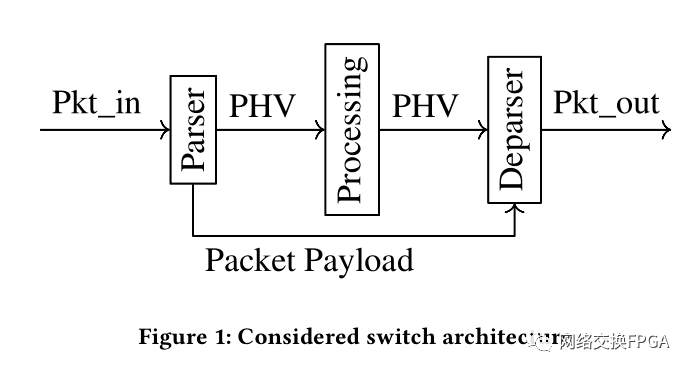
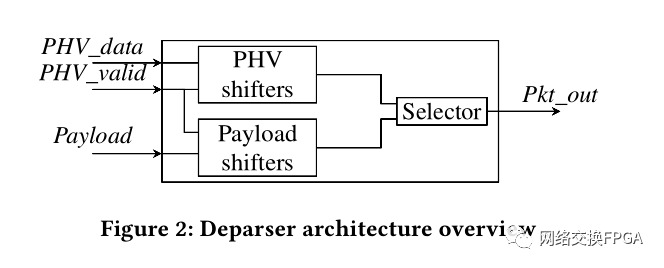
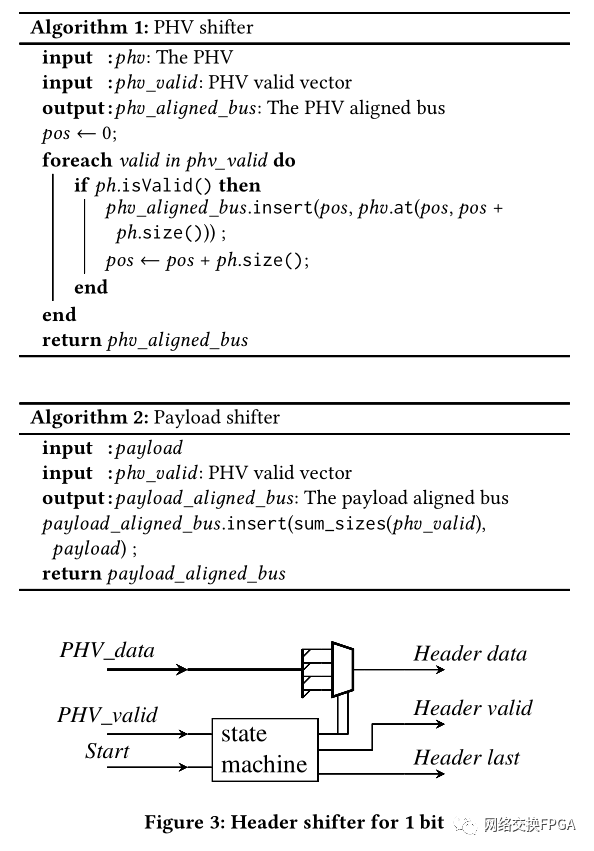
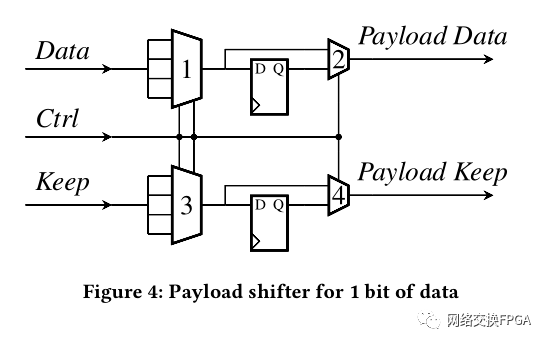
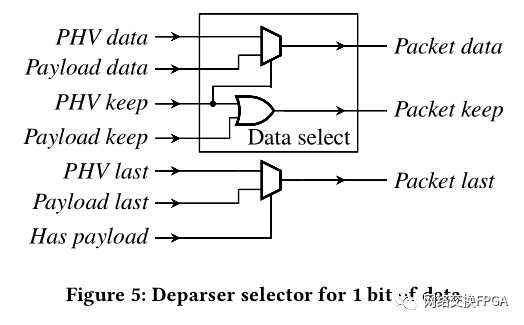
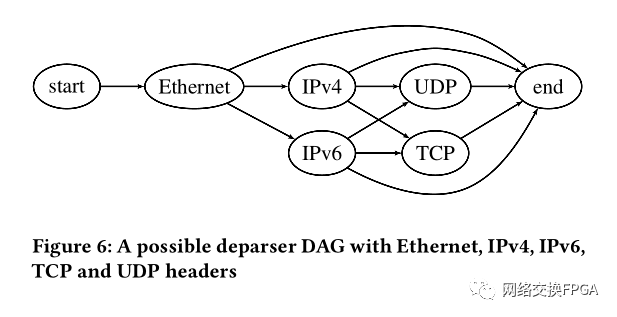
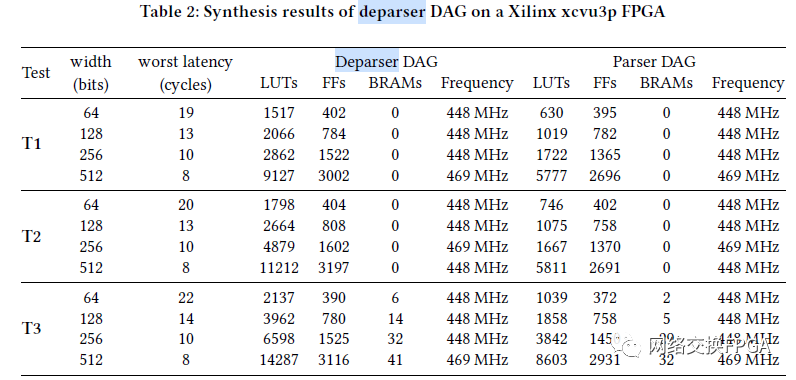
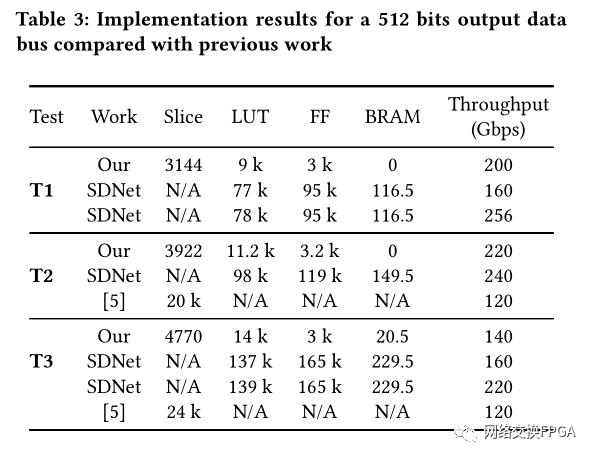
[1] M. S. Abdelfattah and V. Betz. 2012. Design tradeoffs for hard and soft FPGAbased Networks-on-Chip. In 2012 International Conference on Field-Programmable Technology. 95–103.
[2] AMBA. 2010. Axi4-stream protocol specification. Technical Report. ARM®.
[3] Michael Attig and Gordon Brebner. 2011. 400 Gb/s Programmable Packet Parsing on a Single FPGA. In Proceedings of the 2011 ACM/IEEE Seventh Symposium on Architectures for Networking and Communications Systems (ANCS ’11). IEEE Computer Society, Washington, DC, USA, 12–23. https://doi.org/10.1109/ANCS.2011.12
[4] P. Benácek, V. Pu, and H. Kubátová. 2016. P4-to-VHDL: Automatic Generation of 100 Gbps Packet Parsers. In 2016 IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM). 148–155.
[5] Pavel Benáček, Viktor Puš, Hana Kubátová, and Tomáš Čejka. 2018. P4-ToVHDL: Automatic generation of high-speed input and output network blocks.Microprocessors and Microsystems 56 (2018), 22 – 33. https://doi.org/10.1016/j.micpro.2017.10.012
