

NVIDIA于2020年在IEEE Micro上刊出了一篇题为 “Accelerating Chip Design with Machine Learning”的文章。该文章总结了NV在AI for EDA领域做的研究工作,包括设计空间探索、功耗分析、可布线性预测、模拟芯片设计等,并提出了AI 辅助芯片设计的一些愿景。
以下为原文翻译。原文很长,笔者只翻译了一些关键工作。
由于摩尔定律使芯片晶体管密度呈指数增长,我们现在可以包含在大型芯片中的独特功能不再主要受面积限制的限制。相反,新功能越来越受到与数字设计、验证和实现相关的工程工作的限制。在后摩尔定律时代,随着应用程序对专业化要求更高的性能和能效,我们预计所需的复杂性和设计工作量会增加。
从历史上看,这些挑战是通过抽象和自动化级别来解决的。在过去的几十年里,电子设计自动化 (EDA) 算法和方法被开发用于芯片设计的所有方面——设计验证和模拟、逻辑综合、布局和布线以及时序和物理签核分析。随着自动化程度的不断提高,每个芯片的总工作量增加了,但更多的工作从手动工作转移到了软件上。随着机器学习 (ML) 在许多领域转换软件,我们预计这种趋势会随着基于机器学习的 EDA 自动化而继续。
在本文中,重点介绍了我们的研究小组将 ML 应用于芯片设计任务的一些代表性工作。我们还提出了未来 AI 辅助设计流程的愿景,包括 GPU 加速、神经网络预测器和强化学习技术相结合,以实现 VLSI 设计的自动化。
典型的芯片设计规范到布局流程是一个迭代过程。大型、复杂的 SoC 被分成几十个单元。每个单元都经过微架构、RTL 设计和验证、逻辑综合、时序分析、功耗分析、布局规划、布局、时钟树综合 (CTS)、布线和最终签收。设计团队通常通过以流水线方式在不同芯片修订版上运行每个阶段来重叠流程的这些步骤。然而,为流片准备芯片仍然需要多次迭代。即使有 EDA 工具的帮助,每个流水线阶段通常也需要数天的手动工作。对于复杂的芯片,通过 RTL 到布局流程的完整迭代通常需要数周到数月的时间。
经过训练的 ML 模型可以通过预测芯片设计流程中的下游结果来帮助加快流片时间,这可以减少每次迭代的时间或提高结果质量 (QoR),例如性能、功耗或面积。无需等待数小时或数天才能获得准确结果,只需几秒钟即可提供预测。
我们重点介绍了四种可以使用预测的方式:微架构设计空间探索、功耗分析、VLSI 物理设计和模拟设计。
芯片设计人员通常编写参数化的 RTL,以支持不同的产品规格,并通过探索性能、面积和功率的权衡来进行微架构调整。只需几个参数,设计空间就可以变得非常大。对于以高级 RTL 生成器语言建模或通过高级综合 (HLS) 映射到 RTL 的加速器,工具调参可以增加潜在的微架构选择。使用蛮力搜索并不总是能够驾驭这个庞大的设计空间,尤其是在机器或许可证资源有限的情况下。
作为替代方法,我们开发了 MAGNet 来自动搜索 CNN 推理加速器的设计空间。它包含 14 个可调设计时参数,用于控制各种内存大小、并行功能单元、数据路径宽度、数据类型精度和其他微架构参数。MAGNet 流程通过模拟 HLS 生成的 RTL 来衡量性能,并分析合成大小的门级网表的功耗。
