

环境:
处理器架构:arm64
内核源码:linux-5.11
ubuntu版本:20.04.1
代码阅读工具:vim+ctags+cscope
本文步进到Linux内核进程管理的核心部分,打开调度器的黑匣子,来看看Linux内核如何调度进程的。实际上,进程调度器主要做两件事:选择下一个进程,然后进行上下文切换。而何时调用主调度器调度进程那是调度时机所关注的问题,而调度时机在之前的内核抢占文章已经做了详细讲解,在此不在赘述,而本文关注的调度时机是真正调用主调度器的时机。
本文分析的内核源代码主要集中在:
kernel/sched/core.c
kernel/sched/fair.c
关于调度时机,网上的文章也五花八门,之前在内核抢占文章已经做了详细讲解,而在本文我们从源码注释中给出依据(再次强调一下:本文的调度时机关注的是何时调用主调度器,不是设置重新调度标志的时机,之前讲解中我们知道他们都可以称为调度时机)。
先来说一下什么是主调度器,其实和主调度器并列的还有一个叫做周期性调度器的东西(后面有机会会讲解,主要用于时钟中断tick调来使夺取处理器的控制权),他们都是内核中的一个函数,在合适的时机被调用。
主调度器函数如下:
kernel/sched/core.c
__schedule()
内核的很多路径会包装这个函数,主要分为主动调度和抢占式调度场景。
内核源码中主调度器函数也给出了调度时机的注释,下面我们就以此为依据来看下:
kernel/sched/core.c
/*
* __schedule() is the main scheduler function.
*
* The main means of driving the scheduler and thus entering this function are:
*
* 1. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
*
* - If the kernel is preemptible (CONFIG_PREEMPTION=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPTION is not set)
* then at the next:
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
*
* WARNING: must be called with preemption disabled!
*/
static void __sched notrace __schedule(bool preempt)
我们对注释做出解释,让大家深刻理解调度时机(基本上是原样翻译,用颜色标注)。
1.显式阻塞场景:包括互斥体、信号量、等待队列等。
这个场景主要是为了等待某些资源而主动放弃处理器,来调用主调度器,如发现互斥体被其他内核路径所持有,则睡眠等待互斥体被释放的时候来唤醒我。
解释如下:这实际上是说重新调度标志(TIF_NEED_RESCHED)的设置和检查的情形。
1)重新调度标志设置情形:如scheduler_tick周期性调度器按照特定条件设置、唤醒的路径上按照特定条件设置等。当前这样的场景并不会直接调用主调度器,而会在最近的调度点到来时调用主调度器。
2)重新调度标志检查情形:是真正的调用主调度器,下面的场景都会涉及到,在此不在赘述。
3.唤醒并不会真正导致schedule()的进入。他们添加一个任务到运行队列,仅此而已。
现在,如果添加到运行队列中的新任务抢占了当前任务,那么唤醒设置TIF_NEED_RESCHED, schedule()在最近的可能情况下被调用:
1)如果内核是可抢占的(CONFIG_PREEMPTION=y)
-在系统调用或异常上下文中,最外层的preempt_enable()。(这可能和wake_up()的spin_unlock()一样快!)
