微信的推送规则进行了调整
如果文章对你有用,请在文末点击“在看”,“分享”和“赞”
在过去的数年间,人工智能技术实现了前所未有的爆发式成长。这主要归功于万物互联的浪潮带来的海量数据、芯片技术革新带来的算力飞跃,以及计算机和数据科学领域对算法的不断优化。这也是我们常说的驱动AI技术发展的三大要素:数据、算力和算法,而且这三大要素是相互促进、缺一不可的。
作为芯片来说,它是承载这三大要素最重要的力量。除了人工智能专用芯片之外,其实很多通用的芯片类型,比如GPU、FPGA,还有中央处理器CPU,都在人工智能时代针对性的进行了架构优化,并且再次焕发新生。
在这篇文章里,我们就以英特尔的至强可扩展处理器为例,一起来看一下在云计算和数据中心领域,CPU在人工智能应用里的独特优势。
至强可扩展处理器的技术特点
2020年6月,英特尔正式发布了第三代至强可扩展处理器(Xeon Scalable Processor),代号为Cooper Lake。
和前一代产品Cascade Lake相比,Cooper Lake单芯片集成了最高28个处理器核心,每个8路服务器平台最高可以支持224个处理器核心。每个核心的基础频率可达3.1GHz,单核最高频率可达4.3GHz。此外它还集成了一些其他的架构升级,比如增强了对传统DDR4内存带宽和容量的支持,并且将英特尔UPI(超级通道互联)的通道数量增加到了6个,将CPU之间的通信带宽和吞吐量提升了一倍,达到20.8GT/s;此外也提升了对硬件安全性、虚拟化、网络连接等等这些数据中心常用技术的硬件支持。
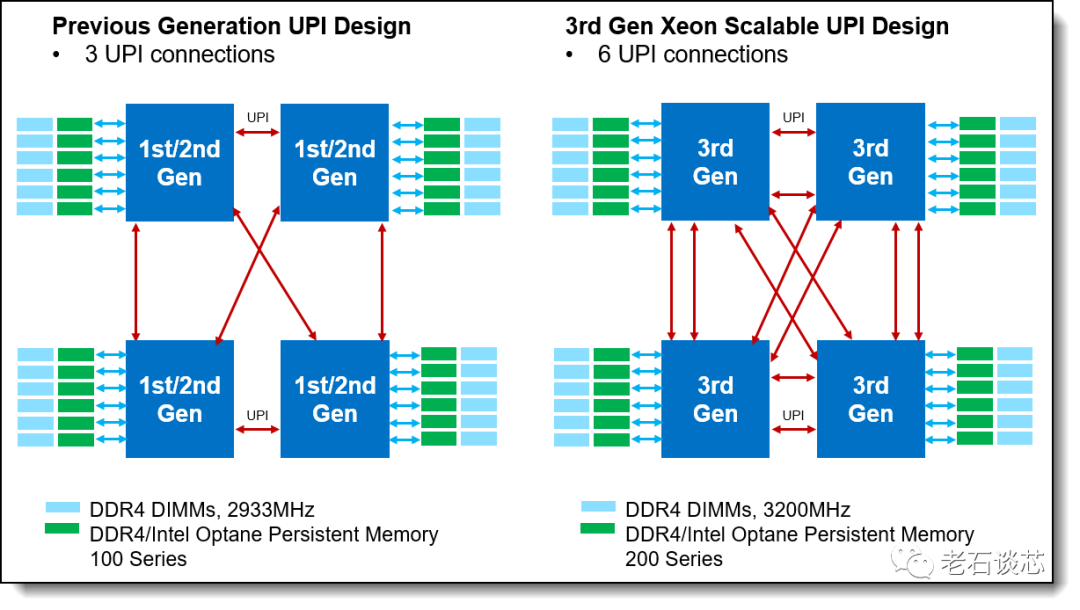
至强可扩展处理器的UPI通道示意图
值得注意的是,这个Cooper Lake是特别针对4路或者8路的服务器产品进行打造的第三代至强可扩展处理器。对于更加常见的单路和双路服务器,英特尔也即将推出代号为Ice Lake的处理器,它将基于英特尔最新的10纳米工艺进行制造,内核采用了Sunny Cove微架构。
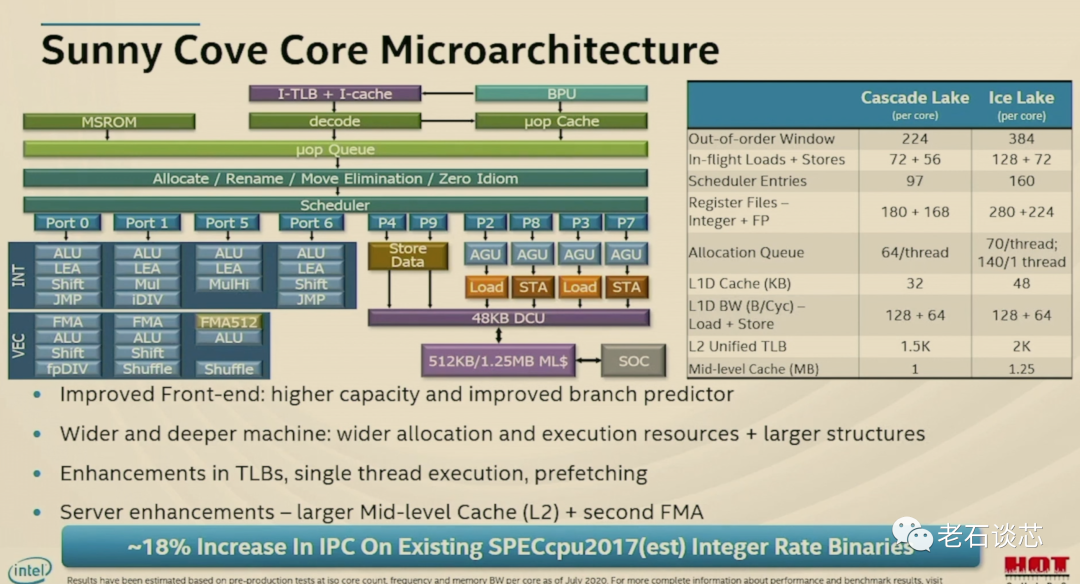