流片前功率估计和优化是当今所有芯片设计流程的一个关键方面。准确的分析需要在带有注释电容寄生的门级网表上运行逻辑仿真。然而,这些模拟非常缓慢,通常每秒运行 10-1000 个时钟周期,具体取决于活动因素和设计大小。为了提供更快而准确的功率估计,ML 模型可以通过在没有仿真的情况下通过逻辑网表估计开关活动因子的传播来预测动态功率。
GRANNITE以 PRIMAL 流程为基础,通过 GNN 实现模型可迁移到新设计。门网表被转换成具有每节点(门)和每边(网)特征的图形,例如每个门的固有状态概率。GNN 可以从图和输入激活特征中学习,同样 GRANNITE 可以从 RTL 模拟跟踪数据和输入图(网表)数据中学习。通过这种方式,模型变得能够转移到新图(网表)和新工作负载。结果表明,GRANNITE 在对高达 50k 门的设计进行快速(<1 秒)平均功率估计时实现了良好的准确性(在各种基准测试中误差小于 5.5%)。
PowerNet 通过直接从每个单元的功率分布预测 IR 降来克服这一挑战。PowerNet 使用时序窗口期间每个单元的开关功耗作为输入特征。它通过使用真实模拟结果作为标签的监督学习进行训练,以预测所有时序窗口中每个单元的最大 IR 降。由于其特征和模型遵循来自 IR 压降分析的首要原则,因此 PowerNet 可以推断训练期间未见过的设计的 IR 压降。与之前提出的用于无向量 IR 压降预测的最佳 ML 方法相比,它的准确度提高了 9%,并且与商用 IR 压降分析工具相比,速度提高了 30倍。
详细布线可能是现代物理设计流程中最耗时的阶段。在执行详细布线后,很难准确确定综合设计或布局设计在满足时序约束的同时是否不会违反 DRC。然而,较早的综合和布局阶段对设计的可布线性影响最大。因此,希望从这些早期阶段预测可布线性。VLSI 设计流程中使用拥塞和其他布局后启发式方法来估计可布线性。然而,它们通常是不准确的,需要设计工程师的直觉来排除误报并识别真正的问题。
基于图像的 DL 模型提供了一个极好的预测可路由性的机会。例如,RouteNet利用全卷积网络 (FCN) 从布局后全局布线结果中预测详细布线后 DRC。由于 FCN 可以访问全局信息和局部窗口信息,因此它们的预测比基于局部窗口或拥塞启发式的现有技术更准确。Route Net 特别适合带有宏单元的设计,这会极大地影响可布线性。对于 DRC 热点预测,与拥塞启发式和基于 SVM 的方法相比,RouteNet 将准确度提高了 50%。
在某些情况下,在逻辑综合之后,甚至可以在流程中更早地识别可路由性问题。CongestionNet 利用图注意力网络仅根据电路图来估计路由拥塞。它的预测是可能的,因为某些路由拥塞问题与某些数字电路拓扑高度相关,其特征可以被 GNN 识别。与使用之前的指标在没有放置信息的情况下预测拥塞热点相比,CongestionNet 将 Kendall 排名相关性得分提高了 29%。
模拟设计,尤其是模拟版图,是一个仍然缺乏高质量设计自动化工具的劳动密集型过程。与受限于标准单元行的数字设计相比,一个困难是更大的自由度。此外,模拟电路 QoR 指标取决于设计,而数字 QoR 指标(如时序、面积和功率)则是通用的。AI 的进步为自动化模拟设计过程提供了很好的机会。最近的一个例子是 ParaGraph,一种 GNN,它可以直接从电路原理图中预测布局寄生和器件参数。
