为啥内核有的变量没有初始化就敢直接使用?
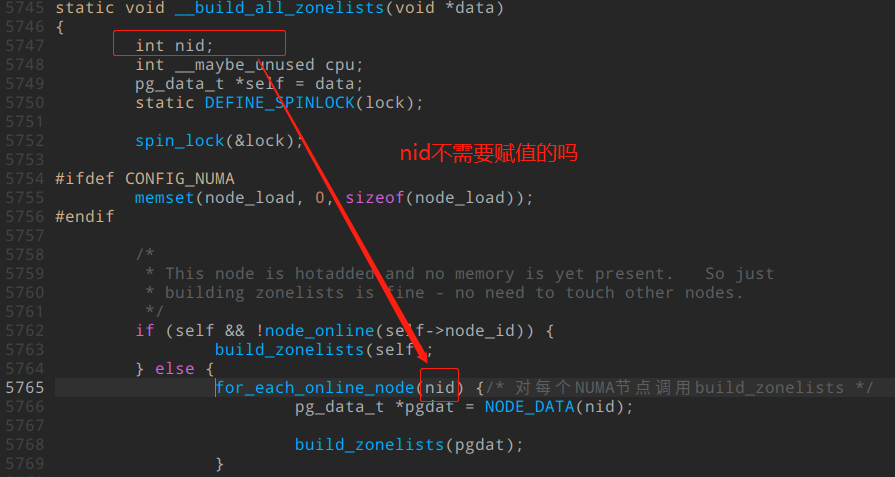
看上图,其中的5747行的变量nid的确没有定义,就直接使用了,这么做没有问题吗?
其实大家仔细看一下,5765行是一个宏,
到内核源码去找该宏的定义:linux-3.14\include\linux\Nodemask.h
#define for_each_online_node(node) for_each_node_state(node, N_ONLINE)
其中的for_each_node_state又是一个宏, 继续跟踪该宏,有两处定义
408 #if MAX_NUMNODES > 1
……
429 #define for_each_node_state(__node, __state) \
430 for_each_node_mask((__node), node_states[__state])
……
450 #else
……
470 #define for_each_node_state(node, __state) \
471 for ( (node) = 0; (node) == 0; (node) = 1)
……
481 #endif
究竟是哪一个定义,由条件#if MAX_NUMNODES > 1 来决定,
#ifdef CONFIG_NODES_SHIFT
#define NODES_SHIFT CONFIG_NODES_SHIFT
#else
#define NODES_SHIFT 0
#endif
#define MAX_NUMNODES (1 << NODES_SHIFT)
因为CONFIG_NODES_SHIFT没有定义【可以检索一下内核,找不到该宏的定义】,所以NODES_SHIFT 为0
所以 MAX_NUMNODES 为1;
所以 for_each_node_state 定义如下:
470 #define for_each_node_state(node, __state) \
471 for ( (node) = 0; (node) == 0; (node) = 1)
而此处的 node 对应 粉丝截图的nid, __state 对应 N_ONLINE
所以5765行代码,可以展开为
for ( (nid) = 0; (nid) == 0; (nid) = 1)
可见,nid被定义了。
宏定义是一个给定名称的代码片段,当我们使用这个名称的时候,预处理器会自动将其替换为宏定义的内容。宏定义有两种,一种是object-like宏定义,在使用的时候相当于一个数据对象;另一种是function-like,在使用的时候就像调用函数那样。
宏展开会使源程序变长,但是宏展开发生在编译过程中,不占运行时间,只占编译时间。
宏展开因为在预处理阶段发生,不会分配内存。
编译c源程序的过程:
宏替换发生在编译预处理阶段。
预处理产生编译器的输出,实现功能如下
把#include中包含的内容拓展为文件的正文,即找到.h文件,同时展开到#include所在处
根据#if和#ifdef等编译命令,将源程序文件中的部分包含进来,部分排除,排除在外的一般转换为空行
将对宏的调用展开成相对应的宏定义
关于宏定义还有很多其他的知识点,本文暂不深入展开。
linux内核中通常有很多宏定义,非常的复杂,对于初学者来说,经常会一头雾水,那如何快速理解宏定义呢?
