第一章
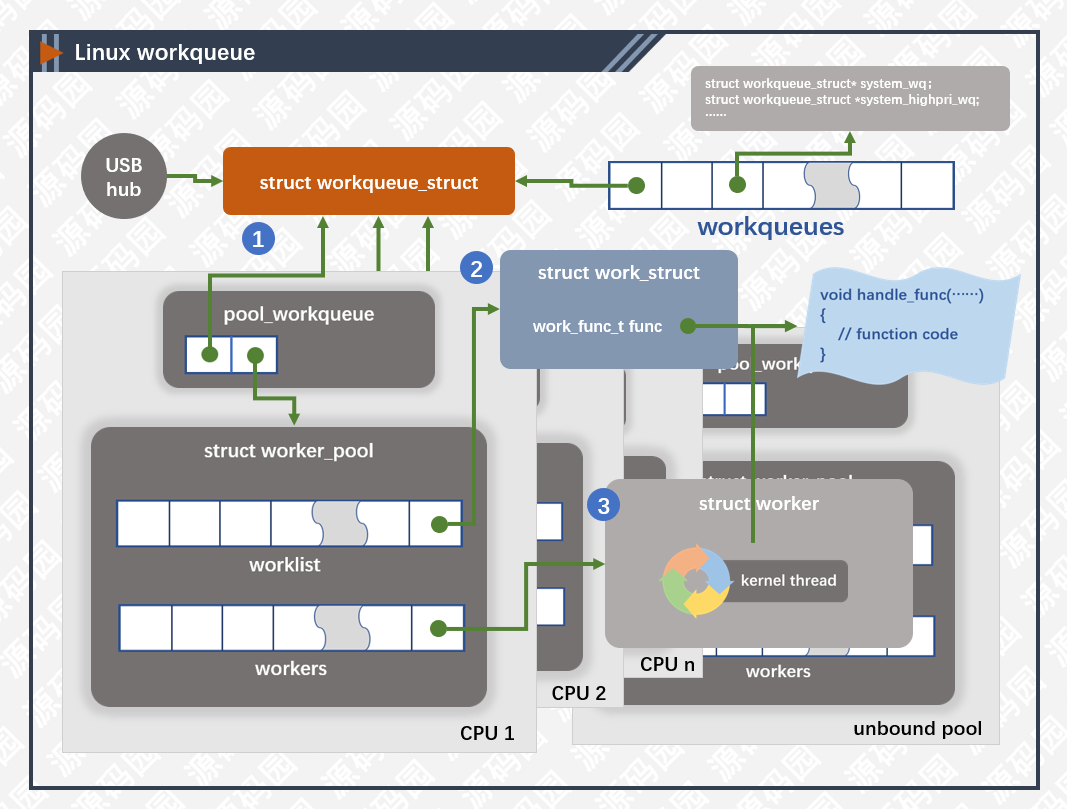
Linux工作队列(workqueue)是内核异步处理机制中的一种,通过内核线程实现,它在进程的上下文中运行,可以重新调度和睡眠。内核线程用线程池进行管理能更加有效的利用资源,经常用于执行中断的下半部程序。现在,我们从一个驱动模块的角度分析工作队列的应用场景,包括队列的创建,工作初始化,工作入队列等。
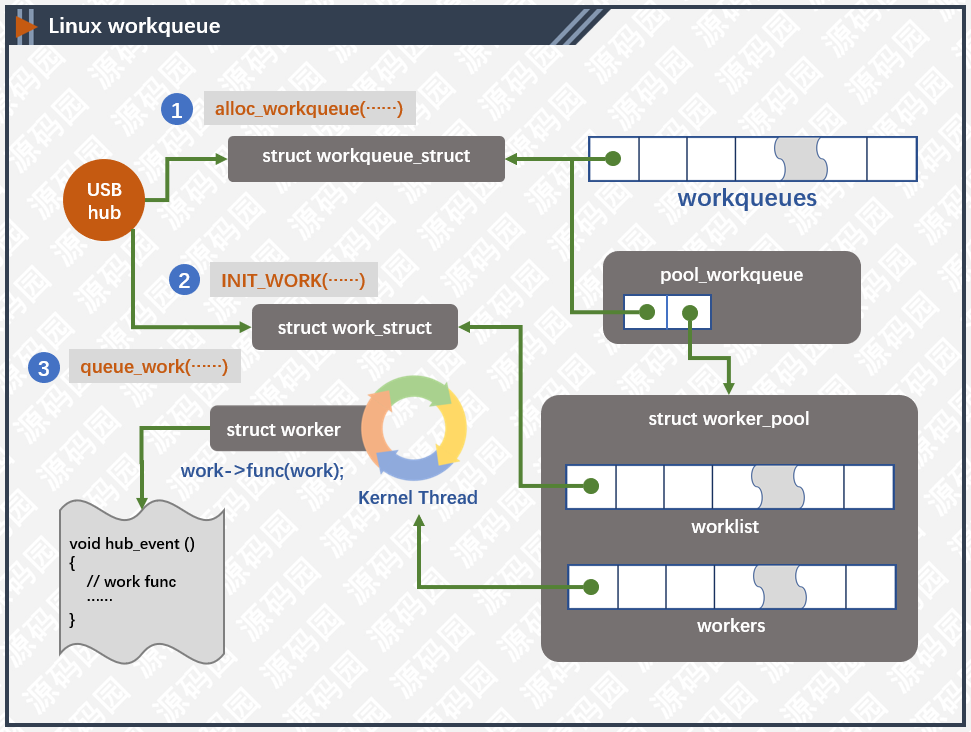
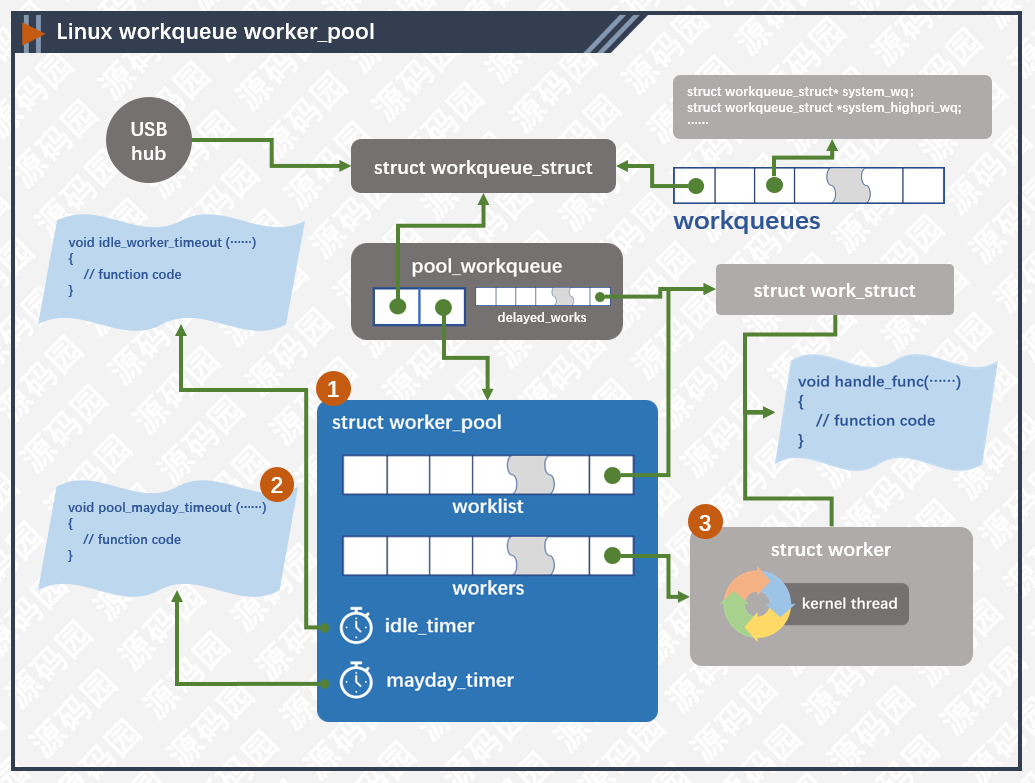
上图显示了工作队列的基本结构,我们以USB Hub驱动为例,分析驱动如何使用工作队列。
创建队列
USB控制器通过外部中断与CPU进行异步通讯,由于中断对时间的要求特别敏感,所以USB驱动把主要的工作放在工作队列中处理,这样一来可以有效的提高系统的响应能力。要使用工作队列,第一步,先创建一个队列,创建的函数如下所示:
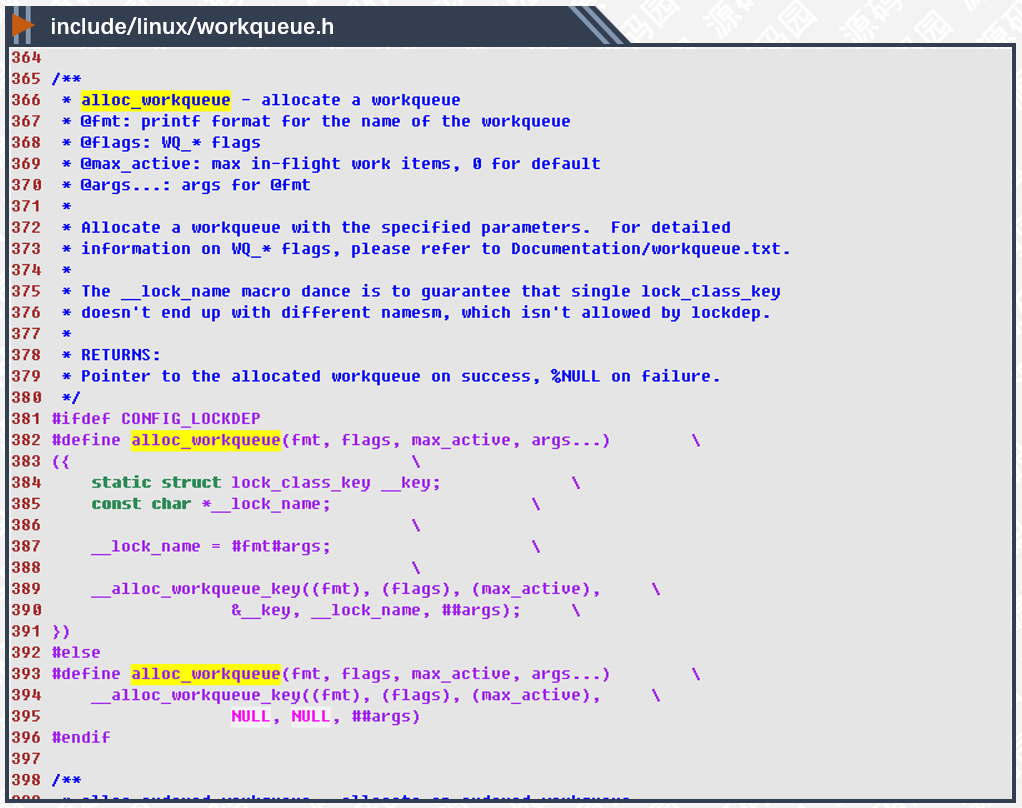
