关注「嵌入式大杂烩」,星标公众号,一起进步!

来源:裸机思维
【说在前面的话】
static volatile uint32_t s_wMSCounter = 0;extern uint32_t SystemCoreClock;/*! \brief initialise platform before main()*/__attribute__((constructor(101)))void platform_init(void){SystemCoreClockUpdate();/* Generate interrupt each 1 ms */SysTick_Config(SystemCoreClock / 1000);}__attribute__((weak))void systimer_1ms_handler(void){/* default systimer 1ms hander* you can override it by implement a non-weak version*/}void SysTick_Handler (void){if (s_wMSCounter) {s_wMSCounter--;}systimer_1ms_handler();}void delay_ms(uint32_t wMillisecond){s_wMSCounter = wMillisecond;while( s_wMSCounter > 0 );}
上述代码非常典型,唯一需要强调的是SystemCoreClock是一个定义在启动文件system_<芯片型号>.c 里的全局变量,负责保存当前处理器的工作频率——上面的平台初始化函数 platform_init() 就是借助这一变量把 SysTick 初始化为以“1ms为间隔产生中断”的。
有的人习惯于直接用软件方法堆积NOP()来实现——这种方法所产生的延时效果“可能”容易受到编译器优化等级的影响——据说这也是很多人惧怕开启编译器的原因之一,因为一开优化,很多对时间敏感的硬件时序就因为延时函数的不稳定而一起变得不可捉摸;
extern uint32_t SystemCoreClock;#ifndef DELAY_US_CALIBRATION/*! \brief 不要问我为啥是 8, 我也不知道,但在当前这个工程下,8貌似最准*! 你如果不服,就自己测一个,然后定义这个宏……*! 如果你头铁改了工程的优化等级,请也无比亲自测一下……具体怎么*! 测,我也不知道。如果你也怕麻烦,就不要改优化等级。*/# define DELAY_US_CALIBRATION 8#endifvoid delay_us(uint32_t wUS){//! calcluate how many cycles required for 1usuint32_t wCyclesPerUS = SystemCoreClock / 1000000ul;/*! subtract some cycles from wCyclesPerUS based on the*! experience or actual measurement in current optimisation*/wCyclesPerUS -= DELAY_US_CALIBRATION;for (int i = 0; i < wUS; i++) {for (j = 0; j < wCyclesPerUS; j++) {__NOP();}}}
有的人提倡使用定时器来实现精确延时,这一方案显然不太惧怕编译器优化的“血腥巨斧”。想法是没错的,但如果要保证这样写出来的延时库有一定的可移植性,就需要保证 delay_us() 函数实现所依赖的硬件定时器是“通用的”和“普遍存在”的——符合这一要求的第一选择是SysTick——然而既然SysTick已经被 delay_ms() 占用了,又如何能抽的开身呢?
DWT 根本就不是设计给用户用的,它是Cortex-M处理器预留给上位机调试软件(例如MDK)进行调试和追踪的。换句话说,上位机调试软件觉得这是自己的私人财产,从来没想过用户会去使用它——这就导致调试过程中,IDE会按照自己的意思随意修改它的配置——啥时候会改呢?这要看IDE的心情。如果你的程序依赖了DWT进行延时,那么调试的时候,IDE的一个无心之举可能就会毁了你的时序——这一知识点非常容易忽略掉,从而导致很多人遇到调试的时候,系统随机性的功能不正常的坑,从而浪费大把的时间,往往还想不到是DWT导致的——说这一方法是天坑可能一点也不为过。
DWT 不是所有 Cortex-M 芯片都有……(Cortex-M0/M0+就没有)
提供一个精确的 delay_us() 函数;
提供一个精确测量任意代码块所实际占用系统周期数的方法;
实现一个记录从进入 main() 函数以来总共经历了多少个时钟周期(且在合理的时间范围内不会溢出)的计数器(时间戳);
用户已有的 SysTick 功能不能受到干扰;
比如用户使用 SysTick 作为RTOS的基准时钟(非Tickless模式);
比如用户使用 SysTick 作为普通的毫秒级延时(就像前面例子代码所展示的那样);
用户不需要修改自己任何已有的 SysTick 代码。
【部署 perf_counter 库】
解压缩后可以看到如下的内容:
如果只是普通的使用,直接拷贝 lib 目录到你的工程即可。
第二步,将库加入到已有的 MDK 工程中:
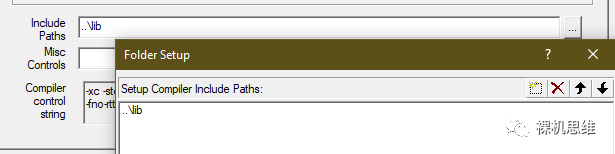
别忘记在工程的头文件搜寻路劲中包含 perf_counter.h 所在文件夹,例如(具体位置根据你工程的情况而定,不要死脑经):
第三步:编译并调整一些工程选项
如果你编译后很顺利,则请跳过下面的内容,快进到 0 error 0 warning的图片之后。