一口君教你一个非常方便的方法,让你直接看透宏定义, 我们以上述代码为例:
如该例所示,MAX_NUMNODES 就被嵌套了多级, 最终宏CONFIG_NODES_SHIFT在内核中没有检索到,所以该宏没有定义。
文件如下:123.c
1
2
3 #ifdef CONFIG_NODES_SHIFT
4 #define NODES_SHIFT CONFIG_NODES_SHIFT
5 #else
6 #define NODES_SHIFT 0
7 #endif
8
9
10
11 #define MAX_NUMNODES (1 << NODES_SHIFT)
12
13
14
15
16 #if MAX_NUMNODES > 1
17 #define for_each_node_state(__node, __state) \
18 for_each_node_mask((__node), node_states[__state])
19 #else
20 #define for_each_node_state(node, __state) \
21 for ( (node) = 0; (node) == 0; (node) = 1)
22 #endif
23
24
25
26
27 #define for_each_online_node(node) for_each_node_state(node, N_ONLINE)
28
29
30 static int __build_all_zonelists(void *data)
31 {
32 int nid;
33 int cpu;
34 pg_data_t *self = data;
35
36
37
38 for_each_online_node(nid) {
39 pg_data_t *pgdat = NODE_DATA(nid);
40
41 build_zonelists(pgdat);
42 build_zonelist_cache(pgdat);
43 }
44 }
使用以下命令,展开宏定义,
gcc -E
-E的含义是,编译预处理该文件,但是不去生成汇编代码,只把文件中的宏定义以及包含的头文件替代,并不会去检查语法正确与否。
结果如下:
peng@ubuntu:~/test$ gcc 123.c -E
# 1 "123.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "123.c"
# 28 "123.c"
static int __build_all_zonelists(void *data)
{
int nid;
int cpu;
pg_data_t *self = data;
for ( (nid) = 0; (nid) == 0; (nid) = 1) {
pg_data_t *pgdat = NODE_DATA(nid);
build_zonelists(pgdat);
build_zonelist_cache(pgdat);
}
}
由结果可知, nid是被赋值为0的。
我们来做一个练习,展开一下内核的waite_event()这个宏
拷贝用到所有宏定义到c文件中。
wait.c
1
2 #define ___wait_event(wq, condition, state, exclusive, ret, cmd) \
3 ({ \
4 __label__ __out; \
5 wait_queue_t __wait; \
6 long __ret = ret; \
7 \
8 INIT_LIST_HEAD(&__wait.task_list); \
9 if (exclusive) \
10 __wait.flags = WQ_FLAG_EXCLUSIVE; \
11 else\
12 {\
13 /* code */ \
14 __wait.flags = 0; \
15 \
16 for (;;) { \
17 long __int = prepare_to_wait_event(&wq, &__wait, state);\
18 \
19 if (condition) \
20 break; \
21 \
22 if (___wait_is_interruptible(state) && __int) { \
23 __ret = __int; \
24 if (exclusive) { \
25 abort_exclusive_wait(&wq, &__wait, \
26 state, NULL); \
27 goto __out; \
28 } \
29 break; \
30 } \
31 \
32 cmd; \
33 } \
34 finish_wait(&wq, &__wait); \
35 __out: __ret; \
36 })\
37 }\
38
39
40
41
42 #define TASK_UNINTERRUPTIBLE 2
43
44
45 #define __wait_event(wq, condition) \
46 (void)___wait_event(wq, condition, TASK_UNINTERRUPTIBLE, 0, 0, \
47 schedule())\
48 \
49 \
50 wait_event(wq, condition) \
51 do { \
52 if (condition) \
53 break; \
54 __wait_event(wq, condition); \
55 } while (0)\
56
57
58
59 test()
60 {
62 wait_event(wq,flag == 0);
64 }
编译与处理结果如下:
root@ubuntu:/home/peng/test# gcc wait.c -E
# 1 "wait.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "wait.c"
# 71 "wait.c"
test()
{
do { if (flag == 0) break; (void)({ __label__ __out; wait_queue_t __wait; long __ret = 0; INIT_LIST_HEAD(&__wait.task_list); if (0) __wait.flags = WQ_FLAG_EXCLUSIVE; else { __wait.flags = 0; for (;;) { long __int = prepare_to_wait_event(&wq, &__wait, 2); if (flag == 0) break; if (___wait_is_interruptible(2) && __int) { __ret = __int; if (0) { abort_exclusive_wait(&wq, &__wait, 2, NULL); goto __out; } break; } schedule(); } finish_wait(&wq, &__wait); __out: __ret; }) }; } while (0);
}
函数test()整理如下:
test(){
do {
if (flag == 0)
break;
(void)(
{
__label__ __out;
wait_queue_t __wait;
long __ret = 0;
INIT_LIST_HEAD(&__wait.task_list);
if (0) __wait.flags = WQ_FLAG_EXCLUSIVE;
else {
__wait.flags = 0;
for (;;)
{
long __int = prepare_to_wait_event(&wq, &__wait, 2);
if (flag == 0)
break;
if (___wait_is_interruptible(2) && __int)
{
__ret = __int;
if (0)
{
abort_exclusive_wait(&wq, &__wait, 2, NULL);
goto __out;
}
break;
}
schedule();
}
finish_wait(&wq, &__wait);
__out:
__ret;
})
};
}while (0);
}
这就是wait_event()最终被替换后的代码,你学会了吗?