-在IRQ上下文中,从中断处理程序返回到抢占上下文
注释中很简洁的几句话,但其中的含义需要深刻去体会。
首先需要知道一点是:内核抢占说的是处于内核态的任务被其他任务所抢占的情况(无论是不是可抢占式内核,处于用户态的任务都可以被抢占,处于内核态的任务是否能被抢占由是否开启内核抢占来决定),当然内核态的任务可以是内核线程也可以是通过系统调用请求内核服务的用户任务。
情况1:这是重新开启内核抢占的情况,即是抢占计数器为0时,检查重新调度标志(TIF_NEED_RESCHED),如果设置则调用主调度器,放弃处理器(这是抢占式调度)。
情况2:中断返回内核态的时候,检查重新调度标志(TIF_NEED_RESCHED),如果设置且抢占计数器为0时则调用主调度器,放弃处理器(这是抢占式调度)。
注:关于内核抢占可以参考之前发布的文章。
2)如果内核是不可抢占的(CONFIG_PREEMPTION=y)
解释如下:
cond_resched()是为了在不可抢占内核的一些耗时的内核处理路径中增加主动抢占点(抢占计数器是否为0且当前任务被设置了重新调度标志),则调用主调度器进行抢占式调度,所进行低延时处理。
显式的schedule()调用,这是主动放弃处理器的场景,如一些睡眠场景,像用户任务调用sleep。
系统调用或异常返回到用户空间使会判断当前进程是否设置重新调度标志(TIF_NEED_RESCHED),如果设置则调用主调度器,放弃处理器。
中断处理器返回到用户空间会判断当前进程是否设置重新调度标志(TIF_NEED_RESCHED),如果设置则调用主调度器,放弃处理器。
其实还有一种场景也会调用到主调度器让出处理器,那就是进程退出时,这里不在赘述。
下面给出总结:
1.主动调度:
睡眠场景,如sleep。
显式阻塞场景,如互斥体,信号量,等待队列,完成量等。
任务退出时,调用do_exit去释放进程资源,最后会调用一次主调度器
2.抢占调度:
不可抢占式内核
cond_resched()调用
显式的schedule()调用
从系统调用或异常返回到用户空间
从中断处理器返回到用户空间
可抢占式内核(增加一些抢占点)
重新开启内核抢占
中断返回内核态的时候
下面给出主要的一些主调度器调用时机源码分析,作为学习参考。
中断返回用户态场景:
arch/arm64/kernel/entry.S
el0_irq
-> ret_to_user
-> work_pending
-> do_notify_resume
-> if (thread_flags & _TIF_NEED_RESCHED) { // arch/arm64/kernel/signal.c
schedule();
-> __schedule(false); // kernel/sched/core.c false表示主动调度
异常返回用户态场景:
arch/arm64/kernel/entry.S
el0_sync
-> ret_to_user
...
任务退出场景:
kernel/exit.c
do_exit
->do_task_dead
->__schedule(false); // kernel/sched/core.c false表示主动调度
显式阻塞场景(举例互斥体):
kernel/locking/mutex.c
mutex_lock
->__mutex_lock_slowpath
->__mutex_lock
->__mutex_lock_common
->schedule_preempt_disabled
->schedule();
