
首先算力和你使用的计算芯片有关系,如果你的算法大部分是标量计算,那这个值没有意义,当下我们所说的TOPS高算力实际都只是GPU的乘积累加矩阵运算算力。
不同的芯片都通过总线和外界联系,有自己的缓存体系,以及数字和逻辑运算单元。CPU和GPU两者的区别在于片内的缓存体系和数字逻辑运算单元的结构差异。CPU虽然有多核,但总数没有超过两位数,每个核都有足够大的缓存和足够多的数字和逻辑运算单元,并辅助有很多加速分支判断甚至更复杂的逻辑判断的硬件;GPU的核数远超CPU,被称为众核(NVIDIA Fermi有512个核)。每个核拥有的缓存大小相对小,数字逻辑运算单元也少而简单(GPU初始时在浮点计算上一直弱于CPU)。从结果上导致CPU擅长处理具有复杂计算步骤和复杂数据依赖的计算任务,如分布式计算,数据压缩,人工智能,物理模拟,以及其他很多很多计算任务等。
当程序员为CPU编写程序时,他们倾向于利用复杂的逻辑结构优化算法从而减少计算任务的运行时间,即Latency.当程序员为GPU编写程序时,则利用其处理海量数据的优势,通过提高总的数据吞吐量(Throughput)来掩盖Lantency。
普遍意义上,CPU对应标量计算,主要是路径规划和决策算法,此外部分激光雷达使用ICP点云配准算法,CPU比GPU能更好对应。常用的传感器融合如卡尔曼滤波算法也多是标量运算。GPU对应矢量或者说向量计算,包括点云,地图,深度学习,核心是矩阵运算。我们可以将标量视为零阶张量,矢量视为一阶张量,那么矩阵就是二阶张量。
目前TOPS的物理计算单位是积累加运算(英语:Multiply Accumulate, MAC)是在微处理器中的特殊运算。实现此运算操作的硬件电路单元,被称为“乘数累加器”。这种运算的操作,是将乘法的乘积结果b*c和累加器a的值相加,再存入累加器a的操作:
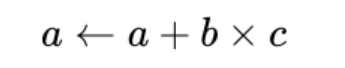
若没有使用 MAC 指令,上述的程序可能需要二个指令,但 MAC 指令可以使用一个指令完成。而许多运算(例如卷积运算、点积运算、矩阵运算、数字滤波器运算、乃至多项式的求值运算)都可以分解为数个 MAC 指令,因此可以提高上述运算的效率。
MAC指令的输入及输出的数据类型可以是整数、定点数或是浮点数。若处理浮点数时,会有两次的数值修约(Rounding),这在很多典型的DSP上很常见。若一条MAC指令在处理浮点数时只有一次的数值修约,则这种指令称为“融合乘加运算”/“积和熔加运算”(fused multiply-add, FMA)或“熔合乘法累积运算”(fused multiply–accumulate, FMAC)。
讨论理论算力前有几个基本概念,GPU计算常用的数据类型有三种FP32,FP16和INT8,三种的计算方式如下
单精度浮点存储-FP32占用4个字节,共32位,其中1位为符号位(0为正,1为负),8位指数位,23为有效数字。

IEEE 754规定,对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M

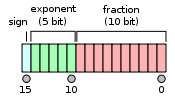
半精度浮点存储-FP16占用2个字节,共16位,其中1位为符号位(0为正,1为负),5位指数位,10为尾数位。
整数存储-INT8,八位整型占用1个字节,共8位,其中1位为符号位(0为正,1为负),7为数据位
整数的计算很好理解2的7次方构成(-128-127)的数字范围
换算成10进制为 从低位到高位开始计算 0 1 1 1 1 1 1 1
0*2^7 + 1*2^6 + 1*2^5 + 1*2^4 + 1*2^3 + 1*2^2 + 1*2^1 + 1*2^0
0 + 64 + 32 + 16 + 8 + 4 + 2 + 1= 127
换算成10进制为 从低位到高位开始计算 1 0 0 0 0 0 0 0
1*2^7 + 0*2^6 + 0*2^5 + 0*2^4 + 0*2^3 + 0*2^2 + 0*2^1 + 0*2^0=128
GPU和CPU都有工作频率,频率越高,性能越高;同时它的功耗和发热也越高。一般意义的超频就是更改运算频率来提高性能。Xavier(GPU)20W功耗下单精度浮点性能1.3TFLOPS,Tensor核心性能20TOPs,解锁到30W后可达30TOPs。为什么有每瓦TOPS一说,就是为了规避超频这个问题。另外,这里的功耗往往指的是单元芯片本身的功耗与算力比,没有考虑DRAM。在深度学习计算中,数据频繁存取,极端情况下,功耗可能不低于运算单元。
假设一个芯片,运行频率2GHz,一般温度25°,电压0.8V,算力为2TOPS。在WCS下,温度为125度,电压0.72V,此时频率会降低到1GHz,算力就会降为1TOPS。一般宣传的TOPS都是BCF下的结果。
宣传的TOPS往往都是运算单元的理论值,而非整个硬件系统的真实值。真实值更多取决于内部的SRAM、外部DRAM、指令集和模型优化程度。最糟糕的情况下,真实值是理论值的1/10算力甚至更低,一般也就50%的使用率。