在去年的HotChips大会上,英特尔就对Ice Lake和Sunny Cove微架构做了比较详细的介绍。关于这部分内容,会在今后的文章里继续解读,敬请关注。

Cooper Lake作为英特尔第三代至强可扩展处理器,针对人工智能应用做了特别的架构优化和设计。一个就是在上一代产品的基础上,进一步优化了英特尔的深度学习加速技术DL-Boost,首次引入了对BF16指令集的支持。另外一个就是增加了对第二代英特尔傲腾持久内存、也就是Optane Persistent Memory的支持。接下来我们就具体来看一下为什么这两点提升对于AI应用来说特别的重要。
英特尔深度学习加速技术
首先来看DL-Boost,也就是英特尔的深度学习加速技术。从第二代至强开始,英特尔就在这个CPU里加入了深度学习加速技术,它的核心就是扩展了AVX-512矢量神经网络指令的用途,进一步提升了对AI应用的加速。
AVX-512是一个算力上的加速指令集,它是通过增加数据位宽来处理更多数据的,通过支持512位宽度的数据寄存器,它能在每个时钟周期内进行32次双精度和64次单精度浮点数运算、或者8个64位和16个32位的整数运算。这样的能力本身就可以在CPU上为AI应用提供更好的性能支持,而DL-Boost对它的扩展,目的就是要通过降低数据精度的方式来进一步加速AI应用。
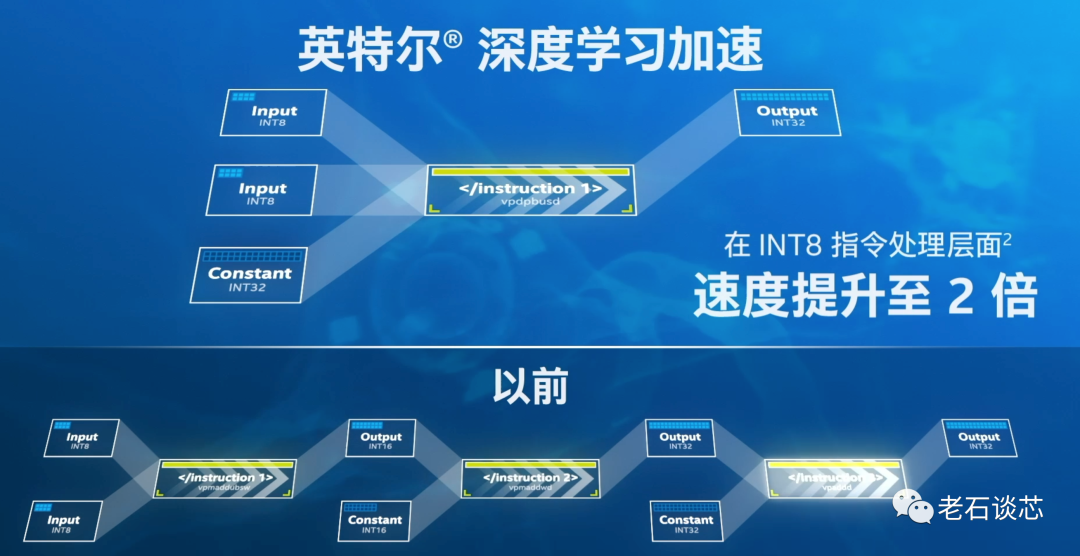
简单来说,DL-Boost的本质有两点,一个是低精度的数据表示不会对深度学习的推理结果和精度造成太大影响,但是会极大的提升硬件性能和效率。第二个就是可以为某些类型的AI应用、比如这里说的推理应用,专门设计更有效的指令集和硬件,来支持这些应用的高效运行。
在深度神经网络应用里使用低精度的数据表示,已经是一个研究比较成熟的领域了。相比使用32位浮点数进行运算,我们可以采用更低的数据精度,甚至也可以采用整形数来进行运算。
有很多研究表明,当使用16位乘法器与32位累加器进行训练和推理时,对准确性几乎没有影响。当使用8位乘法器与32位累加器进行推理计算时,对准确性的影响也非常小。比如对于很多应用来说、特别是涉及我们人类感官的应用,比如看一个图片或者听一段声音等等,由于我们人类的感知能力并没有那么精确,所以推理精确度的稍许差别并没有太大关系。