[6] Pat Bosshart, Dan Daly, Glen Gibb, Martin Izzard, Nick McKeown, Jennifer Rexford, Cole Schlesinger, Dan Talayco, Amin Vahdat, George Varghese, and David Walker. 2014. P4: Programming Protocol-Independent Packet Processors.SIGCOMM Comput. Commun. Rev. 44, 3 (July 2014), 87–95. https://doi.org/10.1145/2656877.2656890
[7] J. Cabal, P. Benacek, J. Foltova, and J. Holub. 2019. Scalable P4 Deparser for Speeds Over 100 Gbps. In 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM). 323–323. https://doi.org/10.1109/FCCM.2019.00064
[8] A. M. Caulfield, E. S. Chung, A. Putnam, H. Angepat, J. Fowers, M. Haselman, S. Heil, M. Humphrey, P. Kaur, J. Kim, D. Lo, T. Massengill, K. Ovtcharov, M.Papamichael, L. Woods, S. Lanka, D. Chiou, and D. Burger. 2016. A cloud-scale acceleration architecture.In2016 49th Annual IEEE/ACM International Symposium on Microarchitecture(MICRO).1–13. https://doi.org/10.1109/MICRO.2016.7783710
[9] P4 Language Consortium. 2017. The P4 Language Specification, version 1.0.4.Technical Report. https://p4.org/p4-spec/p4-14/v1.0.4/tex/p4.pdf
[10] G. Gibb, G. Varghese, M. Horowitz, and N. McKeown. 2013. Design principles for packet parsers. In Architectures for Networking and Communications Systems.13–24.
