本文转自:51cto,作者:Matthew Stewart
人工智能(AI)正在加快速度从“云端”走向“边缘”,进入到越来越小的物联网设备中。在终端和边缘侧的微处理器上,实现的机器学习过程,被称为微型机器学习,即TinyML。更准确的说,TinyML是指工程师们在mW功率范围以下的设备上,实现机器学习的方法、工具和技术。
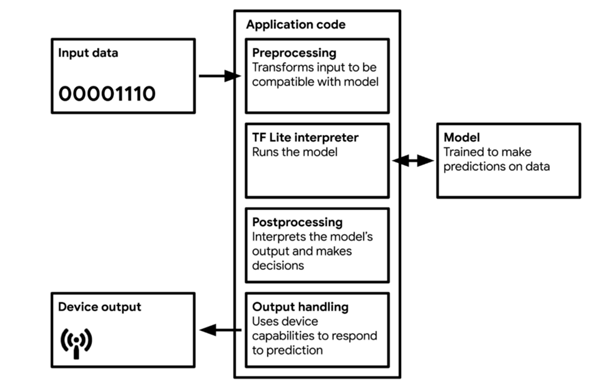
图1 嵌入设备上的TinyML概览图
过去的十年中,由于处理器速度的提高和大数据的出现,我们见证了机器学习算法的规模呈指数级增长。在TinyML 2020 峰会上,英伟达、ARM、高通、谷歌、微软、三星等公司纷纷展示了微型机器学习的最新成果。本次峰会得出了很多重要结论:
TinyML 是机器学习和嵌入式 IoT 设备的交叉领域,是一门新兴的工程学科,具有革新许多行业的潜力。
TinyML的主要受益者,是边缘计算和节能计算领域。TinyML源自物联网IoT的概念。物联网的传统做法,是将数据从本地设备发送到云端处理。一些人对这一方式在隐私、延迟、存储和能源效率等方面存在疑虑。
能源效率:无论通过有线还是无线方式,数据传输都非常耗能,比使用乘积累加运算单元(multiply-accumulate units,MAU)的本机计算高出约一个数量级。最节能的做法,是研发具备本地数据处理能力的物联网系统。相对于“以计算为中心”的云模型,“以数据为中心”的计算思想已得到了人工智能先驱者的一些先期探讨,并已在当前得到了应用。
隐私:数据传输中存在侵犯隐私的隐患。数据可能被恶意行为者拦截,并且存储在云等单个位置中时,数据固有的安全性也会降低。通过将数据大部保留在设备上,可最大程度地减少通信需求,进而提高安全性和隐私性。
存储:许多物联网设备所获取的大部分数据是毫无用处的。想象一下,一台安防摄像机每天 24 小时不间断地记录着建筑物的入口情况。在一天的大部分时间中,该摄像机并没有发挥任何作用,因为并没有什么异常情况发生。采用仅在必要时激活的更智能的系统,可降低对存储容量的需求,进而降低需传输到云端的数据量。
延迟:标准的物联网设备,例如 Amazon Alexa,需将数据传输到云来处理,然后由算法的输出给出响应。从这个意义上讲,设备只是云模型的一个便捷网关,类似于和 Amazon 服务器之间的信鸽。设备本身并非智能的,响应速度完全取决于互联网性能。如果网速很慢,那么 Amazon Alexa 的响应也会变慢。自带自动语音识别功能的智能 IoT 设备,由于降低甚至是完全消除了对外部通信的依赖,因此降低了延迟。
上述问题推动着边缘计算的发展。边缘计算的理念就是在部署在云“边缘”的设备上实现数据处理功能。这些边缘设备在内存、计算和功能方面都高度受限于设备自身的资源,进而需要研发更为高效的算法、数据结构和计算方法。
此类改进同样适用于规模较大的模型,在不降低模型准确率(accuracy)的同时,实现机器学习模型效率数个数量级的提高。例如,Microsoft开发的Bonsai算法可小到2 KB,但比通常40MB的kNN算法或是4MB的神经网络具有更好的性能。这个结果听上去可能无感,但如果换句话说——在规模缩小了一万倍的模型上取得同样的准确率,这就十分令人印象深刻了。规模如此小的模型,可以运行在2KB内存的Arduino Uno上。简而言之,现在可以在售价5美元的微控制器上构建此类机器学习模型。
机器学习正处于一个交叉路口,两种计算范式齐头并进,即以计算为中心的计算,和以数据为中心的计算。
在以计算为中心的计算范式下,数据是在数据中心的实例上存储和分析的;而在以数据为中心的计算范式下,处理是在数据的原始位置执行的。
尽管在目前,以计算为中心的计算范式似乎很快会达到上限,但是以数据为中心的计算范式才刚刚起步。