但是降低数据精度会对AI芯片的设计和性能带来很多的好处,比如可以在芯片面积不变的情况下,大幅提升运算单元的数量,或者在性能要求不变的情况下,采用更少的芯片面积,从而降低功耗。此外这样也会减少数据传输的数据量,节约了带宽,提升了吞吐量。
基于这个理论,也衍生出了很多非常有趣的AI芯片架构设计,比如一sa些AI专用芯片,还有之前介绍过的英特尔Stratix10 NX FPGA等等,都加入了对不同的数据精度的硬件支持,对于至强可扩展处理器来说也是如此。在第二代至强可扩展处理器里,深度学习加速技术第一次出现,主打INT8的加速,主攻的是推理加速。从第三代至强可扩展处理器开始,英特尔又在DL-Boost技术里引入了对BF16的硬件支持,兼顾推理和训练的加速。
和8位整形数相比,BF16的精度更高,而且有着大得多的动态范围。和32位浮点数相比,BF16虽然精度有所损失,但损失并不多,动态范围类似,但所需数据位宽要小很多。可以说BF16这种数据表示,可以在精度、面积、性能等衡量标准里取得非常好的折中,这也是为什么要在第三代至强可扩展处理器里支持这种数据表示的主要原因。
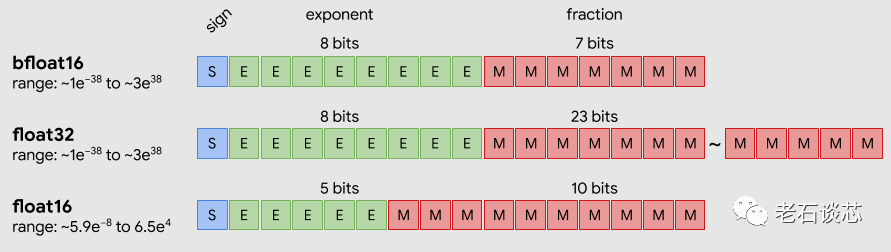
BF16和浮点数数据格式的对比
和前一代CPU搭配32位浮点数的组合相比,第三代至强可扩展处理器加上BF16加速后的AI推理性能可提升到它的1.9倍,训练性能可提升到它的1.93倍。

当然了,业界已经有很多公司在使用和部署第三代至强可扩展处理器,以及前面介绍的深度学习加速技术。比如阿里云就利用对BF16的支持,将BERT模型推理的性能提升到原来的1.8倍以上,并且没有准确率下降。Facebook也将英特尔深度学习加速技术用在了它的深度学习推荐模型里,结果对INT8的加速带来了推理性能提升达2.8倍的成绩,BF16加速则让训练性能提升达到了原来的1.6倍以上。
高性能存储技术:傲腾Optane内存
