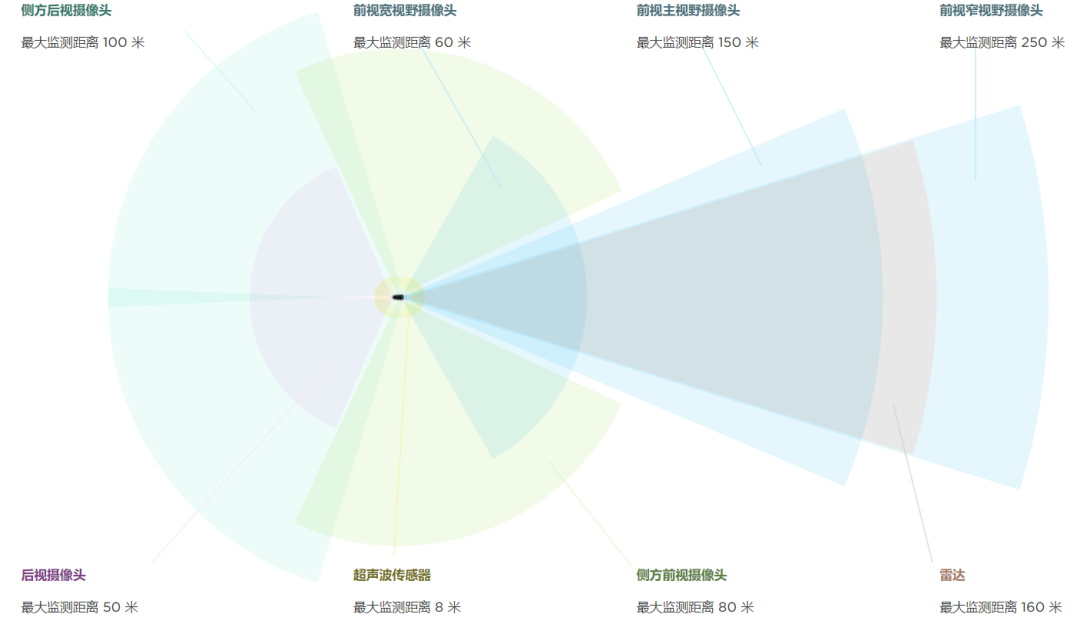
近年来,越来越多的企业在5S管理的基础上,开始追求6S、7S甚至8S管理,仿佛S越多,管理就越先进,企业就越优秀。于是,6S增加了“安全”,7S又加上了“节约”,8S甚至引入了“学习”……看似更加全面,实则很多企业只是机械地增加S,却忽略了管理的核心目标:提升效率、降低浪费、优化工作环境。优思学院认为,5S本身已经是一套成熟的精益管理工具,它的核心理念不仅简单高效,而且易于实施和推广。如果企业只是为了赶时髦,盲目增加S,而没有真正理解5S的本质,那么这些额外的“S”很可能会变成管理上的负担,而不
优思学院
2025-03-07 12:43
207浏览