当前,物联网设备和嵌入式机器学习模型日益普及。人们可能并未注意到其中许多设备,例如智能门铃、智能恒温器,以及只要用户说话甚至拿起就可以“唤醒”的智能手机。
下面将深入介绍 TinyML 的工作机制,以及在当前和将来的应用情况。
关键字发现:大多数人已经非常熟悉此应用,例如“你好,Siri”和“你好,Google”等关键字,通常也称为“热词”或“唤醒词”。设备会连续监听来自麦克风的音频输入,训练实现仅响应与所学关键字匹配的特定声音序列。这些设备比自动语音识别(automatic speech recognition,ASR)更简单,使用更少的资源。Google智能手机等设备还使用了级联架构实现扬声器的验证,以确保安全性。
视觉唤醒词:视觉唤醒词使用图像类似替代唤醒词的功能,通过对图像做二分类表示存在与否。例如,设计一个智能照明系统,在检测到人的存在时启动,并在人离开时关闭。同样,野生动物摄影师可以使用视觉唤醒功能在特定的动物出现时启动拍摄,安防摄像机可以在检测到人活动时启动拍摄。
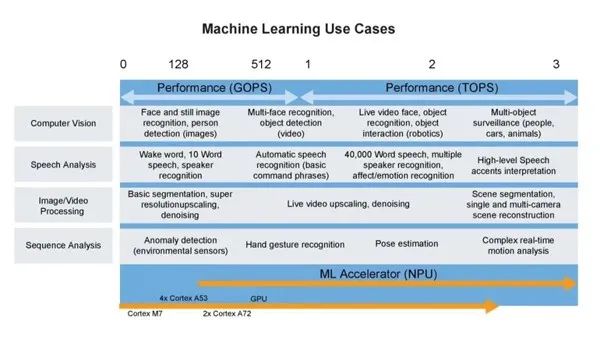
下图全面展示当前TinyML机器学习的应用概览。
图3 TinyML 的机器学习用例(图片来源:NXP)
TinyML 算法的工作机制与传统机器学习模型几乎完全相同,通常在用户计算机或云中完成模型的训练。训练后处理是TinyML真正发挥作用之处,通常称为“深度压缩”(deep compression)。

图4 深度压缩示意图(来源:[ArXiv 论文](https://arxiv.org/pdf/1510.00149.pdf))
模型在训练后需要更改,以创建更紧凑的表示形式。这一过程的主要实现技术包括剪枝(pruning)和知识蒸馏。
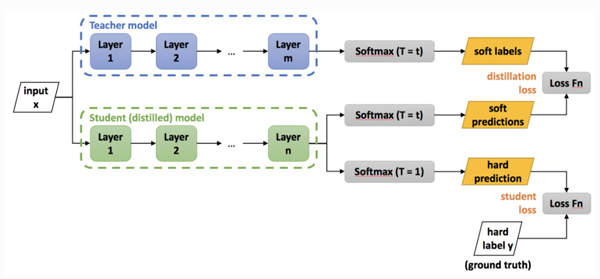
知识蒸馏的基本理念,是考虑到较大网络内部存在的稀疏性或冗余性。虽然大规模网络具有较高的表示能力,但如果网络容量未达到饱和,则可以用具有较低表示能力的较小网络(即较少的神经元)表示。在 Hinton 等人 2015 年发表的研究工作中,将 Teacher 模型中转移给 Student 模型的嵌入信息称为“黑暗知识”(dark knowledge)。
下图给出了知识蒸馏的过程:
图中Teacher模型是经过训练的卷积神经网络模型,任务是将其“知识”转移给称为Student 模型的,参数较少的小规模卷积网络模型。此过程称为“知识蒸馏”,用于将相同的知识包含在规模较小的网络中,从而实现一种网络压缩方式,以便用于更多内存受限的设备上。
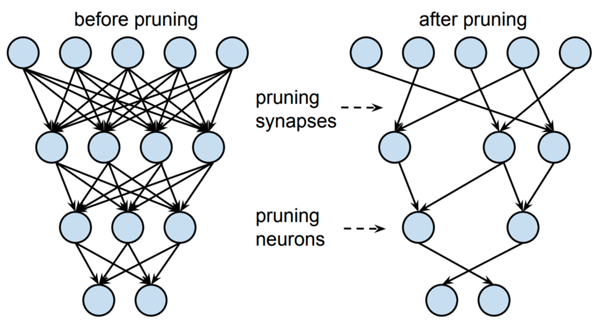
同样,剪枝有助于实现更紧凑的模型表示。宽泛而言,剪枝力图删除对输出预测几乎无用的神经元。这一过程通常涉及较小的神经权重,而较大的权重由于在推理过程中具有较高的重要性而会得到保留。随后,可在剪枝后的架构上对网络做重新训练,调优输出。
蒸馏后的模型,需对此后的训练进行量化,形成兼容嵌入式设备架构的格式。
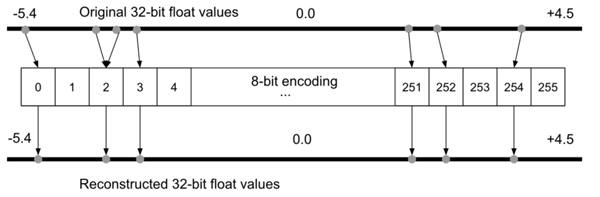
为什么要做量化?假定对于一台Arduino Uno,使用8位数值运算的ATmega328P微控制器。在理想情况下要在Uno上运行模型,不同于许多台式机和笔记本电脑使用32位或64位浮点表示,模型的权重必须以8位整数值存储。通过对模型做量化处理,权重的存储规模将减少到1/4,即从32位量化到8位,而准确率受到的影响很小,通常约1-3%。
图7 8 位编码过程中的量化误差示意图(图片来源:《[TinyML](https://tinymlbook.com/)》一书)
