书里面使用这个spark,我这里就配置一下(失败了。。。)
从这里下载
https://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz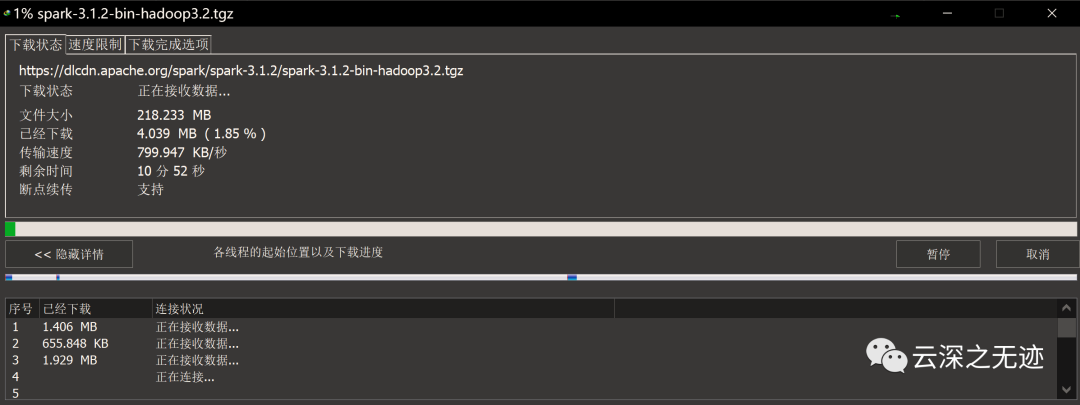
IDM真不是和你吹牛,飞快

本来不想用conda,可是看见都把我的环境占了
就用它
我有两个版本的Py
conda install jupyter先安装一下jupyter,conda里面没有
装好有这个

