

特斯拉举办了2021人工智能日,并透露了他们的软件和硬件基础设施的内部运作,以及Dojo AI 训练芯片。特斯拉声称D1 Dojo 芯片具有 GPU 级别的计算能力、CPU 级别的灵活性,以及网络交换机 IO性能。推测该系统的封装是 TSMC 晶圆集成扇出系统 (InFO_SoW)。
下载链接:

我们解释了这种类型的封装的好处以及这种大规模扩展训练芯片所涉及的冷却和功耗。此外,估计该软件性能将优于 Nvidia 系统。今天,我们将深入解揭示该半导体的技术细节。

在开始之前,先来谈谈基础设施。特斯拉不断地训练和改进其神经网络。并且在汽车和服务器中部署了数以千计的相同训练芯片。
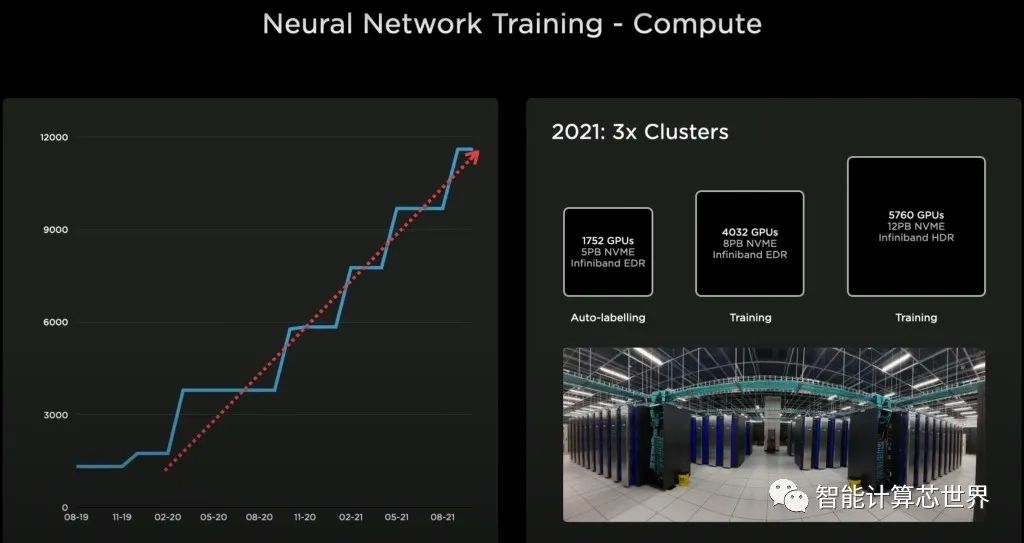
多年来,特斯拉一直在扩大其 GPU 集群的规模。如果特斯拉运行Linpack测试,并提交给了500强名单,则训练集群将是第5最大的超级计算机。但这种性能对于特斯拉和他们的雄心来说是不够的,所以几年前他们开始开发自己的芯片 Dojo 项目。Tesla 需要更高的性能,以节能且经济高效的方式启用更大、更复杂的神经网络。

Tesla 的架构解决方案采用分布式计算架构。这种架构似乎与 Cerberus 非常相似。每个 AI 训练架构都是以这种方式布局的,但计算元素、网络细节差异很大。这些类型网络的最大问题是带宽和低延迟。在更大的网络部署中,特斯拉特别关注后两者。这影响了他们设计的每个部分,从芯片到封装。

