

一周前,EETOP发布的:特斯拉的一张芯片图片引发猜想:台积电InFO_SoW的首次实现,此文预告了特斯拉会于本月的AI Day活动上发布其最新的超算芯片。

8月19日特斯拉(Tesla)举行的AI Day如约而至,活动中,埃隆-马斯克(Elon Musk)及多位工程师,讲解了特斯拉纯视觉方案FSD的进展、神经网络自动驾驶训练、D1芯片和Dojo超级计算机等相关信息。其中特斯拉研发的AI训练芯片D1引起了不少人的兴趣,这款芯片将用于特斯拉目前正在构建的超级计算机,旨在以更少的消耗和更少的空间提供更高的性能。
特斯拉声称他们的 D1 Dojo 芯片具有 GPU 级别的计算能力、CPU 级别的灵活性,以及网络交换机 IO。
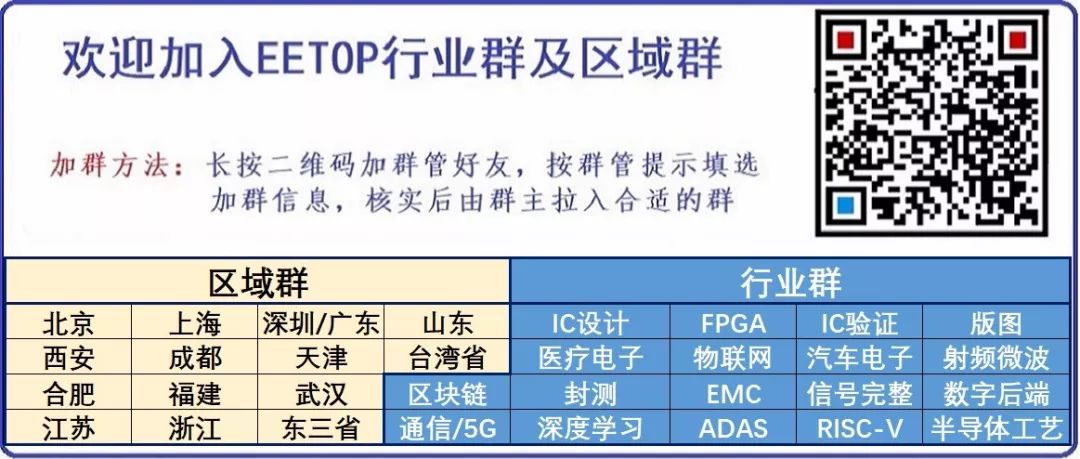
特斯拉表示,D1芯片可以提供22.6 TFLOPS的单精度浮点运算性能,BF16/CFP8的峰值算力达到了362 TFLOPS,热设计功耗(TDP)不超过400W。对AI训练来说,可扩展性非常重要,因此通过带宽为10 TB/s的“延迟交换结构”在各个方向进行互连。D1芯片周围会有一个I/O环,有576个通道,每个通道提供112 Gbit/s带宽。同时25个D1芯片可以组成的一个训练模块,带宽达到36 TB/s,BF16/CFP8的峰值算力达到9 PFLOPS。
特斯拉没有像我们一周前推测的那样确认这种封装是台积电的晶圆上集成扇出系统(InFO_SoW),但考虑到疯狂的芯片间带宽以及他们特别提到扇出晶圆的事实,这似乎很有可能。

它集成了四个64位超标量CPU核心,拥有多达354个训练节点,特别用于8×8乘法,支持FP32、BFP64、CFP8、INT16、INT8等各种数据指令格式,都是AI训练相关的。
特斯拉称,D1芯片的FP32单精度浮点计算性能达22.6TFlops(每秒22.6万亿次),BF16/CFP8计算性能则可达362TFlops(每秒362万亿次)。
为了支撑AI训练的扩展性,它的互连带宽非常惊人,最高可达10TB/s,由多达576个通道组成,每个通道的带宽都有112Gbps。而实现这一切,热设计功耗仅为400W。
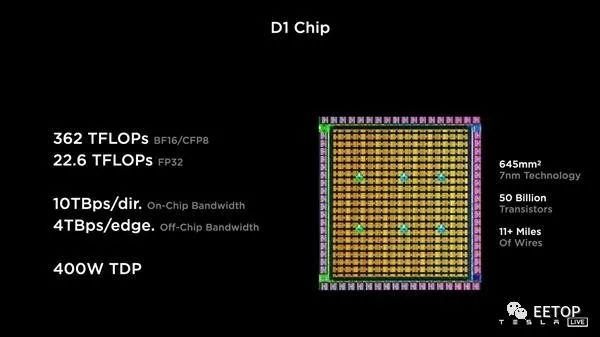
特斯拉D1芯片可通过DIP(Dojo接口处理器)进行互连,25颗组成一个训练单元(Training Tile),而且多个训练单元可以继续互连,单个对外带宽高达36TB/s,每个方向都是9TB/s。
如此庞然大物,耗电量和发热都是相当可怕的,电流达18000A,覆盖一个长方体散热方案,散热能力高达15kW。

如果在数个机柜中部署120个训练模块(包含3000个D1芯片),就能组成ExaPOD。这是世界上首屈一指的AI训练超级计算机,超过100万个训练节点,BF16/CFP8的峰值算力达到1.1 ExaFLOPS。相比特斯拉目前基于英伟达设备构造的超级计算机,在同样成本条件下,性能提高了4倍,每瓦性能提高了1.3倍,占地面积仅为五分之一。

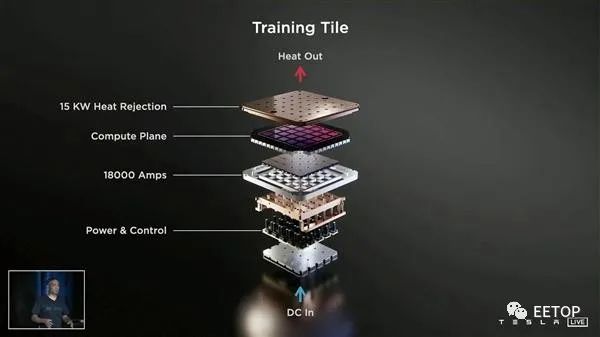
特斯拉展示了实验室内部的一个训练单元,运行频率2GHz,计算性能最高9PFlops(每秒9千万亿次)。
关注创芯大讲堂,祝您IC技能更上一层楼!