-> __schedule(false); // kernel/sched/core.c false表示主动调度
中断返回内核态场景
arch/arm64/kernel/entry.S
el1_irq
#ifdef CONFIG_PREEMPTION
->arm64_preempt_schedule_irq
->preempt_schedule_irq();
->__schedule(true); //kernel/sched/core.c true表示抢占式调度
#endif
内核抢占开启场景
preempt_enable
->if (unlikely(preempt_count_dec_and_test())) \ //抢占计数器减一 为0
__preempt_schedule(); \
->preempt_schedule //kernel/sched/core.c
-> __schedule(true) //调用主调度器进行抢占式调度
注:一般说异常/中断返回,返回是处理器异常状态,可能是用户态也可能是内核态,但是会看到很多资料写的都是用户空间/内核空间并不准确,但是我们认为表达一个意思,做的心中有数即可。
本节主要讲解主调度器是如何选择下一个进程的,这和调度策略强相关。
下面我们来看具体实现:
kernel/sched/core.c
__schedule
-> next = pick_next_task(rq, prev, &rf);
->if (likely(prev->sched_class <= &fair_sched_class &&
¦ rq->nr_running == rq->cfs.h_nr_running)) {
p = pick_next_task_fair(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto restart;
/* Assumes fair_sched_class->next == idle_sched_class */
if (!p) {
put_prev_task(rq, prev);
p = pick_next_task_idle(rq);
}
return p;
}
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
这里做了优化,当当前进程的调度类为公平调度类或者空闲调度类时,且cpu运行队列的进程个数等于cfs运行队列进程个数,说明运行队列进程都是普通进程,则直接调用公平调度类的pick_next_task_fair选择下一个进程(选择红黑树最左边的那个进程),如果没有找到说明当前进程调度类为空闲调度类,直接调用pick_next_task_idle选择idle进程。
否则,遍历调度类,从高优先级调度类开始调用其pick_next_task方法选择下一个进程。
下面以公平调度类为例来看如何选择下一个进程的:调用过程如下(这里暂不考虑组调度情况):
pick_next_task
->pick_next_task_fair //kernel/sched/fair.c
-> if (prev)
put_prev_task(rq, prev);
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
先看put_prev_task:
put_prev_task
->prev->sched_class->put_prev_task(rq, prev);
->put_prev_task_fair
->put_prev_entity(cfs_rq, se);