此外,他们还引入了一种称为 CFP8 的新数据类型,可配置浮点。每个单元能够在每个方向上实现 1TFlops BF16 或 CFP8、64GFlops FP32 和 512GB/s 的带宽。
CPU毫不逊色,每个内核可以支持4 个线程,最大限度地提高利用率。不幸的是,Tesla使用了定制的 ISA,而不是像 RISC V 这样的顶级开源 ISA。这个定制的 ISA 引入了转置、收集、广播和链接遍历的指令。
这354个功能单元的芯片达到BF16或CFP8的362 TFlops和FP32的22.6 TFlops。一共是500亿个晶体管。每个芯片都有惊人的 400W TDP。这意味着功率密度高于 Nvidia A100 GPU 的大多数配置。有趣的是,特斯拉实现了每 mm^2 7750 万个晶体管的有效晶体管密度。这比其他任何高性能芯片都要高,仅次于移动芯片和 Apple M1。
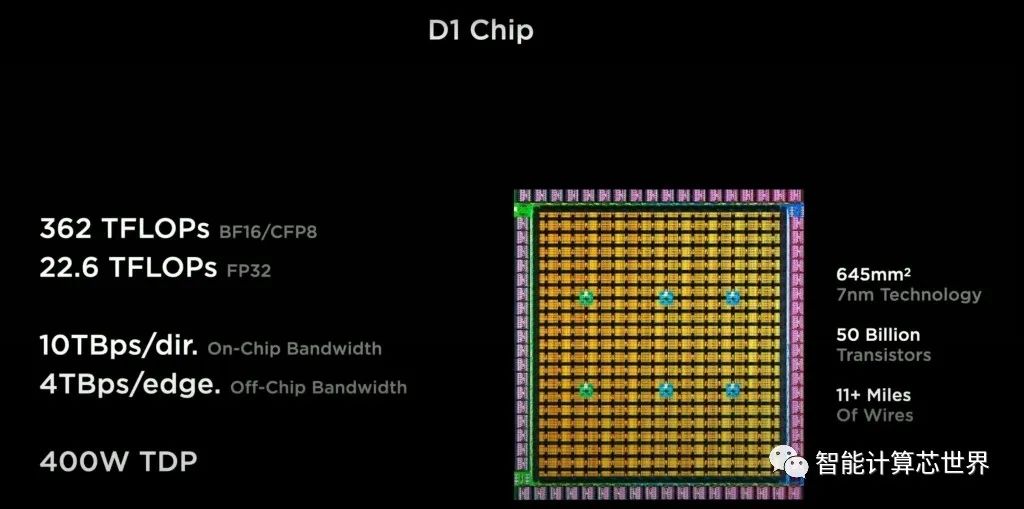
基本功能单元另一个有趣地方是 NOC 路由器。它以与 Tenstorrent 非常相似的方式支持芯片内和芯片间扩展。毫不奇怪,特斯拉采用与其人工智能初创公司类似的架构。Tenstorrent 非常适合训练能力扩展,而特斯拉非常关注这方面。
在芯片上,Tesla拥有惊人的10TBps定向带宽,但这个数字在实际工作负载中意义不大。与 Tenstorrent 相比,特斯拉的一大优势是芯片之间的带宽明显更高。576 个 SerDes提供64Tb/s 或 8TB/s 的带宽。
目前已知的最高外部带宽芯片是32Tb/s网络交换芯片。特斯拉能够通过大量的 SerDes 和先进的封装将这一点翻倍。
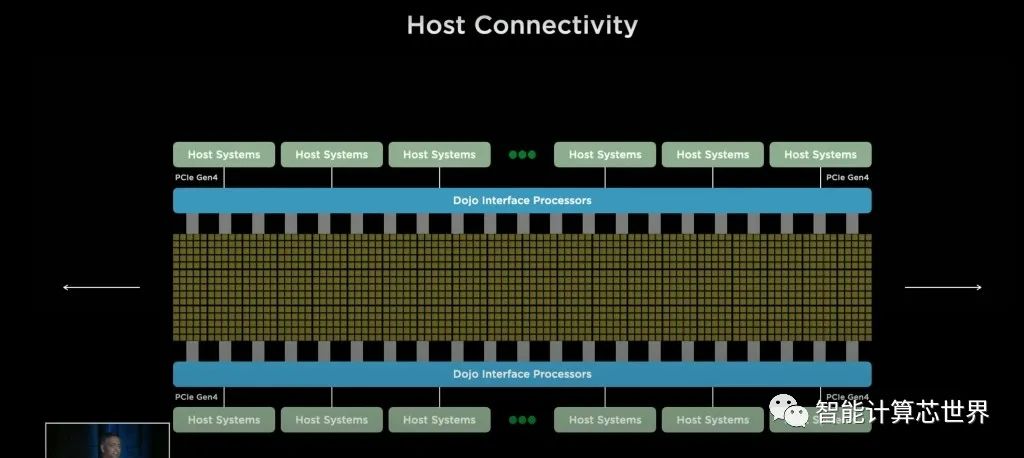
Tesla 将 Dojo 芯片的计算平面连接到接口处理器,这些处理器连接到具有 PCIe 4.0 的主机系统。这些接口处理器还支持更高基数的网络连接,以补充现有的计算平面网格。
25 个 D1 芯片被封装为一个称为训练瓦片的“扇出晶圆工艺”。特斯拉没有像我们几周前推测的那样确认这种封装是台积电的晶圆上集成扇出系统(InFO_SoW),但考虑到芯片间带宽他们特别提到扇出晶圆的事实,这似乎很有可能。