理论值取决于运算精度、MAC的数量和运行频率。可大致简化为INT8精度下的MAC数量在FP16精度下等于减少了一半。FP32再减少一半,依次类推。
假设有512个MAC运算单元,运行频率为1GHz,INT8的数据结构和精度,算力为512 x 2 x 1 GHz = 1000 Billion Operations/Second = 1 TOPS(Tera-Operations/second)。FP16精度那么就是0.5TOPS,FP32精度就是0.25TOPS。英伟达的Tesla V100有640个Tensor核,每核有64个MAC运算单元,运行频率大约1.480GHz,那么INT8下算力为640 * 64 * 2 * 1.480 GHz=121TOPS。
ResNet-50需要MAC大约为每秒70亿次运算,英伟达TeslaT4运行ResNet-50每秒可处理3920张224*224的图像,3920 images/second x 7 BillionOperations/image = 27,440 Billion Operations/second = 27.4 TrillionOperations/Second = 27.4 TOPS。而英伟达Tesla T4的理论算力是130TOPS。实际只有27.4TOPS。
决定算力真实值最主要因素是内存( SRAM和DRAM)带宽,谷歌第一代TPU,理论值为90TOPS算力,最差真实值只有1/9,也就是10TOPS算力,因为第一代内存带宽仅34GB/s。而第二代TPU下血本使用了HBM内存,带宽提升到600GB/s(单一芯片TPU V2板内存总带宽2400GB/s)。这里谈的还是静态层面上的问题,一代TPU更多的是面向一个主流算法,他的算力和内存匹配没有做好。
但就算面向主流算法做好了内存和算力的匹配,情况也不会有多好的改善,因为动态的来看,不考虑使用的算法,内存和算力无法很好的匹配
算法对于内存带宽的需求通常使用「运算强度 (operational intensity,或称 arithmetic intensity)」这个量来表示,单位是 OPs/byte。这个量的意思是,在算法中平均每读入单位数据,能支持多少次运算操作。运算强度越大,则表示单位数据能支持更多次运算,也就是说算法对于内存带宽的要求越低。
我们来举一个例子。对于步长(stride)为 1 的 3x3 卷积运算,假设输入数据平面大小为 64x64。简单起见,假设输入和输出 feature 都为 1。这时候,总共需要进行 62x62 次卷积运算,每次卷积需要做 3x3=9 次乘加运算,所以总共的计算次数为 34596,而数据量为(假设数据和卷积核都用单精度浮点数 2byte):64x64x2(输入数据)+ 3x3x2(卷积核数据)= 8210 byte,所以运算强度为 34596/8210=4.21。如果我们换成 1x1 卷积,那么总的计算次数变成了 64x64=4096,而所需的数据量为 64x64x2 + 1x1x2=8194。显然,切换为 1x1 卷积可以把计算量降低接近 9 倍,但是运算强度也降低为 0.5,即对于内存带宽的需求也上升了接近 9 倍。因此,如果内存带宽无法满足 1x1 卷积计算,那么切换成 1x1 卷积计算虽然降低了接近 9 倍计算量,但是无法把计算速度提升 9 倍。
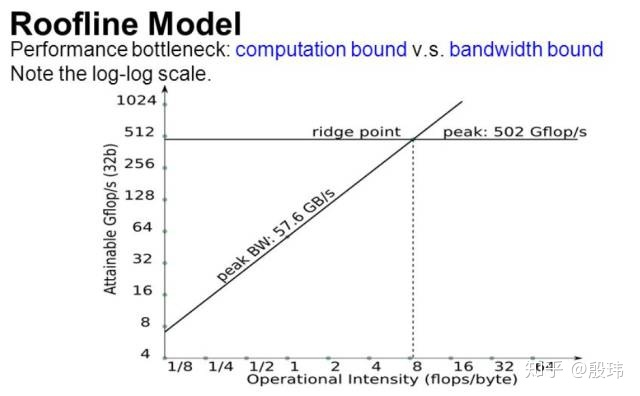
深度学习计算设备存在两个瓶颈,一个是处理器计算能力,另一个是计算带宽。分析哪一个限制了计算性能可以使用 Roofline 模型-计算性能(纵轴)和算法的运算强度(横轴)。Roofline 曲线分成了两部分:左边的上升区,以及右边的饱和区。当算法的运算强度较小时,曲线处于上升区,即计算性能实际被内存带宽所限制,有很多计算处理单元是闲置的。随着算法运算强度上升,即在相同数量的数据下算法可以完成更多运算,于是闲置的运算单元越来越少,这时候计算性能就会上升。然后,随着运算强度越来越高,闲置的计算单元越来越少,最后所有计算单元都被用上了,Roofline 曲线就进入了饱和区,此时运算强度再变大也没有更多的计算单元可用了,于是计算性能不再上升,或者说计算性能遇到了由计算能力(而非内存带宽)决定的「屋顶」(roof)。拿之前 3x3 和 1x1 卷积的例子来说,3x3 卷积可能在 roofline 曲线右边的饱和区,而 1x1 卷积由于运算强度下降,有可能到了 roofline 左边的上升区,这样 1x1 卷积在计算时的计算性能就会下降无法到达峰值性能。虽然 1x1 卷积的计算量下降了接近 9 倍,但是由于计算性能下降,因此实际的计算时间并不是 3x3 卷积的九分之一。
为何大部分人工智能算法公司都想定制或自制计算平台。算法的性能与硬件设计往往脱离不开。追求模块化就要牺牲利用率。要提高利用率就需要软硬件一体设计。你的算法是用GPU合适还是CPU合适,网络模型一次用多少内存又同时使用多少MAC,由此来设计芯片。或者说反过来给定一个芯片,我的算法要如何兼容,是否要减少内存访问次数提高利用率,还是要迁移部分CPU基于规则的算法,改为用GPU基于深度学习来实现。软硬件一起考虑往往才能充分利用好系统性能。
阅读原文,关注作者知乎