由于存在量化误差,可能会在量化过程中丢失某些信息。例如在基于整型的平台上,值为3.42的浮点表示形式可能会被截取为3。为了解决这个问题,有研究提出了量化可感知(quantization-aware,QA)训练作为替代方案。QA训练本质上是在训练过程中,限制网络仅使用量化设备可用的值。
编码是可选步骤。编码通过最有效的方式来存储数据,可进一步减小模型规模。通常使用著名的 霍夫曼编码。
对模型量化和编码后,需将模型转换为可被轻量级网络解释器解释的格式,其中最广为使用的就是TF Lite(约500 KB大小)和TF Lite Micro(约20 KB)。模型将编译为可被大多数微控制器使用并可有效利用内存的C 或C++ 代码,由设备上的解释器运行。
图8 TinyML 应用的工作流图(来源:Pete Warden 和 Daniel Situnayake 编写的《[TinyML](https://tinymlbook.com/)》一书)
大多数TinyML技术,针对的是处理微控制器所导致的复杂性。TF Lite和TF Lite Micro非常小,是因为其中删除了所有非必要的功能。不幸的是,它们同时也删除了一些有用的功能,例如调试和可视化。这意味着,如果在部署过程中出现错误,可能很难判别原因。
在设备上进行训练会引入额外的复杂性。由于数值精度的降低,要确保网络训练所需的足够准确率是极为困难的。在标准台式计算机的精度下,自动微分方法是大体准确的。计算导数的精度可达令人难以置信的10^{-16},但是在8 位数值上做自动微分,将给出精度较差的结果。在反向传播过程中,会组合使用求导并最终用于更新神经参数。在如此低的数值精度下,模型的准确率可能很差。
尽管存在上述问题,一些神经网络还是使用了 16 位和 8 位浮点数做了训练。
可以通过定制模型,提高模型的计算效率。一个很好的例子就是MobileNet V1 和MobileNet V2,它们是已在移动设备上得到广泛部署的模型架构,本质上是一种通过重组(recast)实现更高计算效率卷积运算的卷积神经网络。这种更有效的卷积形式,称为深度可分离卷积结构(depthwiseseparable convolution)。针对架构延迟的优化,还可以使用基于硬件的概要(hardware-based profiling)和神经架构搜索(neural architecture search)等技术。
在资源受限的设备上运行机器学习模型,为许多新的应用打开了大门。使标准的机器学习更加节能的技术进步,将有助于消除数据科学对环境影响的一些担忧。此外,TinyML支持嵌入式设备搭载基于数据驱动算法的全新智能,进而应用在了从 预防性维护 到 检测森林中的鸟叫声 等多种场景中。
尽管继续扩大模型的规模是一些机器学习从业者的坚定方向,但面向内存、计算和能源效率更高的机器学习算法发展也是一个新的趋势。TinyML仍处于起步阶段,在该方向上的专家很少。该方向正在快速增长,并将在未来几年内,成为人工智能在工业领域的重要新应用。
为什么要介绍TinyML?因为TinyML 是在海量的物联网设备端微控制器上实现的人工智能,有望在未来几年内,成为人工智能在工业领域的重要新应用;而且我们接下来活动的Arduino板卡
,可在其上进行TinyML的项目开发,所以今天先了解
TinyML,接下来将会有不同的项目分享。
交流群已为大家准备好,接下来硬禾老师将带领大家入门Arduino开发板,请扫描下方二维码入群。若群二维码过期,可在“硬禾学堂”公众号回复关键词“Arduino”加入群聊。
硬禾团队一直致力于给电子工程师和相关专业的同学,带来规范的核心技能课程,帮助大家在学习和工作的各个阶段,都能有效地提升自己的职业能力。