特斯拉开发了一种专有的高带宽连接器,可以保留这些片之间的片外带宽。每个Tile具有令人不可思议的 9 PFlops BF16/CFP8 和 36 TB/s 的片外带宽。这远远超过了 Cerebras 的晶圆外带宽,并使 Tesla 系统能够比 Tenstorrent 架构等更好地横向扩展。

面对大带宽和超过 10KW 的功耗,特斯拉在电力传输方面进行了创新并垂直供电。定制稳压器调制器直接回流到扇出晶片上。功率、热量和机械都直接与Tile连接。
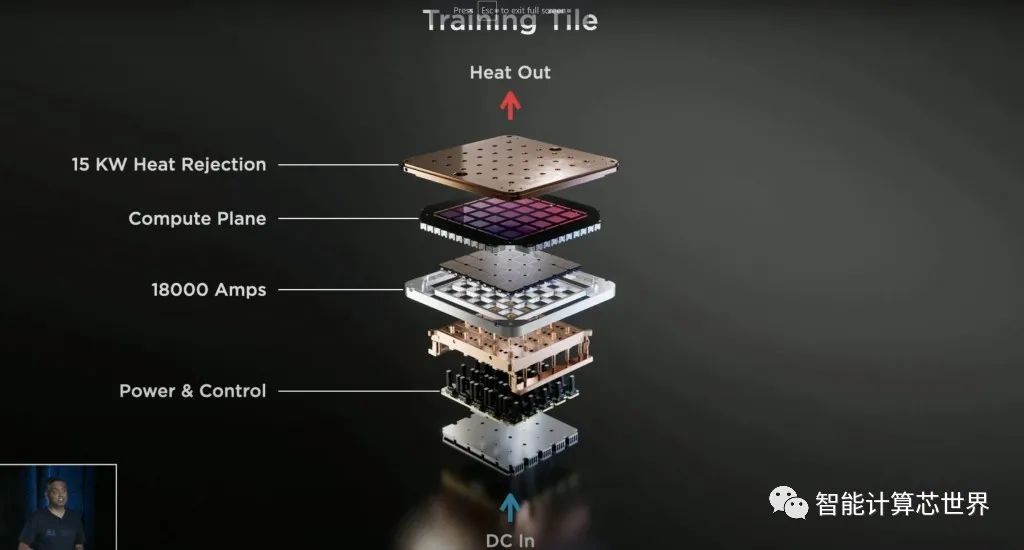
即使芯片本身的总功率仅为 10KW,但总功率似乎为 15KW。电力输送、IO 和晶圆也在消耗大量电力。功率从底部进来,而热量从顶部传出。该 tile 远远超过了Nvidia、Graphcore、Cerebras、Groq、Tenstorrent、SambaNova 或任何其他 AI 培训能力。

扩展能力在单服务器可以达到数千个芯片。Dojo 可扩展到 2 x 3Tiles配置,服务器机柜中有两种配置。每个柜子总共有12 Tiles ,每个柜子总共有 108 PFlops。每个服务器机柜超过 100,000 个功能单元、400,000 个自定义内核和 132GB SRAM。

特斯拉不断扩大其机柜数量,计划扩展到 10个机柜和 1.1 Exaflops。1,062,000 个功能单元、4,248,000 个内核和 1.33TB 的 SRAM。