allow_workqueue()是创建队列的宏,负责创建一个新的队列,不管有没有定义CONFIG_LOCKDEP最终通过__alloc_workqueue_key()实现。参数的解析我们放到后文再说,先看看hub模块如何创建队列:

USB hub模块在初始化的时候先注册hub驱动,接着创建工作队列。
5272行,创建全局唯一hub_wq队列,参数WQ_FREEZABLE表示工作线程在挂起时候,需要先完成当前队列的所以工作任务之后才能挂起。创建好队列后,需要定义一个任务用于完成实际的工作。
初始化任务
工作队列创建成功后工作任务就有了栖身之所,以后只要往队列里添加任务就可以异步执行了。像USB hub这种公共型的模块,工作任务都是反复执行的,所以初始化一个struct work_struct实例即可。
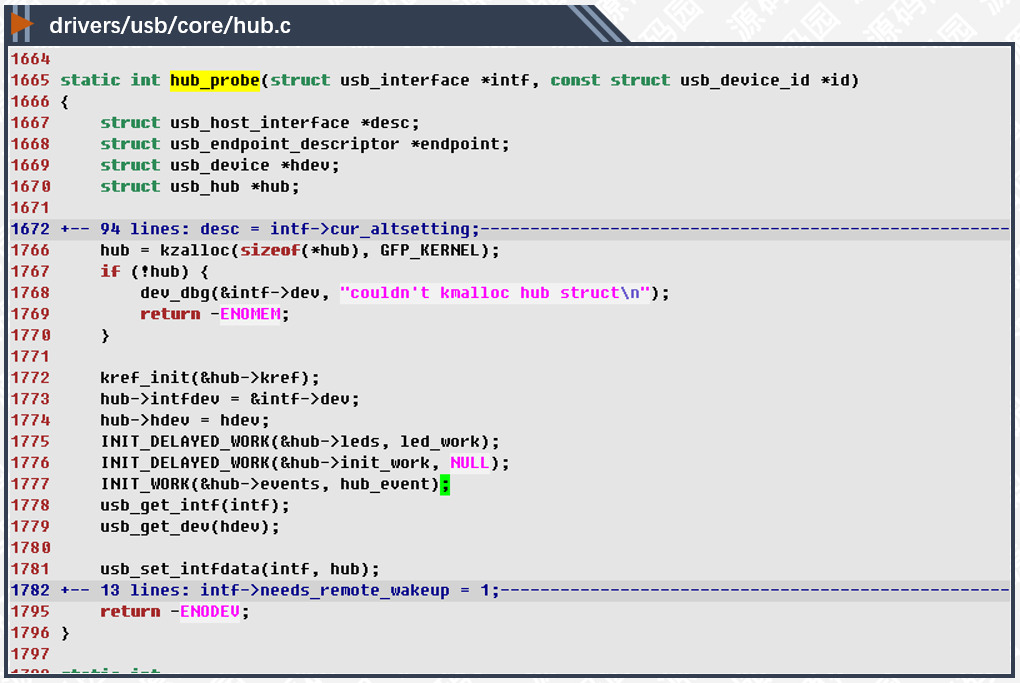
hub_probe函数在发现hub设备的时候由内核调用,用于初始化hub设备对象。
1766行,分配hub设备对象空间,然后进行一系列初始化。USB驱动的逻辑比较复杂,我们另文分析。
