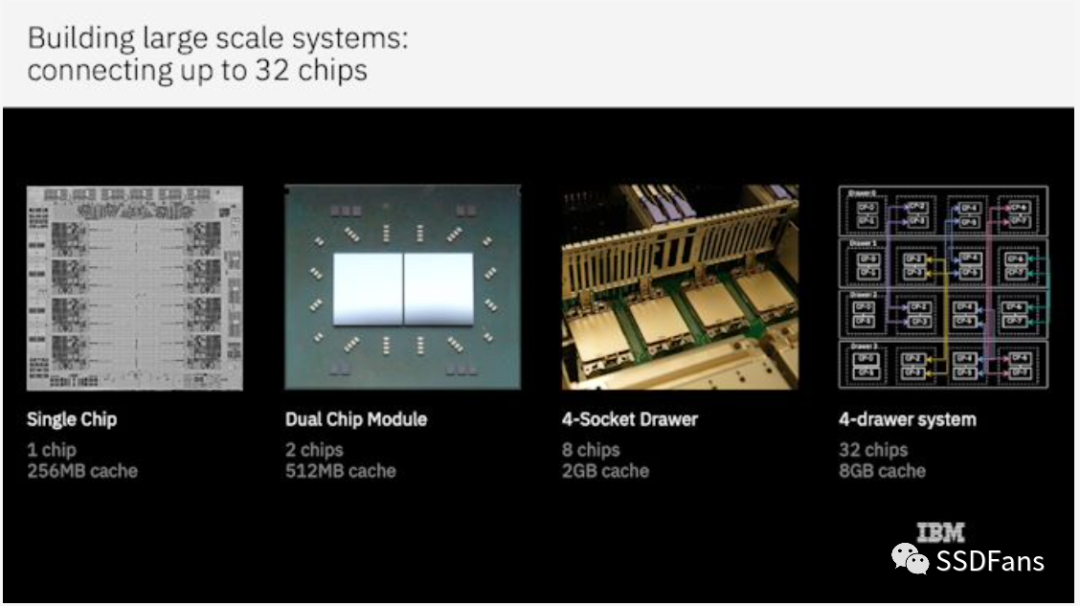
新系统去掉了包含L4缓存的系统控制器,看起来更像一个普通的8核处理器。IBM单个处理器芯片基于三星7nm工艺,两个处理器封装成一个模块,然后将四个模块(8个CPU, 64核)放到一个单元中。4个单元构成一个系统,总共32个CPU/ 256核。
在单个芯片上有8个核心。每个核心有32MB的私有L2缓存,访问延迟为19个周期。这对于L2缓存来说是很长的延迟,但它的缓存容量比Zen 3的L2大64倍,Zen 3延迟是12个周期。
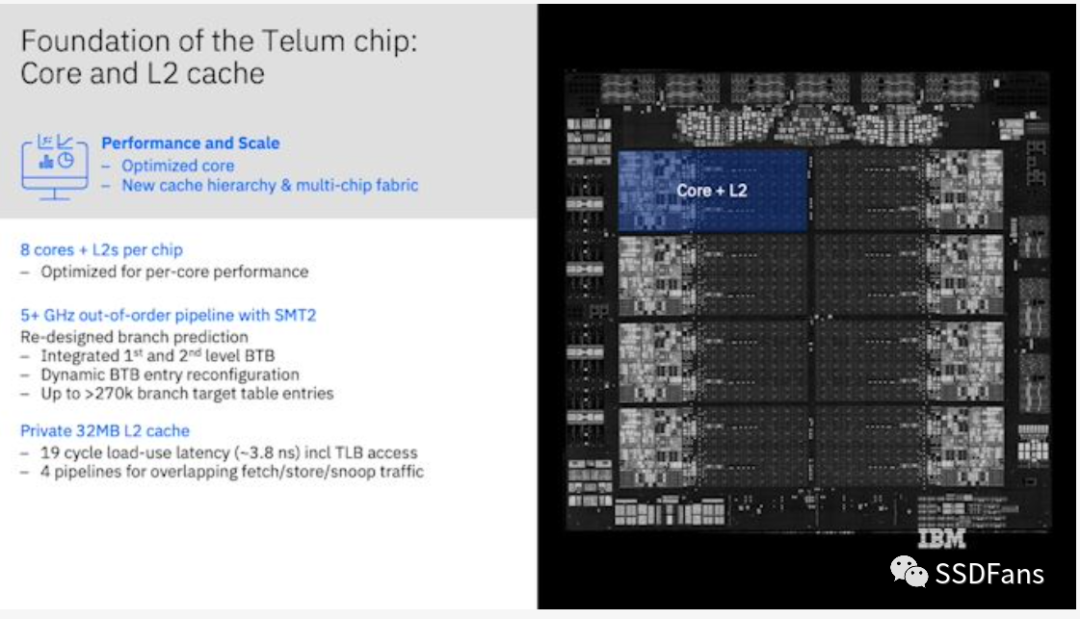
仔细看上图,可以发现所有中间的面积都是L2缓存;没有L3缓存,也没有物理共享的L3供所有内核访问。如果没有像z15那样的中央高速缓存芯片,意味着为了让需要一些共享数据的代码工作,将需要往返主存,这是很慢的。但是IBM已经想到了这一点。
这里L2缓存不仅仅是L2缓存。从表面上看,每个L2缓存确实是每个核心的私有缓存(32MB对于L2来说非常大);但是当需要从L2中移出缓存线时,不管是处理器故意的还是因为需要腾出空间,它都会试着在芯片的其他地方找到空间,而不是简单地消失。如果它在另一个核心的L2中找到了空间,它就会留在那里,并被标记为L3缓存线。
IBM在这里实现的是存在于私有物理缓存中的共享虚拟缓存的概念。这意味着L2缓存和L3缓存变成了相同的实体,同一个缓存可以根据需要包含来自不同内核的L2和L3缓存线。
这意味着整个芯片有8个私有32 MB L2缓存,也可以被认为有一个256 MB共享的“虚拟”L3缓存。在这个例子中,考虑如下等效:AMD的Zen 3芯片有8核和32 MB的L3缓存,每个核只有512 KB的私有L2缓存。如果它像IBM实现一个更大的L2/虚拟L3方案,最终每个核心会有4.5 MB的私有L2缓存,或者每个芯片拥有36 MB的共享虚拟L3缓存。
对于IBM Z,如果核心恰好需要在虚拟L3中的数据,而虚拟L3缓存线恰好是在其私有L2,那么19个周期的延迟会远低于共享物理L3缓存延迟 (大约55周期)。然而,更有可能的情况是,需要的虚拟L3缓存线在另一个核心的L2缓存中,IBM表示,这在其双向环互连上的平均延迟为12纳秒,带宽为320GB /s。12纳秒在5.2 GHz时约为62个周期,这将比物理L3缓存慢,但更大的L2意味着更小的L3使用压力。也因为L2和L3的大小灵活,容量较大,根据特定工作负载,整体延迟应该更低,工作负载范围也能有所增加。
继续深入
IBM Telum将两个芯片封装在一起,四个封装组成一个单元,四个单元组成一个系统,总共32个芯片、256核。IBM没有使用外部的L4缓存芯片,而是更进一步,使每个私有L2缓存也可以容纳相当于虚拟L4的缓存。
这意味着,如果从一个芯片上的虚拟L3中移除一条缓存线,它将在系统中找到另一个芯片,并将其标记为虚拟L4缓存线。