软件方面很有趣,但我们今天不会深入研究它们。他们声称,无论集群大小如何,软件都可以在 Dojo 处理单元 (DPU) 之间无缝扩展。Dojo Compiler 可以处理跨硬件计算平面的细粒度并行处理和映射网络。
模型并行性可以跨芯片边界扩展,轻松解锁具有数万亿个参数甚至更多的 AI 模型级别。综合起来,成本与 Nvidia GPU 相当,Tesla 声称他们可以实现 4 倍的性能,每瓦性能提高 1.3 倍,占用空间减少 5 倍。
Tesla 的TCO 优势比英伟达 AI 解决方案高出近一个数量级。如果他们的说法属实,特斯拉在 AI 硬件和软件领域已经超越所有人。我持怀疑态度,但这也是硬件极客的梦想。
InFO_SoW 技术通过载体本身消除了基板和PCB的问题。紧凑型系统内紧密封装的多个芯片阵列使该解决方案能够获得晶圆级优势,例如低延迟芯片间通信、高带宽密度和低 PDN 阻抗,以实现更高的计算性能和电源效率。除了异构芯片集成之外,其晶圆现场处理能力还支持基于小芯片的设计,以实现更大的成本节约和设计灵活性。
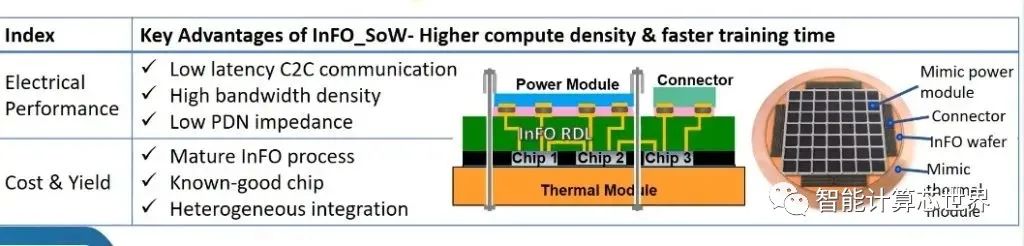
这突破了目前多芯片模块的壁垒。使用基于中介层的技术(例如 Nvidia 数据中心 GPU),它们会受到中介层制造限制的限制。台积电的第5代 CoWoS-S 最近投入量产,其中介层是光罩限制的 3 倍。掩模版的限制为 26 毫米 x 33 毫米,并且与光刻机在一个实例中可以图案化的最大面积有关。这种方法涉及掩模版拼接和其他制造困难,因为中介层本身就是一个硅芯片。这种类型的封装在为巨大的 AI 工作负载扩展芯片数量方面存在局限性。

另一种方法是倒装芯片封装。最著名的采用这种封装的 MCM 设计是 AMD CPU。它们不存在光罩限制问题,但在功率和线密度方面存在巨大缺陷。您在芯片间数据传输上消耗了更多的电量,并且芯片之间的带宽是有限的。由于这些限制,这种类型的包装不太适合巨大的 AI 工作负载。
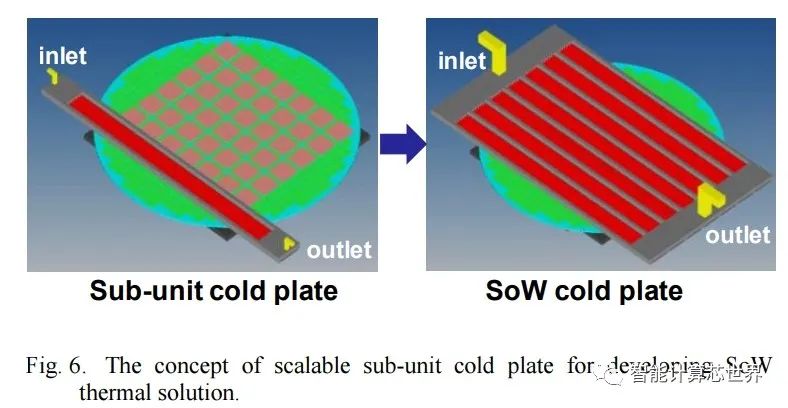
随着特斯拉希望在其 Dojo 超级计算机设计中实现的扩展,将会产生大量的热量。InFO_SoW 能够提供 7,000W 的功率。相比之下,Nvidia 的数据中心 A100 GPU 的配置高达 500W。这需要大量考虑冷却问题,而台积电 InFO_SoW 提供了解决方案。
https://semianalysis.com/tesla-dojo-ai-super-computer-unique-packaging-and-chip-design-allow-an-order-magnitude-advantage-over-competing-ai-hardware/
https://semianalysis.com/tesla-ai-day-supercomputer-chip-teaser-is-this-the-first-deployment-of-tsmc-info_sow/
下载链接:
干货揭秘:特斯拉AI Day再放大招
中国数据处理器行业概览(2021)
DPU在数据中心和边缘云上的应用
英伟达DPU集数据中心于芯片
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