1777行,初始化工作任务,work_struct实例最重要的成员就是func函数指针,这里把此指针初始化为hub_event()函数。
通过以上两个步骤,工作队列就可以使用了,是不是很简单呢?接下来,我们看看hub是如何触发工作任务的。
工作入队列
CPU收到USB中断事件后,在中断的上半部通过hub_irq()处理,这个过程对时间要求比较敏感,所以处理完关键的工作后就把剩余的工作交给工作队列来处理。
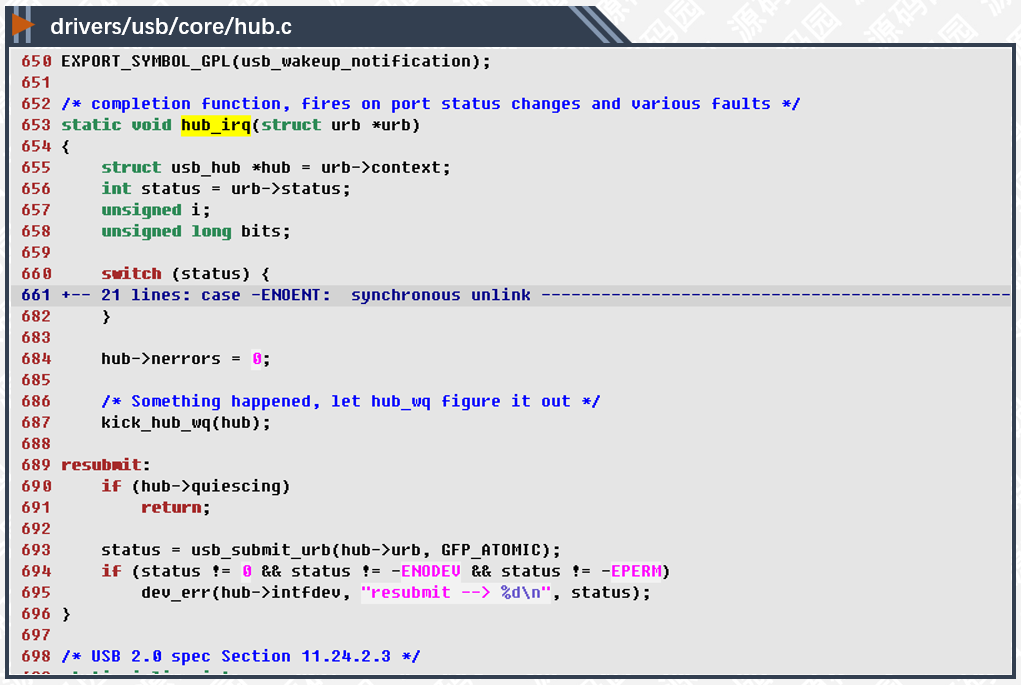
687行,踢工作队列一脚,触发工作队列的任务。从上一行注释中可以看到,内核收到了一些USB事件,但现在还不知道是什么内容,由于时间紧迫,把它交给工作队列异步处理。kick_hub_wq()函数实现如下:
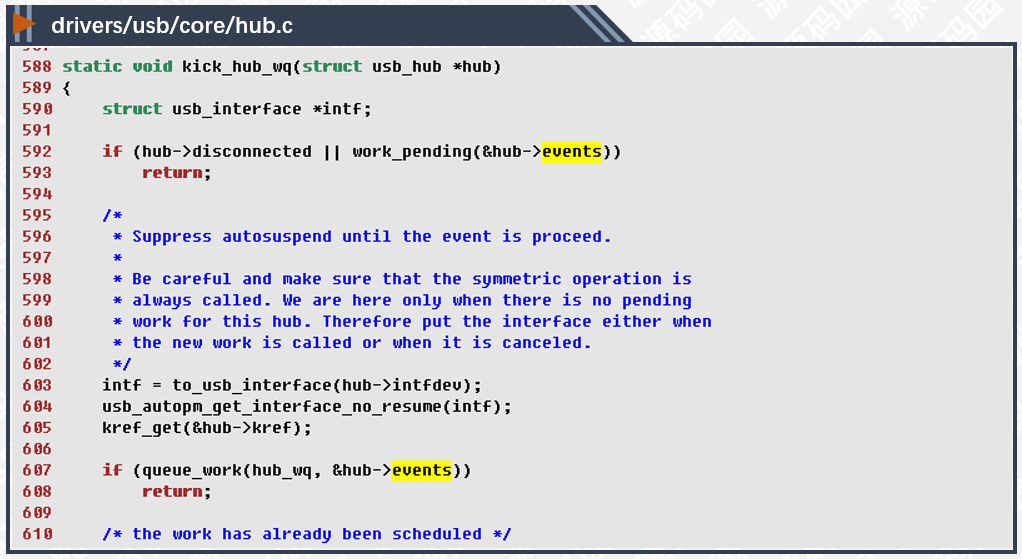
607行,把work_struct对象入队列,此函数一经成功调用,同一个对象将不能重复入队列,只有等工作对象执行完毕后(即从hub_event函数中返回后),才能再次入队列。由于USB的事件会不断地发生,这样可以有效的避免函数重入的问题,也就是说不会有多个处理函数同时在不同的CPU上调度执行。