->/* Put 'current' back into the tree. */
__enqueue_entity(cfs_rq, prev);
cfs_rq->curr = NULL;
这里会调用__enqueue_entity将前一个进程重新加入到cfs队列的红黑树。然后将cfs_rq->curr 设置为空。
再看pick_next_entity:
pick_next_entity
->left = __pick_first_entity(cfs_rq);
->left = rb_first_cached(&cfs_rq->tasks_timeline);
将选择cfs队列红黑树最左边进程。
最后看set_next_entity:
set_next_entity
->__dequeue_entity(cfs_rq, se);
->cfs_rq->curr = se;
这里调用__dequeue_entity将下一个选择的进程从cfs队列的红黑树中删除,然后将cfs队列的curr指向进程的调度实体。
选择下一个进程总结如下:
运行队列中只有公平进程则选择公平调度类的pick_next_task_fair选择进程。
当前进程为idle进程,且没有公平进程存在情况下,调用pick_next_task_idle选择idle进程。
运行队列存在除了公平进程的其他进程,则从高优先级到低优先级调用具体调度类的pick_next_task选择进程。
对于公平调度类,选择下一个进程主要过程如下:1)调用put_prev_task方法将前一个进程重新加入cfs队列的红黑树。2)调用pick_next_entity 选择红黑树最左边的进程作为下一个进程。3)将下一个进程从红黑树中删除,cfs队列的curr指向进程的调度实体。
通用的调度类选择顺序为:
stop_sched_class -> dl_sched_class ->rt_sched_class -> fair_sched_class ->idle_sched_class
比如:当前运行队列都是cfs的普通进程,某一时刻发生中断唤醒了一个rt进程,那么在最近的调度点到来时就会调用主调度器选择rt进程作为next进程。
做了以上的工作之后,红黑树中选择下一个进程的时候就不会再选择到当前cpu上运行的进程了,而当前进程调度实体又被cfs队列的curr来记录着(运行队列的curr也会记录当前进程)。
下面给出公平调度类选择下一个进程图解(其中A为前一个进程,即是当前进程,即为前一个进程,B为下一个进程):
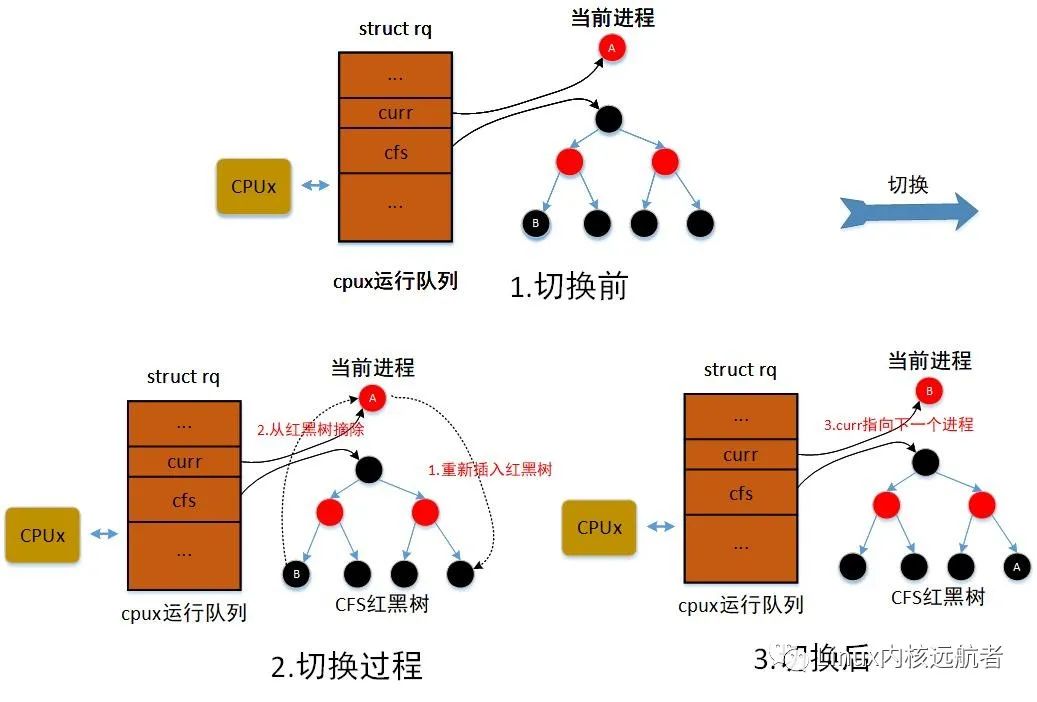
前面选择了一个合适进程作为下一个进程,接下来做重要的上下文切换动作,来保存上一个进程的“上下文”恢复下一个进程的“上下文”,主要包括进程地址空间切换和处理器状态切换。
注:这里的上下文实际上是指进程运行时最小寄存器的集合。
如果切换的next进程不是同一个进程,才进行切换:
__schedule
i f (likely(prev != next)) {
...
context_switch //进程上下文切换
}
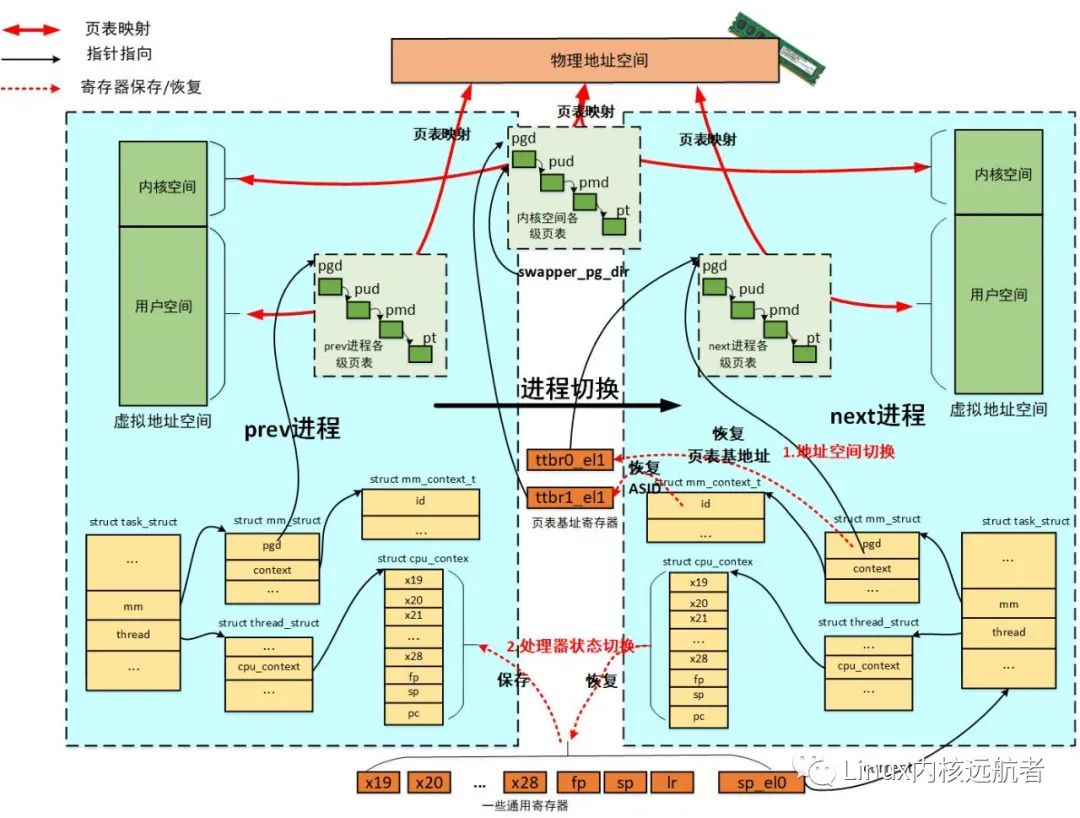
进程地址空间切换就是切换虚拟地址空间,使得切换之后,当前进程访问的是属于自己的虚拟地址空间(包括用户地址空间和内核地址空间),本质上是切换页表基地址寄存器。
进程地址空间切换让进程产生独占系统内存的错觉,因为切换完地址空间后,当前进程可以访问属于它的海量的虚拟地址空间(内核地址空间各个进程共享,用户地址空间各个进程私有),而实际上物理地址空间只有一份。