布局后寄生预测是自动匹配模拟布局生成的关键,因为它有助于原理图和布局收敛、布局规划可行性或 QoR 估计。Para Graph 通过观察相似的电路拓扑和晶体管配置通常具有相似的布局并因此具有相似的寄生效应来做出准确的预测。它的 GNN 架构使用异构图表示,结合了来自 GraphSage、关系 GCN 和图注意力网络等模型的思想。在大型工业电路数据集上进行训练,ParaGraph 实现了 0.772 的平均预测 R2(比 XGBoost 好 110%),并且与设计人员当前使用的手动启发式相比,平均模拟错误从 100% 以上减少到 10%。
使用基于 ML 的预测器增强当今的半自动 VLSI 流程可以带来立竿见影的好处。展望未来,我们预计部署 AI 以在无需人工干预的情况下直接优化芯片设计,并增强或替换 EDA 工具中现有的最知名算法,将带来更大的突破。我们设想了一个 AI 驱动的物理设计流程,如图所示,以智能地探索潜在物理布局规划、时序和工具约束以及布局的设计空间。
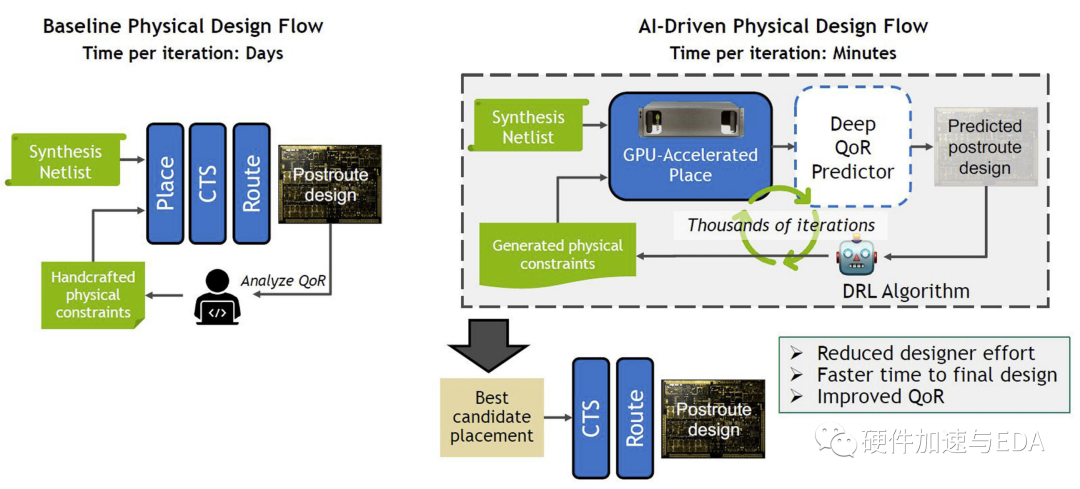
该流程可以利用快速 GPU 加速布局器和基于深度学习的深度 QoR 预测器,在 AI 驱动的循环中实现数千次快速迭代,并通过下游黑盒工具避免代价高昂的迭代。通过在 DRL 优化循环中运行,AI 驱动的流程可以自动快速地找到高质量的布局规划、时序约束和标准单元布局,这些布局可以实现良好的下游 QoR,然后将这些候选布局分配到 下游 CTS 和路由步骤。该流程由三项关键技术实现:1) 用于物理约束优化的 DRL;2) 运行在 GPU 等加速计算平台上的快速 VLSI 布局器;和 3) 基于深度学习的深度 QoR 预测器对放置后结果进行分类。
使用 DRL 学习 EDA 算法我们还设想机器学习可用于自动学习新的或改进 EDA 算法本身。许多 EDA 问题可以表述为组合优化问题。然而,准确地解决它们可能是棘手的。因此,EDA 工具求助于启发式方法。在某些情况下,例如 SAT 求解器,ML 可能能够改进启发式方法。在其他情况下,DRL 可能是合适的。例如,逻辑综合引擎反复对子电路应用诸如平衡、重写、重构和重新替换之类的转换,以逐渐提高 QoR。如果我们将这样的变换视为动作,将每次变换后的电路视为状态,那么优化就是一个马尔可夫决策过程,可以用 DRL 进行优化。
DRL 还可以减少 VLSI 后端工具中时序优化的运行时间。使用当今的工具,在具有数百万个单元的设计上运行布局、CTS 和布线可能需要长达一周的时间。大部分运行时间都用于重复和增量地优化相同的单元以及昂贵的静态时序分析 (STA) 更新。DRL 可能能够学习避免对相似小区重复优化并减少 STA 更新总数的最佳策略。
将 ML 预测器应用于 VLSI 的初步研究表明,人工智能在跨各种工具的芯片设计流程中具有潜力。未来,我们希望基于 ML 的方法(例如 DRL)适用于许多 EDA 优化问题,尤其是在难以对精确目标或约束进行建模时。DRL 可以成为 EDA 的一种新的通用算法,就像模拟退火、遗传算法和线性/非线性规划一样。由于 DL 模型经过优化,可以在 GPU 等加速计算系统上高效运行,因此我们希望看到利用世界上最强大的计算机来设计下一代芯片的良性循环,这反过来将提高未来 EDA 算法的性能。

END