数值相关的宏定义
#define IS_LEAP_YEAR(y) (((((y) % 4) == 0) && (((y) % 100) != 0)) \
|| (((y) % 400) == 0))/*判断是否是闰年*/
**MAX 与 MIN ** ;
#define MAX(x, y) (((x) < (y)) ? (y) : (x)) /*两数取最大数*/
#define MIN(x, y) (((x) < (y)) ? (x) : (y)) /*两数取最小数*/
#define BCD2HEX(x) (((x) >> 4) * 10 + ((x) & 0x0F)) /*BCD码转数值, 20H -> 20*/
#define HEX2BCD(x) (((x) % 10) + ((((x) / 10) % 10) << 4)) /*数值转BCD码, 20 -> 20H*/
字符范围判断
/*字符是否在某个区间范围内*/
#define in_range(c, lo, up) ((uint8)c >= lo && (uint8)c <= up)
#define isprint(c) in_range(c, 0x20, 0x7f)
/*十进制内字符*/
#define isdigit(c) in_range(c, '0', '9')
/*十六进制内字符*/
#define isxdigit(c) (isdigit(c) || in_range(c, 'a', 'f') || in_range(c, 'A', 'F'))
/*是否是小写*/
#define islower(c) in_range(c, 'a', 'z')
/*是否是空格*/
#define isspace(c) (c == ' ' || c == '\f' || c == '\n' || c == '\r' || c == '\t' || c == '\v')
/*是否为ASCII码*/
#define isascii(c) ((unsigned) (c) <= 0177)
#define MSB(x) (((x) >> 8) & 0xff) /* x占2byte(如short)2byte的高地址的1byte */
#define LSB(x) ((x) & 0xff) /* x占2byte(如short)2byte的低地址的1byte*/
#define MSW(x) (((x) >> 16) & 0xffff) /* x占4byte(如int) 4byte的高地址的2byte */
#define LSW(x) ((x) & 0xffff)
#define WORDSWAP(x) (MSW(x) | (LSW(x) << 16)) /* x占4byte(如int) 低2字节与高2字节内容交换 */
#define LLSB(x) ((x) & 0xff) /*x占4byte(如int) 取低地址1byte*/
#define LNLSB(x) (((x) >> 8) & 0xff)
#define LNMSB(x) (((x) >> 16) & 0xff)
#define LMSB(x) (((x) >> 24) & 0xff)
/*x占4byte(如int) 4字节逆序*/
#define LONGSWAP(x) ((LLSB(x) << 24) \
|(LNLSB(x) << 16) \
|(LNMSB(x) << 8) \
|(LMSB(x)))
/* 判断某位是否为1 */
#define BIT_IS_1(x,y) (((x)>>(y))&0x01u)
#define SETBITS(x,y,n) (x) = (n) ? ((x)|(1 << (y))) : ((x) &(~(1 << (y))));
/* 给某位置反 */
#define BIT_INVERSE(x,y) ((x)=(x)^(1<<(y)))
/* 字节串中某BIT值*/
#define BIT_OF_BYTES(x, y) (BITS(x[(y)/8], (y)%8))
/* 字节串中设置某BIT为0 */
#define SETBITSTO0_OF_BYTES(x, y) (x[(y)/8]) &= (~(1 << ((y)%8)))
/* 字节串中设置某BIT为1 */
#define SETBITSTO1_OF_BYTES(x, y) (x[(y)/8]) |= (1 << ((y)%8))
/* number of elements in an array */
#define ARRAY_SIZE(a) (sizeof (a) / sizeof ((a)[0]))
/* byte offset of member in structure*/
#define MOFFSET(structure, member) ((int) &(((structure *) 0) -> member))
/* size of a member of a structure */
#define MEMBER_SIZE(structure, member) (sizeof (((structure *) 0) -> member))
/*向上对齐,~(align - 1)为对齐掩码,例如align=8,~(align - 1) = ~7,
(~7)二进制后三位为000,&(~(align - 1)) = &(~7),就是去掉余数,使其能被8整除*/
#define ALIGN_UP(x, align) (((int) (x) + (align - 1)) & ~(align - 1))
/*向下对齐*/
#define ALIGN_DOWN(x, align) ((int)(x) & ~(align - 1))
/*是否对齐*/
#define ALIGNED(x, align) (((int)(x) & (align - 1)) == 0)
/*页面对齐相关的宏,一页为4096字节*/
#define PAGE_SIZE 4096
#define PAGE_MASK (~(PAGE_SIZE-1))
#define PAGE_ALIGN(addr) -(((addr)+PAGE_SIZE-1) & PAGE_MASK)
#ifndef BODY_H //保证只有未包含该头文件才会将其内容展开
#define BODY_H
//头文件内容
#endif
#define MEM_B(x) (*(byte*)(x)) //得到x表示的地址上的一个字节
#define MEM_W(x) (*(word*)(x)) //得到x表示的地址上的一个字
#define OFFSET(type,field) (size_t)&((type*)0->field)
#define FSIZ(type,field) sizeof(((type*)0)->field)
#defien B_PTR(var) ((byte*)(void*)&(var)) //得到字节宽度的地址
#define W_PTR(var) ((word*)(void*)&(var)) //得到字宽度的地址
#define UPCASE(c) (((c) >= "a" && (c) <= "z") ? ((c) - 0x20) : (c) )
#define INC_SAT(val) (val = ((val) +1 > (val)) ? (val) + 1 : (val))
#define ARR_SIZE(a) (sizeof( (a) ) / sizeof(a[0]) ) )
·················· END ··················
点击关注公众号,回复【1024】免费领学习资料