下面给出源代码分析:
context_switch
->
/*
¦* kernel -> kernel lazy + transfer active
¦* user -> kernel lazy + mmgrab() active
¦*
¦* kernel -> user switch + mmdrop() active
¦* user -> user switch
¦*/
if (!next->mm) { // to kernel
enter_lazy_tlb(prev->active_mm, next);
next->active_mm = prev->active_mm;
if (prev->mm) // from user
mmgrab(prev->active_mm);
else
prev->active_mm = NULL;
} else { // to user
...
switch_mm_irqs_off(prev->active_mm, next->mm, next);
if (!prev->mm) { // from kernel
/* will mmdrop() in finish_task_switch(). */
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
}
以上代码是判断是否next进程是内核线程,如果是则不需要进行地址空间切换(实际上指的是用户地址空间),因为内核线程总是运行在内核态访问的是内核地址空间,而内核地址空间是所有的进程共享的。在arm64架构中,内核地址空间是通过ttbr1_el1来访问,而它的主内核页表在内核初始化的时候已经填充好了,也就是我们常说的swapper_pg_dir页表,后面所有对内核地址空间的访问,无论是内核线程也好还是用户任务,统统通过swapper_pg_dir页表来访问,而在内核初始化期间swapper_pg_dir页表地址已经加载到ttbr1_el1中。
需要说明一点的是:这里会做“借用” prev->active_mm的处理,借用的目的是为了避免切换属于同一个进程的地址空间。举例说明:Ua -> Ka -> Ua ,Ua表示用户进程, Ka表示内核线程,当进行这样的切换的时候,Ka 借用Ua地址空间,Ua -> Ka不需要做地址空间切换,而Ka -> Ua按理来说需要做地址空间切换,但是由于切换的还是Ua 地址空间,所以也不需要真正的切换(判断了Ka->active_mm == Ua->active_mm ),当然还包括切换的是同一个进程的多个线程的情况,这留给大家思考。
下面来看下真正的地址空间切换:
switch_mm_irqs_off(prev->active_mm, next->mm, next);
->switch_mm //arch/arm64/include/asm/mmu_context.h
-> if (prev != next)
__switch_mm(next);
->check_and_switch_context(next)
-> ... //asid处理
-> cpu_switch_mm(mm->pgd, mm)
->cpu_do_switch_mm(virt_to_phys(pgd),mm)
-> unsigned long ttbr1 = read_sysreg(ttbr1_el1);
unsigned long asid = ASID(mm);
unsigned long ttbr0 = phys_to_ttbr(pgd_phys);
...
