

本文由公众号 MikesICroom 特约供稿
作为RSIC处理器的代表,ARM一直走在技术的最前列。不过对于Vector指令集的支持却一直十分谨慎。第一代ARM SVE (Scalable Vector Extension)作为AArchv8的扩展推出,后者早就大获成功,而SVE商用中只有作为超算的富岳(Fugaku)支持了该扩展,似乎连ARM自己开发的IP核都没有支持。最近推出的SVE v2进一步拓展了Vector可支持的运算类型。本文简述ARM SVE的发展以及和NEON的区别来探讨Vector在AI中的应用。
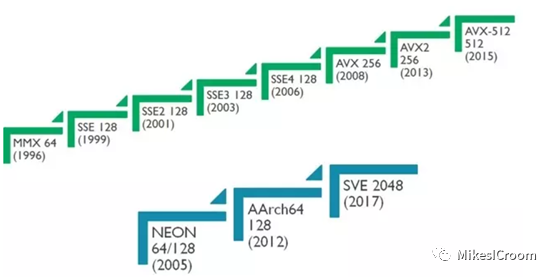 SVE一直被称为ARM NEON的下一代扩展,这里有必要首先了解下什么是ARM的NEON,即Advanced SIMD扩展。NEON是AArchv7的特性之一,是一种典型的单指令流单数据(SIMD)。不同于Vector所推崇的可变计算长度,NEON使用固定的128 bits长度进行计算。同一个128 bits NEON寄存器可以分割成为2个64 bits(Double Floating-Point),4个32 bits(Single Floating-Piont,integer),8个16bits(Half floating-point, half-word),以及16个byte。一个NEON寄存器中的数据可以进行并行计算。也可以对一个NEON寄存器中的各个数据进行处理。
SVE一直被称为ARM NEON的下一代扩展,这里有必要首先了解下什么是ARM的NEON,即Advanced SIMD扩展。NEON是AArchv7的特性之一,是一种典型的单指令流单数据(SIMD)。不同于Vector所推崇的可变计算长度,NEON使用固定的128 bits长度进行计算。同一个128 bits NEON寄存器可以分割成为2个64 bits(Double Floating-Point),4个32 bits(Single Floating-Piont,integer),8个16bits(Half floating-point, half-word),以及16个byte。一个NEON寄存器中的数据可以进行并行计算。也可以对一个NEON寄存器中的各个数据进行处理。
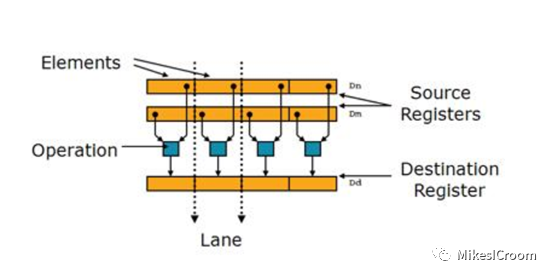
相对于可变长度的Vector寄存器,NEON的这种固定长度的数据格式非常有利于早期程序员对其格式和运算的理解以及进行相应intrinsic的开发。不同于Vector,NEON的数据类型编码在其指令中,这样就避免了Vector需要在每次计算之前设置运算长度和数据类型,减少了这类控制的代价,在处理器性能比较低的情况下尤为重要。同时128bits的计算宽度相对适中,对于高速流水线设计比较友好,可以很好的在现有的scalar pipeline中进行扩展实现,也不需要考虑诸如可扩展性这种对于Vector非常重要的特性。因此对于多媒体这类计算适中的应用,NEON是一个匹配的实现,在推出至今获得和很大的成功。
因此,在适当的时刻推出与其需求匹配的设计是neon能够成功的关键因素,这也是芯片设计的“天时”。arm在这方面一直是得心应手。比如compress指令的推出适应了当时对存储空间的极致需求,jazelle技术对于执行java bytecode的加速使手机芯片可以在基础性能不高的情况下较好的运行java程序。aarch64更是顺应了软件对更宽地址和运算的需求,因此哪怕另起炉灶式的设计也能如此快速的获得成功。这里当然有ARM强大的生态作为后盾,但合理且适时的设计也功不可没。
不过随着AI对更大算力的需求,neon当时那些成功的因素反而成为制约它继续发展的缺陷。最主要的一点就是其固定长度的计算方式,这样根本上限制了NEON的进一步扩展并行计算能力。通过多发射来提高性能非常受硬件复杂度和时序的限制,通常都只能做到双发射。这样就很难在单个核心上堆砌更大的算力。其次是neon的不可扩展性,如果改成neon256或者512,之前在128上开发的各种库都要跟着更新甚至重写,这是个庞大的工作量。并且万一之后有1024的需求呢?因此提出了对更大算力和软件兼容的新需求。

上述两点在arm的SVE中就得到了很好的解决。SVE指令集是一个可变计算长度的定义,通过设置当前的执行长度vector length,就可以并行执行所设置数量的运算。具体数目可以根据需求来设计,比如超算富岳所使用的富士通公司开发的A64FX内核中就使用了sve512的配置。
其次,这个vector length是在每次循环中通过指令获得的,这样同一份代码是可以不经改动跑在不同长度的sve机器上,很好的解决了代码移植的问题。第三,随着编译技术的发展,对于自动向量化的推进也获得了很大的进步,在不远的将来也许就能很方便的用编译器自动产生向量指令,免去了手工编写intrinsic的工作,这也是vector能够胜过Neon的关键因素。ARM的SVE1支持32个vector寄存器,寄存器的低位数据复用为NEON寄存器,8个predicate寄存器用来支持mask执行,丰富的指令类型可以覆盖neon所支持的大部分操作。因此才说sve是neon的下一代产品。

(http://www.eetop.cn/semi/6952362.html)
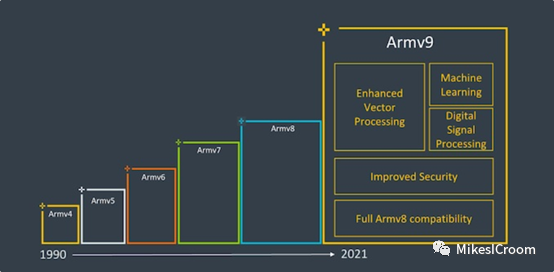
arm向来是架构先行。虽然第一代SVE除了富岳超算外并没有其他的商用产品,arm仍然在去年推出了SVE2,以最新的 Armv9为基础,扩充了更多的运算类型以全面替代neon,同时,也是最重要的一点,增加了矩阵相关运算的支持。这是arm在通用架构中对AI迈出的重要一步。当前的AI加速器大多都是固定功能,只有gpgpu架构能提供较通用的支持。通过提供对矩阵运算的支持,ARM就在ISA层面集合了vector和matrix的多重运算能力,从而以CPU为基础实现了对控制和运算,以及编程性和算力的良好平衡。不过目前SVE2的文档还没有公开,会在之后获得更多资料后再来分析相关的改进。总而言之,ARM在vector上的设想对于通用AI运算还是很有意义的,至于最后是否能够在GPGPU的生态下脱颖而出,打下一片天地,就要看ARM在自家生态中的推广和产品化的力度了。
感谢公众号:MikesICroom 供稿,大家可以关注MikesICroom,在后台回复“课程”获取斯坦福大学AI加速器课程资料。
======================

