英国剑桥大学和 NVIDIA DGX SuperPOD 指明通往新一代安全、高效的高性能计算(HPC)云之路。
云原生超级计算是超级计算领域的下一个大趋势。如今趋势已至,旨在助力我们应对最棘手的 HPC 和 AI 应用。
在英国,剑桥大学正在构建一台云原生超级计算机。在美国,有两个研究团队正在分别开发云原生超级计算的关键软件部分。
作为与统一通信框架(UCF)联盟合作项目的一部分,洛斯阿拉莫斯国家实验室正在助力实现加速数据算法的能力。俄亥俄州立大学正在更新消息传递接口 (MPI) 软件,以增强科学仿真。
NVIDIA 正在通过最新的 DGX SuperPOD 向全球用户提供云原生超级计算机。DGX SuperPOD 现已投入生产,它包含 NVIDIA BlueField-2 DPU(数据处理器)等关键组成部分。
就像锐滋的花生酱夹心巧克力一样,云原生超级计算融合了两项业界领先的技术优点。
云原生超级计算机融合了高性能计算的强大算力和云服务的安全性与易用性。
换个角度看,云原生超级计算提供了一个性能强如 TOP500 超级计算机的 HPC 云,它在保障不牺牲应用性能的同时允许多用户安全共享。
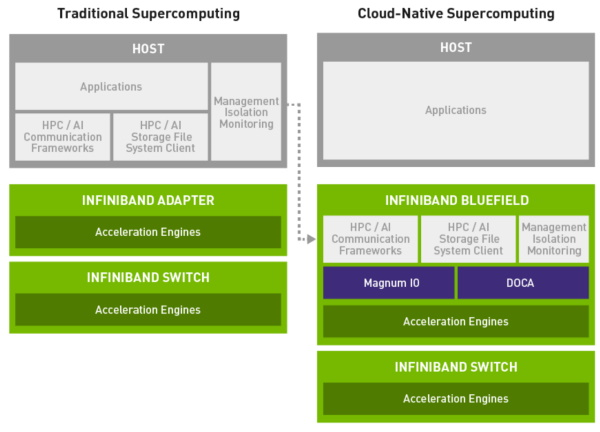
BlueField DPU 通过支持安全、通信和管理任务的卸载来创建高效的云原生超级计算机。
首先,它允许多用户共享一台超级计算机,同时保证每个用户的应用的安全性和私密性。这种能力被称为“多租户隔离”,在当今的商业云计算服务中十分普遍,但一般不会出现在技术和科学应用的 HPC 系统中,因为在这些系统中,裸性能的优先级最高,而安全服务会降低系统效率。
其次,云原生超级计算机使用 DPU 来处理存储、租户隔离安全和系统管理等任务。这样可以卸载 CPU,使其专注于处理任务,从而最大限度地提高系统的整体性能。
如此,一台超级计算机便可以在不损失性能的情况下,实现云原生服务。未来 DPU 将处理更多的卸载任务,从而使系统在运行 HPC 和 AI 应用时时刻保持最高的运行效率。
如今,超级计算机通常有两个 “大脑” —— CPU 和加速器(一般为 GPU)。
加速器集合了数千个处理核,可为 AI 和 HPC 应用中最重要的并行运算提供加速。CPU 是针对需要快速串行处理的算法部分而设计的,但随着其管理的系统日益庞大且日渐复杂,通信的层数不断增多,导致 CPU 的负担越来越重。
云原生超级计算机引入第三个 “大脑” —— DPU,旨在帮助构建更快、更高效的系统。DPU 能够卸载安全、通信、存储等需要由现代系统管理的工作。
在传统超级计算机中,运行中的计算任务有时不得不暂停等待 CPU 去处理通信任务,这是业界熟知的一个问题,被称为系统噪声。
在云原生超级计算机中,计算和通信是并行处理的。这就像在高速公路上开设第三条车道一样,能够让所有流量变得更加顺畅。
俄亥俄州立大学 MVAPICH 实验室是 HPC 通信领域的专业机构。该实验室的早期测试显示,在云原生超级计算机执行某些 HPC 作业的速度是传统计算机的 1.4 倍。该实验室还展示,云原生超级计算机实现了计算和通信功能的 100% 重合,这比现有的 HPC 系统高出 99%。
剑桥大学高性能计算总监 Paul Calleja 表示:“我们正在打造欧洲首台科研云原生超级计算机,以提供裸金属性能与云原生 InfiniBand 服务。”
“按照 2020 年 11 月 TOP 500 榜单,这套系统将跻身前 100 名。它将使我们的研究人员能够运用超级计算架构领域的最新成果来充分优化他们的应用。”
HPC 专家正在为云原生超级计算机的进一步发展铺路。
统一通信框架联盟总监 Steve Poole 表示:“由工业界和学术界领先成员组成的 UCF 联盟正在创建实现未来云原生超级计算所需的生产级通信框架和开放标准。”该联盟成员包括来自 Arm、IBM、NVIDIA、美国国家实验室和多所美国大学的代表。
俄亥俄州立大学计算机科学与工程系教授兼网络计算实验室主任 Dhabaleswar K.(DK)Panda 表示:“我们的测试表明,云原生超级计算机的架构效率能够将超级计算机的 HPC 性能提升至新的高度,并实现新的安全功能。”
扫描下方海报二维码,在 GTC21 聆听 NVIDIA 创始人兼首席执行官黄仁勋主题演讲,探索未来计算愿景,共同开启元宇宙之旅。