好,下面让我们来谈谈你可能遇到的问题,以及对应的解决方案:
问题一:提示找不到 $Super$$SysTick_Handler

.\Out\example.axf: Error: L6218E: Undefined symbol $Super$$SysTick_Handler (referred from systick_wrapper_ual.o).Not enough information to list image symbols.Not enough information to list load addresses in the image map.Finished: 2 information, 0 warning and 1 error messages.".\Out\example.axf" - 1 Error(s), 0 Warning(s).
perf_counter 库是一个“附加型”库——它假设你自己已经实现了一个SysTick的中断处理程序,并开启了中断模式——如果你没有,直接加一个空的就好了:
void SysTick_Handler (void){}
好,问题解决。什么?你的工程也根本没有用SysTick?好办,请在进入main后调用函数init_cycle_counter() 并传递false,例如:
int main(void){...init_cycle_counter(false);...}
这样做的目的是告诉 perf_counter:“请自己玩的开心”。
问题二:wchar和enum的尺寸不兼容:
需要强调的是,perf_counter.lib 库在编译的时候,开启了 Short enums/wchar(分别对应命令行的 -fshort-enums -fshort-wchar)。这么做其实没什么特别的原因,但如果你的工程使用了不同的配置,例如:
下图的工程配置中,没有勾选 "Short enums/wchar"
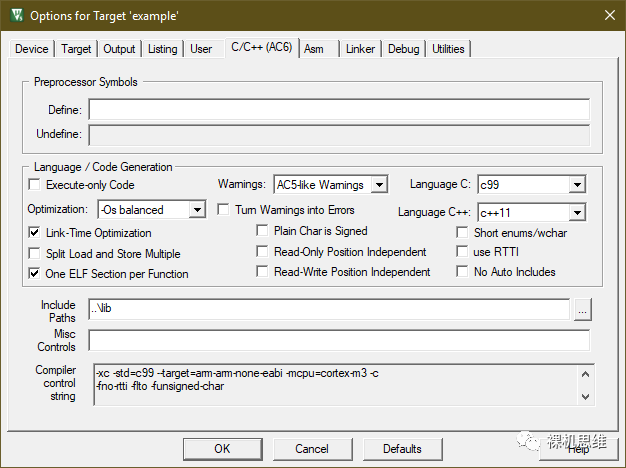
你一定会看到这样的编译错误:

.\Out\example.axf: Error: L6242E: Cannot link object perf_counter.o as its attributes are incompatible with the image attributes.... wchart-16 clashes with wchart-32.... packed-enum clashes with enum_is_int.
既然知道了原因,解决方法就很简单,要么在工程配置中勾选上这一选项;要么使用源代码编译(不使用lib):
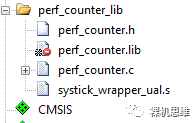
也就是图中所示的:perf_counter.c 和 systick_wrapper_ual.s。
perf_counter.c 依赖了 CMSIS,所以确保你的工程中加入了对CMSIS的支持——推荐的是使用MDK自带的 CMSIS,在RTE配置界面中勾选:
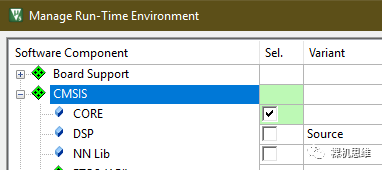
如果你使用的是工程自带的CMSIS(很多STM32工程就是这样),请确保你的CMSIS 是较新的版本(判断标准就是是否带有 cmsis_compiler.h)。
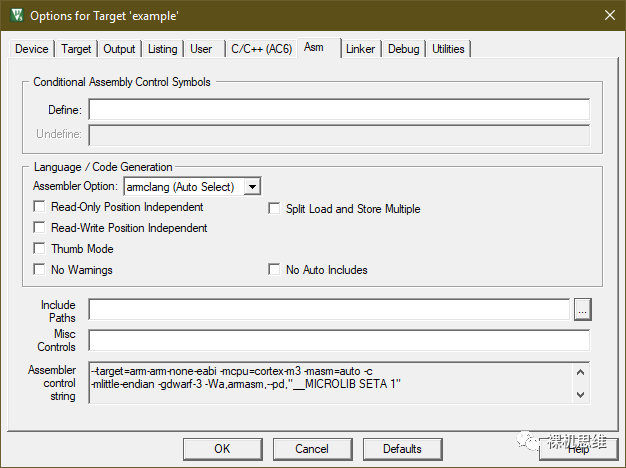
armclang(Auto Select)——我吐血推荐选这个
armclang(GNU Syntax)—— 这个意思就是使用 GNU的汇编语法,显然不能选它;
armclang(Arm Syntax)——这是最新MDK(从5.32开始)才有的选项,选了也行;
armasm(Arm Syntax)——这就是 Arm Compiler 5里一直使用的老汇编器,选他当然兼容性最好。