说完数据的计算,我们接下来再来看看数据的存储。设计芯片的一个大的原则,就是存储数据的地方离使用数据的地方越近,性能就越高、功耗也越低。对于人工智能应用来说,不管是对于训练还是推理,都需要对大量的数据进行处理。这一方面需要有大容量的存储技术作支持,另一方面也需要更大的内存带宽、以及更快的数据传输速度。
总体来说,我们在计算机系统里常见的存储器类型可以分成这么几个类型。一个是DRAM,也就是我们常说的内存,它的性能最高、数据读写的延时最低,但是容量十分有限、价格昂贵,更重要的是一旦断电,DRAM里的数据就会丢失。
相比之下,像机械硬盘、固态硬盘之类的存储方式,虽然容量够大、价格便宜,而且具备数据持久性,但是最大的问题就是访问速度相比DRAM来说要慢几个量级。
所以,很自然的我们就会想,能否有另外一个量大实惠的存储方式,既能有大容量、低延时、也能保证数据的持久性、而且价格也可以接受呢?一个可行的方案,就是英特尔的傲腾Optane持久内存。它既有大的容量、又能保证数据的持久性,也能提供快速的数据读写性能。傲腾持久内存目前单条容量最高可以到512GB,并且和传统DDR4内存的插槽兼容。当搭配第三代至强可扩展处理器使用的时候,单路内存总容量最高可以达到4.5TB,远大于普通的DRAM内存。
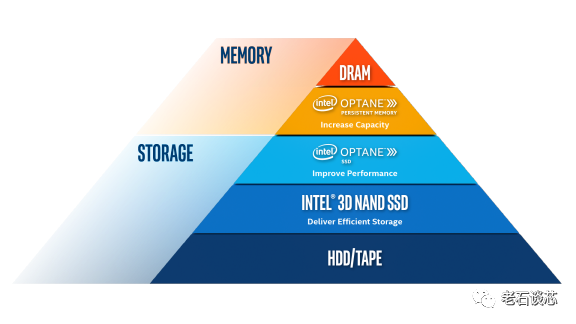
数据中心存储架构层级
值得注意的是,傲腾有多种工作模式。比如它可以作为内存模式使用,这时它就和DRAM没有本质区别,相当于对系统内存进行了扩展。它还有一个叫做App Direct的模式,可以实现较大内存容量和数据持久性,这样软件可以将DRAM和傲腾作为内存的两层进行访问。
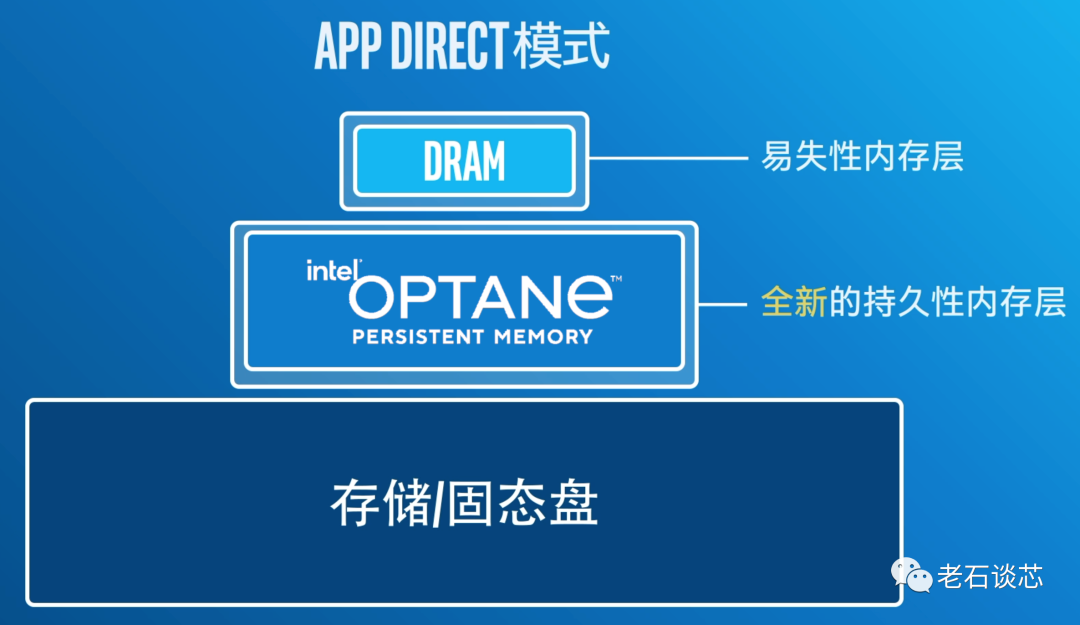
此外,硬盘之类的存储设备是按块读写数据,而傲腾持久内存是可以按字节进行寻址的,这就保证了数据读写的效率和性能。
软件框架和生态系统
说完了对数据进行计算和存储的硬件,最后我们再来看看软件,以及围绕软硬件搭建的生态系统。不管是什么芯片、什么应用场景,最终使用它的都是开发者,是人。所以开发软件和生态是芯片设计中非常重要的环节。