也就是说,从单一核心的角度来看,在256个核心系统中,它可以访问:
32 MB私有L2缓存(19周期延迟)
256MB片上共享虚拟L3缓存(+12ns延迟)
8192MB/8GB 片外共享虚拟L4缓存 (+?延迟)
严格来说,从单核的角度来看,这些数字应该是32MB / 224 MB / 7936MB,因为单核不会将L2线挤出到自己的L2中,并将其标记为L3。
IBM表示,使用这种虚拟缓存系统,每个核心的缓存比IBM z15多1.5倍,而且还减少了数据访问的平均延迟。IBM宣称每套socket的性能提高了>40%,目前还没有其他基准测试。
这怎么可能?
这简直是魔法。老实说,当第一次看到这个的时候,笔者有点惊讶于到底发生了什么。
在问答环节中,IBM Z的首席架构师ChristianJacobi博士表示,该系统的设计目的是在cache miss的情况下使用广播跟踪数据,并且在向外部芯片广播时跟踪存储状态位。这些数据会贯穿整个系统,当数据到达时,它会确保数据可以被使用,并在处理数据之前确认所有其他副本都已失效。
说实话,对于实际操作应该还有很多需要考虑的事项,如:功耗;缓存在闲置时是否下电;如果单个核心为保证性能一致性,不允许成为其他核心的虚拟缓存等。
说到缓存,不得不提到AMD即将推出的V-cache技术。该技术通过在chiplet上面添加一个垂直堆叠的64 MB L3,将每个chiplet设置为96 MB的L3缓存,而不是32 MB L3缓存。但是,如果这个堆叠的64 MB不是L3,而是考虑给每个核额外增加8 MB L2,并能够接受虚拟L3缓存线,这对性能意味着什么?
笔者与一些业内同行讨论了IBM的虚拟缓存想法,他们的评论从“它应该工作得不是很好”到“它很复杂”,以及“如果IBM能做到所说的那样,那就很酷了”。
原文链接:
https://www.anandtech.com/show/16924/did-ibm-just-preview-the-future-of-caches
高端微信群介绍 | |
创业投资群 | AI、IOT、芯片创始人、投资人、分析师、券商 |
闪存群 | 覆盖5000多位全球华人闪存、存储芯片精英 |
云计算群 | 全闪存、软件定义存储SDS、超融合等公有云和私有云讨论 |
AI芯片群 | 讨论AI芯片和GPU、FPGA、CPU异构计算 |
5G群 | 物联网、5G芯片讨论 |
第三代半导体群 | 氮化镓、碳化硅等化合物半导体讨论 |
存储芯片群 | DRAM、NAND、3D XPoint等各类存储介质和主控讨论 |
汽车电子群 | MCU、电源、传感器等汽车电子讨论 |
光电器件群 | 光通信、激光器、ToF、AR、VCSEL等光电器件讨论 |
渠道群 | 存储和芯片产品报价、行情、渠道、供应链 |

< 长按识别二维码添加好友 >
加入上述群聊

带你走进万物存储、万物智能、
万物互联信息革命新时代