至此,我们完成了 perf_counter 库在工程中的部署。那么它带给我们哪些功能呢?
【SysTick第一吃:微秒级精确延时】
#include "perf_counter.h"...delay_us(30); //!< delay 30 us...
再也不用担心编译器优化导致延时不准啦!!!
再也不担心库不通用啦!!!
再也不用担心芯片不支持DWT啦!!!!!!
再也不用担心调试/追踪会干扰DWT啦!!!!

【SysTick第二吃:精确测量代码的时钟周期】
extern void start_cycle_counter(void);extern int32_t stop_cycle_counter(void);
start_cycle_counter();//! 测量 打印 "Hello World\r\n" 究竟用了多少个时钟周期printf("Hello World! \r\n");int32_t iCycleUsed = stop_cycle_counter(void);printf("Cycle Used: %d", iCycleUsed);
当然,如果你的工程环境允许你用printf的话,还可以用 perf_counter.h 自带的宏将上述代码简化一下:
//! the demo of __cycleof__()__cycleof__() {printf("Hello World\r\n");}
其运行结果为:
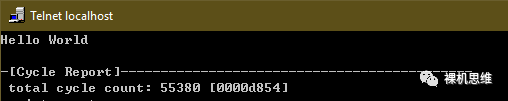
(以上结果为FVP仿真结果,CPU周期数值不可以做参考)
我们甚至还可以添加一点注释性的字符串,帮助我们区分测试的范围:
//! the demo of __cycleof__()__cycleof__("Print string") {printf("Hello World\r\n");}
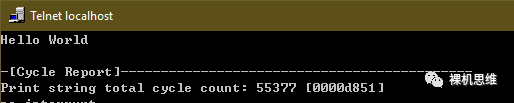
我们看到,传递给__cycleof__的提示字符串"Print string"被添加到了"total cycle count:..." 的前面,一目了然。
实际上,start_cycle_counter() 和 stop_cycle_counter() 的组合还可以用来测量中断处理程序实际使用的系统周期数——读过我【实时性迷思】系列文章的小伙伴,一定知道测量“事件处理函数所需时间”的意义:
volatile int32_t g_nMaxHandlingCycles = 0;void USART0_RX_Handler(void){start_cycle_counter();//! 你的USART0 接收中断处理程序实际内容...int32_t nCycles = stop_cycle_counter();g_nMaxHandlingCycles = MAX(nCycles, g_nMaxHandlingCycles);}
从此一举告别“拍脑袋凭感觉”说中断处理时间要多长的旧世界。

此外,start_cycle_counter() 和 stop_cycle_counter() 还支持类似体育老师所使用的秒表的功能,即,起跑后、可以分别记录每一个学生所用的时间。具体表现为:
int32_t nCycles = 0;start_cycle_counter(); //!< 开始总计时...nCycles = stop_cycle_counter(); //!< 第一次获取从开始以来的时间...nCycles = stop_cycle_counter(); //!< 第二次获取从开始以来的时间...nCycles = stop_cycle_counter(); //!< 第三次获取从开始以来的时间...
具体什么情况下要用到这样的方式就见仁见智了,这里就不再继续展开。
【SysTick第三吃:系统时间戳】
void delay_us(int32_t iUs){iUs *= SystemCoreClock / 1000000ul;start_cycle_counter();while(stop_cycle_counter() < iUs);}

__attribute__((nothrow))extern int64_t clock(void);
extern _ARMABI clock_t clock(void);而 clock_t 在 Cortex-M环境下定义如下:
typedef unsigned int clock_t; /* cpu time type */为什么perf_counter.h 要采用不一样的定义呢?
说起来也简单:clock() 函数返回的是系统周期数,而不是什么以 us 或者 ms 为单位的时间——考虑到现在处理器频率动辄几百兆赫兹,有的甚至达到了1GHz(比如 NXP的RT系列),如果用 int32_t (哪怕用 uint32_t)也撑不了几秒钟。
假设系统频率为1GHz,使用 uint32_t 来计数,由于32bit整数取值范围是0~4G,因此,最多4秒就撑不住了……
那究竟多长才够呢?