英特尔有一个名叫Analytic Zoo的开源平台,它将大数据分析、人工智能应用,包括数据的处理、模型的训练和推理等过程进行了的整合。它可以把 TensorFlow、Pytorch、OpenVINO这些框架、开发工具和软件集成到一个统一的,基于SPARK、Ray、Flink等搭建的大数据分析流水线里,用于分布式的训练或预测,这样让用户更方便的构建端到端的深度学习应用。这个分析流水线根据至强处理器进行了深度优化,可以充分利用前面介绍的那些针对AI应用进行的计算和存储架构革新,并且也可以比较方便地进行计算集群的部署和扩展。
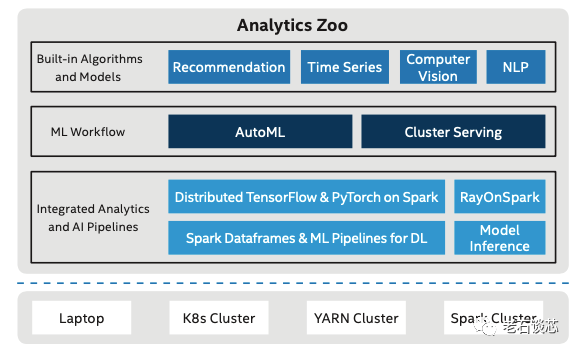
Analytics Zoo架构图
比如,美的就采用了Analytic Zoo来搭建了工业视觉检测的云平台,来加速产品缺陷检测的效率,并且将模型推理的端到端速度提升了16倍。
作为构建广泛生态系统的一部分,英特尔硬件产品方面除了有至强可扩展处理器和傲腾持久内存,还有基于Xe架构的数据中心专用GPU系列、还有现场可编程芯片FPGA、以及一系列的人工智能专用芯片,比如旗下Habana Labs用于训练和推理的Gaudi和Goya系列产品等等。

之前介绍摩尔定律的时候我们说过,晶体管尺寸每缩小10倍,就会衍生出一种全新的计算模式。现任英特尔芯片总架构师的Raja Koduri就把现在的计算模式分成了标量计算、向量计算、矩阵计算和空间计算四大类,分别对应基于CPU、GPU、AI ASIC和FPGA。而目前业界也只有英特尔完成了对这四大类计算模式的芯片全覆盖。
近期热文推荐:
IC人有奖问卷调查(无记名)实时抽奖,600份好礼!
英特尔将为全球代工,台积电股价大跌!130万元/颗!毅力号火星车CPU曝光:250纳米工艺、23年旧架构、主频仅233M
瑞萨芯片工厂突发大火!车用芯片雪上加霜!她研究白酒被提名院士!而她是半导体顶级专家,却四次被拒!
华为败诉!汇丰:很高兴高等法院同意我们的立场
一声叹息!外媒:华为失去了智能手机的桂冠,可能再也无法回归
世界最大、最复杂的GPU!这颗集成1000亿个晶体管的芯片长什么样?
为何这个小小的仅1美元的芯片可能会引发全球经济危机?