write_sysreg(ttbr1, ttbr1_el1); //设置asid到ttbr1_el1
isb();
write_sysreg(ttbr0, ttbr0_el1); //设置mm->pgd 到ttbr0_el1
上面代码是做真正的地址空间切换,实际的切换很简单,并没有那么复杂和玄乎,仅仅设置页表基地址寄存器即可,当然这里还涉及到了为了防止频繁无效tlb的ASID的设置。
主要做的工作就是设置next进程的ASID到ttbr1_el1, 设置mm->pgd 到ttbr0_el1,仅此而已!
需要注意的是:1.写到ttbr0_el1的值是进程pgd页表的物理地址。2.虽然做了这样的切换,但是这个时候并不能访问到next的用户地址空间,因为还处在主调度器上下文中,属于内核态,访问的是内核空间。
而一旦返回了用户态,next进程就能正常访问自己地址空间内容:
访问一个用户空间的虚拟地址va,首先通过va和记录在ttbr1_el1的asid查询tlb,如果找到相应表项则获得pa进行访问。
如果tlb中没有找到,通过ttbr0_el1来遍历自己的多级页表,找到相应表项则获得pa进行访问。
如果发生中断异常等访问内核地址空间,直接通过ttbr1_el1即可完成访问。
访问没有建立页表映射的合法va,发生缺页异常来建立映射关系,填写属于进程自己的各级页表,然后访问。
访问无法地址,发生缺页杀死进程等等。
来切换下一个进程的执行流,上一个进程执行状态保存,让下一个进程恢复执行状态。
处理器状态切换而后者让进程产生独占系统cpu的错觉,使得系统中各个任务能够并发(多个任务在多个cpu上运行)或分时复用(多个任务在一个cpu上运行)cpu资源。
下面给出代码:
context_switch
->(last) = __switch_to((prev), (next))
-> fpsimd_thread_switch(next) //浮点寄存器切换
...
last = cpu_switch_to(prev, next);
处理器状态切换会做浮点寄存器等切换,最终调用cpu_switch_to做真正切换。
cpu_switch_to //arch/arm64/kernel/entry.S
SYM_FUNC_START(cpu_switch_to)
mov x10, #THREAD_CPU_CONTEXT
add x8, x0, x10
mov x9, sp
stp x19, x20, [x8], #16 // store callee-saved registers
stp x21, x22, [x8], #16
stp x23, x24, [x8], #16
stp x25, x26, [x8], #16
stp x27, x28, [x8], #16
stp x29, x9, [x8], #16
str lr, [x8]
add x8, x1, x10
ldp x19, x20, [x8], #16 // restore callee-saved registers
ldp x21, x22, [x8], #16
ldp x23, x24, [x8], #16
ldp x25, x26, [x8], #16
ldp x27, x28, [x8], #16
ldp x29, x9, [x8], #16
ldr lr, [x8]
mov sp, x9
msr sp_el0, x1
ptrauth_keys_install_kernel x1, x8, x9, x10
scs_save x0, x8
scs_load x1, x8
ret
SYM_FUNC_END(cpu_switch_to)
这里传递过来的是x0为prev进程的进程描述符(struct task_struct)地址, x1为next的进程描述符地址。会就将prev进程的 x19-x28,fp,sp,lr保存到prev进程的tsk.thread.cpu_context中,next进程的这些寄存器值从next进程的tsk.thread.cpu_context中恢复到相应寄存器。这里还做了sp_el0设置为next进程描述符的操作,为了通过current宏找到当前的任务。
需要注意的是:
这里给出了进程切换的图示(以arm64处理器为例),这里从prev进程切换到next进程。
当进程重新被调度的时候,从原来的调度现场恢复执行。
1)如果切换的next进程是刚fork的进程,它并没有真正的这些调度上下文的存在,那么lr是什么呢?这是在fork的时候设置的:
do_fork
...