安装的速度有些慢
conda install pyspark也可以py包安装
C:\Spark
移动后解压
看看bin目录

设置一个环境变量
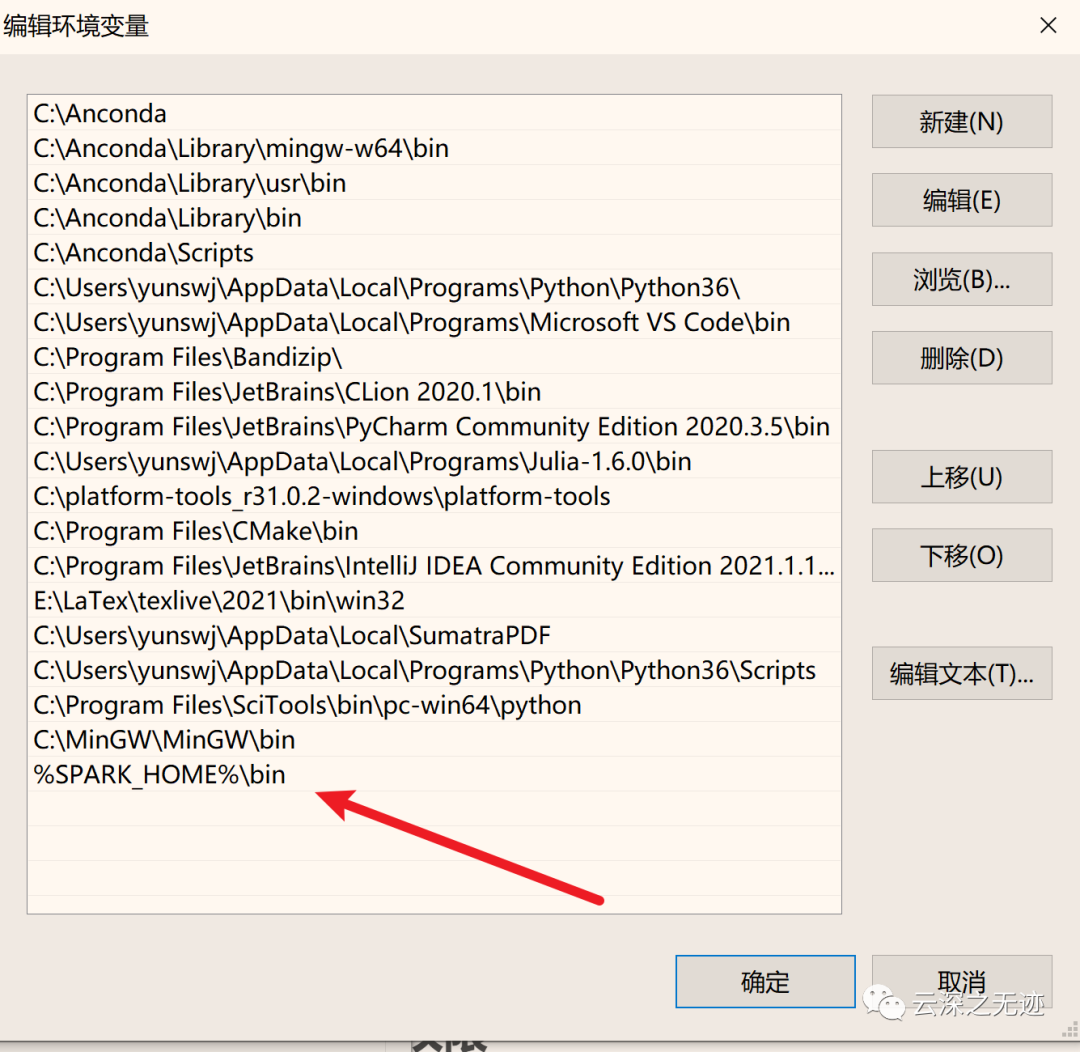
这里也要
C:\Anconda\Lib\site-packagesC:\Spark\spark-3.1.2-bin-hadoop3.2\spark-3.1.2-bin-hadoop3.2\python把里面的pyspark文件夹,都复制到上面的路径
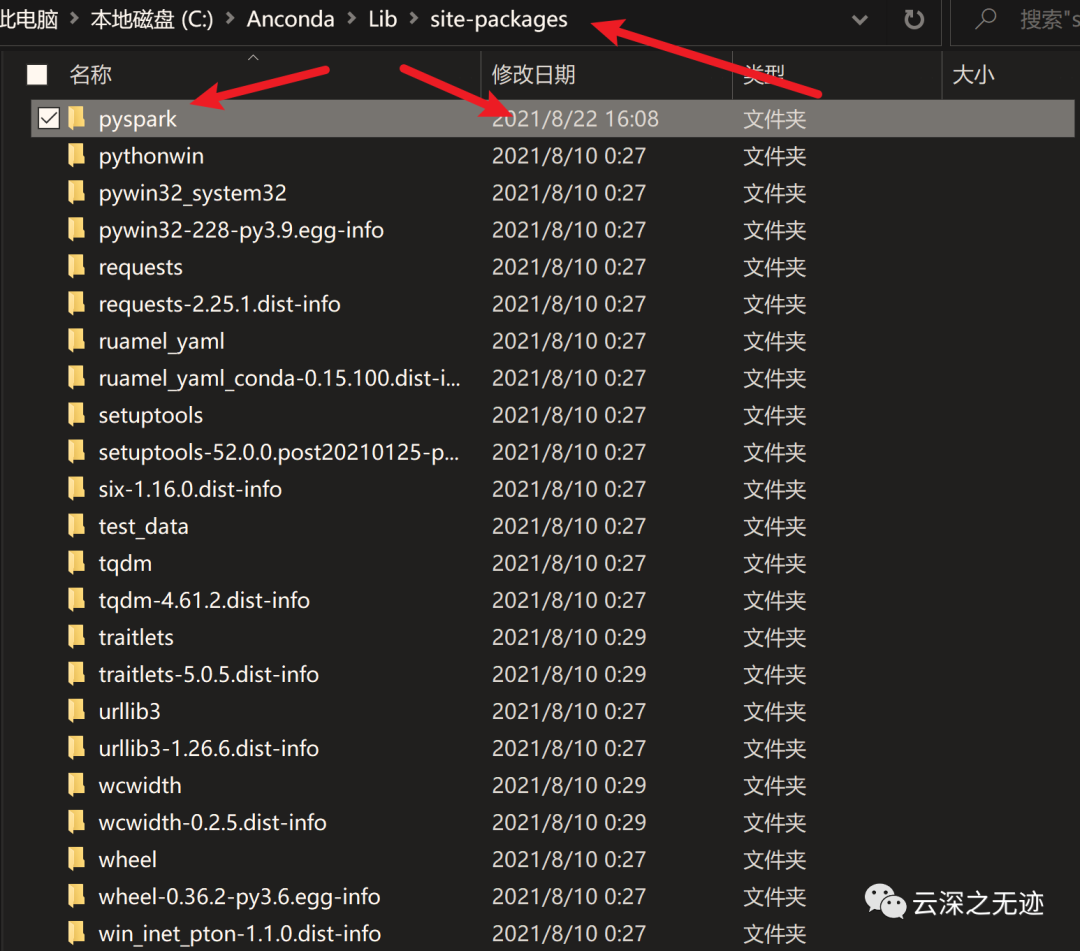
上面有个文章说,这样就是把spark安装好了
实际上,没有卵用
啊这,我觉得好像是同一个东西
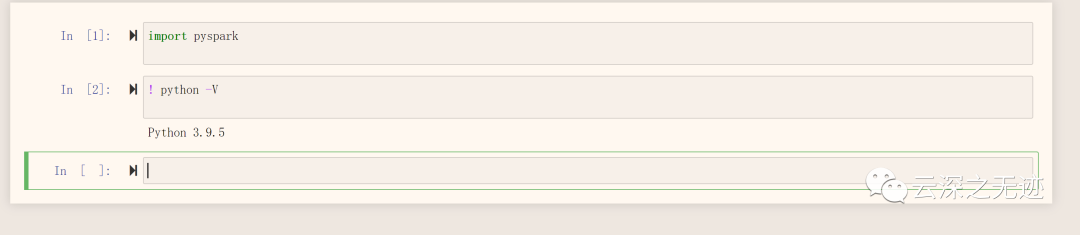
导入成功
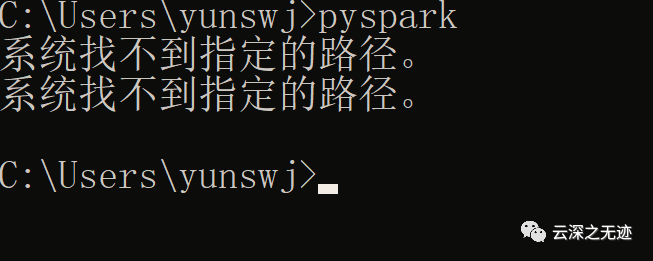
这个报错
删除环境变量后,正常一点:

from pyspark.sql import SparkSession导入
spark = SparkSession.builder\.master("local[*]") \.appName("Test") \.config("spark.executor.memory", "1gb") \.getOrCreate()
写个集群的代码
spark.stop()关掉集群

这个错误
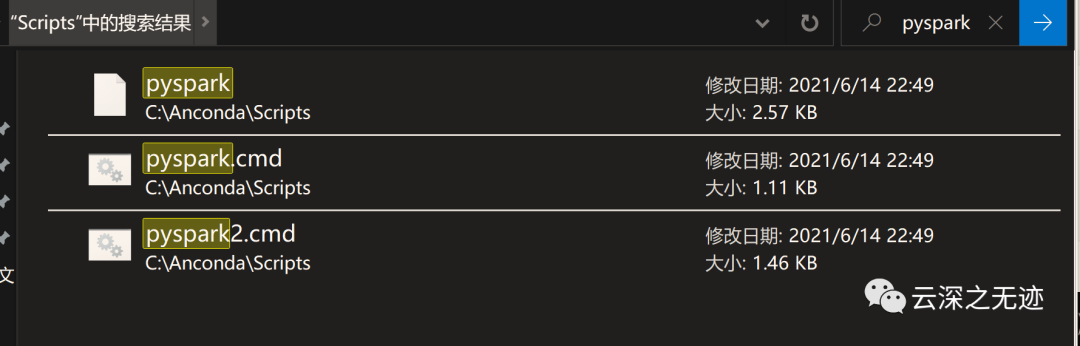
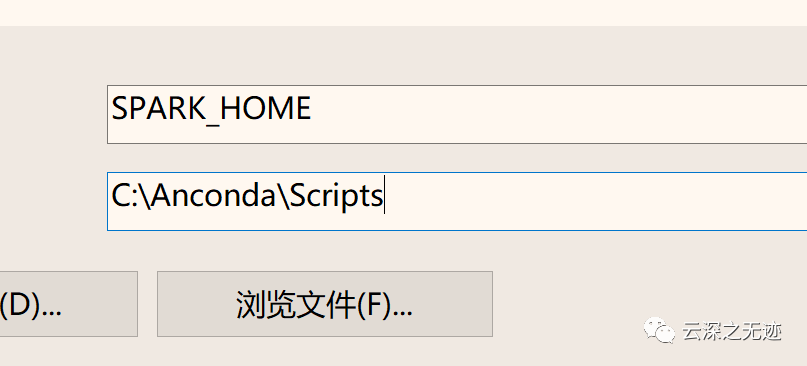
在这里加个环境变量
conda uninstall pyspark我悟了,卸载先

http://spark.apache.org/docs/latest/api/python/getting_started/install.html#using-conda去Ubuntu安装吧,这个真不会了。。