[11] Chris Higgs and Stuart Hodgeson.2020. cocotb. https://github.com/cocotb/cocotb
[12] Chris Higgs and Stuart Hodgeson. 2020. Tutorial: Ping — cocotb 1.4.0 documentation. https://docs.cocotb.org/en/stable/ping_tun_tap.html
[13] Stephen Ibanez, Gordon Brebner, Nick McKeown, and Noa Zilberman. 2019. The P4->NetFPGA Workflow for Line-Rate Packet Processing. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’19). Association for Computing Machinery, New York, NY, USA, 1–9.https://doi.org/10.1145/3289602.3293924
[14] Stephen Ibanez, Gordon Brebner, Nick McKeown, and Noa Zilberman. 2019. The P4->NetFPGA Workflow for Line-Rate Packet Processing. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’19). Association for Computing Machinery, New York, NY, USA, 1–9.https://doi.org/10.1145/3289602.3293924
[15] J. W. Lockwood, N. McKeown, G. Watson, G. Gibb, P. Hartke, J. Naous, R. Raghuraman, and J. Luo. 2007. NetFPGA–An Open Platform for Gigabit-Rate Network Switching and Routing. In 2007 IEEE International Conference on Microelectronic Systems Education (MSE’07). 160–161.
[16] T. Luinaud, T. Stimpfling, J. S. da Silva, Y. Savaria, and J. M. P. Langlois. 2020.Bridging the Gap: FPGAs as Programmable Switches. In 2020 IEEE 21st International Conference on High Performance Switching and Routing (HPSR). 1–7.https://doi.org/10.1109/HPSR48589.2020.9098978
[17] p4Lang. 2020. behavioral-model: The reference P4 software switch. https://github.com/p4lang/behavioral-model
[18] p4lang. 2020. p4c: P4 16 reference compiler. https://github.com/p4lang/p4c
[19] Jeferson Santiago da Silva, François-Raymond Boyer, and J.M. Pierre Langlois.2018. P4-Compatible High-Level Synthesis of Low Latency 100 Gb/s Streaming Packet Parsers in FPGAs. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’18). Association for Computing Machinery,NewYork,NY,USA,147–152. https://doi.org/10.1145/3174243.3174270
[20] Yuta Tokusashi, Huynh Tu Dang, Fernando Pedone, Robert Soulé, and Noa Zilberman. 2019. The Case For In-Network Computing On Demand. In Proceedings of the Fourteenth EuroSys Conference 2019 (EuroSys ’19). Association for Computing Machinery, New York, NY, USA, Article 21, 16 pages. https: //doi.org/10.1145/3302424.3303979
[21] Han Wang, Robert Soulé, Huynh Tu Dang, Ki Suh Lee, Vishal Shrivastav, Nate Foster, and Hakim Weatherspoon. 2017. P4FPGA: A Rapid Prototyping Framework for P4. In Proceedings of the Symposium on SDN Research (SOSR ’17). Association for Computing Machinery, New York, NY, USA, 122–135.https://doi.org/10.1145/3050220.3050234
[22] Han Wang, Robert Soulé, Huynh Tu Dang, Ki Suh Lee, Vishal Shrivastav, Nate Foster, and Hakim Weatherspoon. 2017. P4FPGA: A Rapid Prototyping Framework for P4. In Proceedings of the Symposium on SDN Research (SOSR ’17). Association for Computing Machinery, New York, NY, USA, 122–135.https://doi.org/10.1145/3050220.3050234
[23] Xilinx ® . 2016. 7 Series FPGAs Configurable Logic Block. Technical Report. https:// www.xilinx.com/support/documentation/user_guides/ug474_7Series_CLB.pdf
[24] Xilinx ® . 2018. SDnet Development Environment. https://www.xilinx.com/ products/design-tools/software-zone/sdnet.html
[25] Peter Yiannacouras, Jonathan Rose, and J. Gregory Steffan. 2005. The Microarchitecture of FPGA-Based Soft Processors. In Proceedings of the 2005 International Conference on Compilers, Architectures and Synthesis for Embedded Systems (CASES ’05). Association for Computing Machinery, New York, NY, USA, 202–212.https://doi.org/10.1145/1086297.1086325