copy_thread //arch/arm64/kernel/process.c
->memset(&p->thread.cpu_context, 0, sizeof(struct cpu_context));
p->thread.cpu_context.pc = (unsigned long)ret_from_fork;
p->thread.cpu_context.sp = (unsigned long)childregs;
设置为了ret_from_fork的地址,当然这里也设置了sp等调度上下文(这里将进程切换保存的寄存器称之为调度上下文)。
SYM_CODE_START(ret_from_fork)
bl schedule_tail
cbz x19, 1f // not a kernel thread
mov x0, x20
blr x19
1: get_current_task tsk
b ret_to_user
SYM_CODE_END(ret_from_fork)
刚fork的进程,从cpu_switch_to的ret指令执行后返回,lr加载到pc。
于是执行到ret_from_fork:这里首先调用schedule_tail对前一个进程做清理工作,然后判断是否为内核线程如果是执行内核线程的执行函数,如果是用户任务通过ret_to_user返回到用户态。
2)如果是之前已经被切换过的进程,lr为cpu_switch_to调用的下一条指令地址(这里实际上是__schedule函数中调用barrier()的指令地址)。
switch_to(prev, next, prev)
-> ((last) = __switch_to((prev), (next)))
这里做处理器状态切换时,传递了两个参数,返回了一个参数:
prev和next很好理解就是 就是前一个进程(当前进程)和下一个进程的 task_struct结构指针,那么last是什么呢?
一句话:返回的last是当前重新被调度的进程的上一个进程的 task_struct结构指针。
如:A ->B ->千山万水->D -> A 上面的切换过程:A切换到B 然后经历千山万水再从D -> A,这个时候A重新被调度时,last即为D的 task_struct结构指针。
获得当前重新被调度进程的前一个进程是为了回收前一个进程资源,见后面分析。
进程被重新调度时无论是否为刚fork出的进程都会走到finish_task_switch这个函数,下面我们来看它做了什么事情:
主要工作为:检查回收前一个进程资源,为当前进程恢复执行做一些准备工作。
finish_task_switch
->finish_lock_switch
->raw_spin_unlock_irq //使能本地中断
->if (mm)
mmdrop(mm) //有借有还 借用的mm现在归还
->if (unlikely(prev_state == TASK_DEAD)) { //前一个进程是死亡状态
put_task_stack(prev); //如果内核栈在task_struct中 释放内核栈
put_task_struct_rcu_user(prev); //释放前一个进程的task_struct占用内存
}
可以看到进程被重新调度时首先需要做的主要是:
重新使能本地中断 ,进程被重新调度时,本地cpu中断是被重新打开的!!!
如果有借用mm的情况,现在归还 如果前一个是内核线程,在进程地址空间切换时“借用了”某个进程的mm_struct,现在切换到了下一个进程,理应归还,归还做的是递减借用的mm_struct的引用计数,引用计数为0就会释放mm_struct占用的内存。
对于上一个死亡的进程现在回收最后的资源, 注意这里是递减引用计数,当引用计数为0时才会真正释放。
主调度器可以说Linux内核进程管理中的核心组件,进程管理的其他部分如抢占、唤醒、睡眠等都是围绕它来运作。在原子上下文不能发生调度,说的就是调用主调度器,但是可以设置抢占标志以至于在最近的抢占点发生调度,如中断中唤醒高优先级进程的场景。主调度器所做的工作就是让出cpu,内核很多场景可以直接或间接调用它,而大体上可以分为两种情况:即为主动调度和抢占式调度。主调度器做了两件事情:选择下一个进程和进程进程上下文切换。选择下一个进程解决选择合适高优先级进程的问题。进程进程上下文切换又分为地址空间切换和处理器状态切换,前者让进程产生独自占用系统内存的错觉,而后者让进程产生独自占用系统cpu的错觉,让系统各个进程有条不紊的共享内存和cpu等资源。