当我们使用 int64_t 的时候,哪怕系统频率是 4GHz,2G 秒 ≈ 24855 天 ≈ 68年。虽然没有一万年那么久,不过多半一个嵌入式设备也没法用这么久(千年虫警告),但考虑到大部分Cortex-M嵌入式系统估计没有4GHz这么夸张,轻松跑个1000多年不溢出应该是没有问题的。
既然我们铁了心要用 int64_t 来取代 clock_t 原本的 int32_t,怎么解决这里的冲突呢?——显然去修改系统头文件 <time.h>是不允许的!
翻开Arm的隐藏宝典:AAPCS,我们发现以下的规则:
32位系统下,
如果函数的返回值其大小不超过32bit,则保存在寄存器 r0中;
如果函数的返回值其大小为64bit,则其低 32bit 保存在 r0中、高32bit保存在 r1中。
显然,当我们实现clock()函数时返回 int64_t的值与 返回 int32_t其实是兼容的——因为低32bit的内容实际上都是保存在 r0 里的,此时如果用户调用clock() 的时候:
使用的是<time.h>里定义的函数原型,即 clock_t clock(void),则,当函数返回时,r1里保存的值会被无视,只有r0里的值被视作返回值;
使用的是我们自己定义的函数原型,即 int64_t clock(void),则你可以获得完整的 int64_t 时间戳。
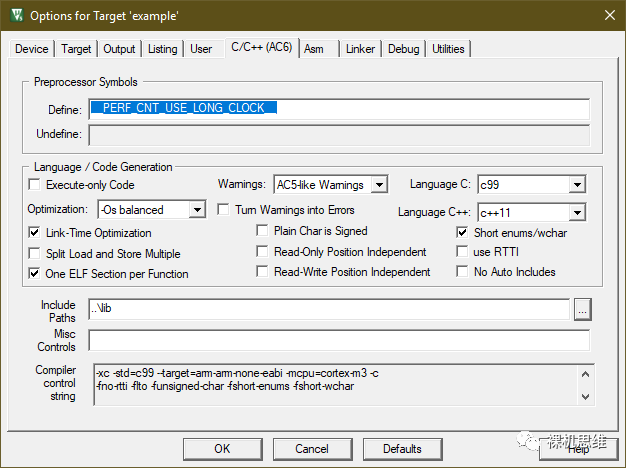
既然原理清楚了,再看 perf_counter.h 里面的定义,我们会发现clock()的函数原型被一个宏 __PERF_CNT_USE_LONG_CLOCK__ 保护着:
__attribute__((nothrow))extern int64_t clock(void);
这实际上是告诉我们,如果我们想获得 int64_t 时间戳时,只要在工程中定义宏 __PERF_CNT_USE_LONG_CLOCK__ 就可以了。
忙活了半天,有的小伙伴可能会疑惑了:饶了这么一大圈,clock() 究竟有啥用处呢?这玩法就多了,快一键三联~ 下次我们好好来说说。

【后记】
在 Arm Compiler 5(armcc)和 Arm Compiler 6中,不需要用户手工对库进行初始化——库会在进入main()之前“自己做”;
Lib中的perf_counter.lib适用于包含Cortex-M0在内的全系列Cortex-M处理器,做到全覆盖;
perf_counter.h 几乎不依赖 <stdint.h>和<stdbool.h>之外的库。使用.lib进行部署,非常简洁方便。
如果你要用 safe_atom_code(),则需要 __disable_irq() 和 __set_PRIMASK() 的定义,一般Cortex-M工程都有。这些定义是由 CMSIS提供的。一般来说,普通的 perf_counter 功能并不需要涉及任何这些内容。
如果你原本的 RTOS 使用了 SysTick并开启了Tickless模式,perf_counter虽然不会干扰原有的 SysTick功能,但自己的计时功能却会受到 Tickless模式的干扰;
perf_counter库假设你原本的SysTick应用会保持一个固定的定时周期——也就是 LOAD寄存器的内容是固定的、不会随着程序的执行而经常变化。其实RTOS的tickless模式会干扰perf_counter的计数可靠性也是这个原因。
如果你喜欢我的思维、觉得我的文章对你有所启发,
请务必 “点赞、收藏、转发” 三连,这对我很重要!谢谢!
欢迎订阅 裸机思维


Linux GNU C 与 ANSI C 有什么区别?

长文 | 有C基础,如何快速过度到C++?

分享一篇很好的C指针文章,查缺补漏!
在公众号聊天界面回复1024,可获取嵌入式资源;回复 m ,可查看文章汇总。