以上就是USB Hub驱动使用工作队列的例子,之后我们再另文分析工作队列的创建,管理,及相关线程的调度。(armv8, kernel4.4)
第二章
前文我们讲了USB Hub使用工作队列的例子,一个模块通过创建队列,初始化任务,任务入队列三个接口就可以使用它。这篇文章我们分析一下工作队列接口的实现及相关对象之间的关系。
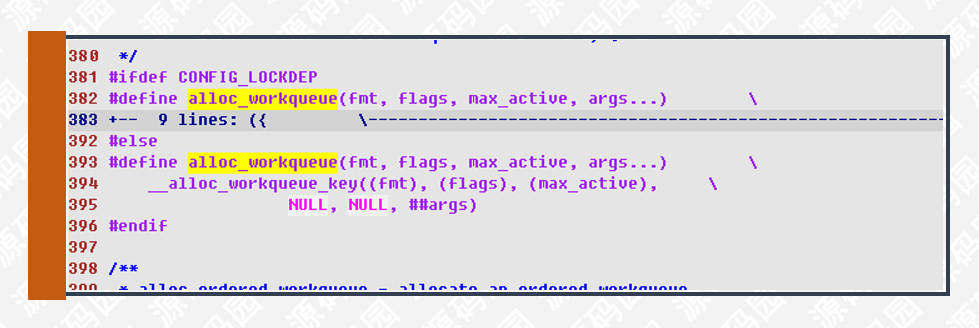
工作队列(workqueue_struct)保存了相关的参数,列表,及与线程池之间的关系。通过alloc_workqueue宏创建,代码如下图所示:
alloc_workqueue宏最终调用__alloc_workqueue_key()实现:
这个函数的代码比较长,如果每一行都解析不知道如何下手,也没有必要,所以我只显示了骨干代码,其他的都折叠起来了,这样有助于我们理解主要流程。在创建workqueue_struct的的时候,主要实现分配空间及初始化、分配pool_workqueue对象并连接到线程池。
3853-3879行,分配workqueue_struct对象空间,分配的时候指定GFP_KERNEL参数,说明内存不足的时候有可能会造成睡眠,所以不宜在中断上下文中使用。分配成功后,设置相关的属性,初始化pwq列表,mayday列表等,这些参数都是在任务调度的时候用到的,调度的细节我们另文分析。
分配pool_workqueue对象并连接到线程池
pool_workqueue对象是连接工作队列(workqueue_struct)与线程池(worker_pool)的对象。我们先说一下线程池,在Linux内核中,worker_pool主要分为两种,一种和CPU绑定,另一种不和CPU绑定。和CPU绑定中的线程只在绑定的CPU上运行,这对CPU亲缘性及局部热缓存有帮助;不和CPU绑定的线程管理比较灵活,可以在任何一个CPU中运行,对平衡CPU性能有帮助,但在切换线程上下文的时候会引起缓存失效。内核启动时候给每个CPU创建两个线程池,一个高优先级,一个低优先级,然后再创建两个非绑定的线程池。pool_workqueue负责把工作队列和线程池连接起来。
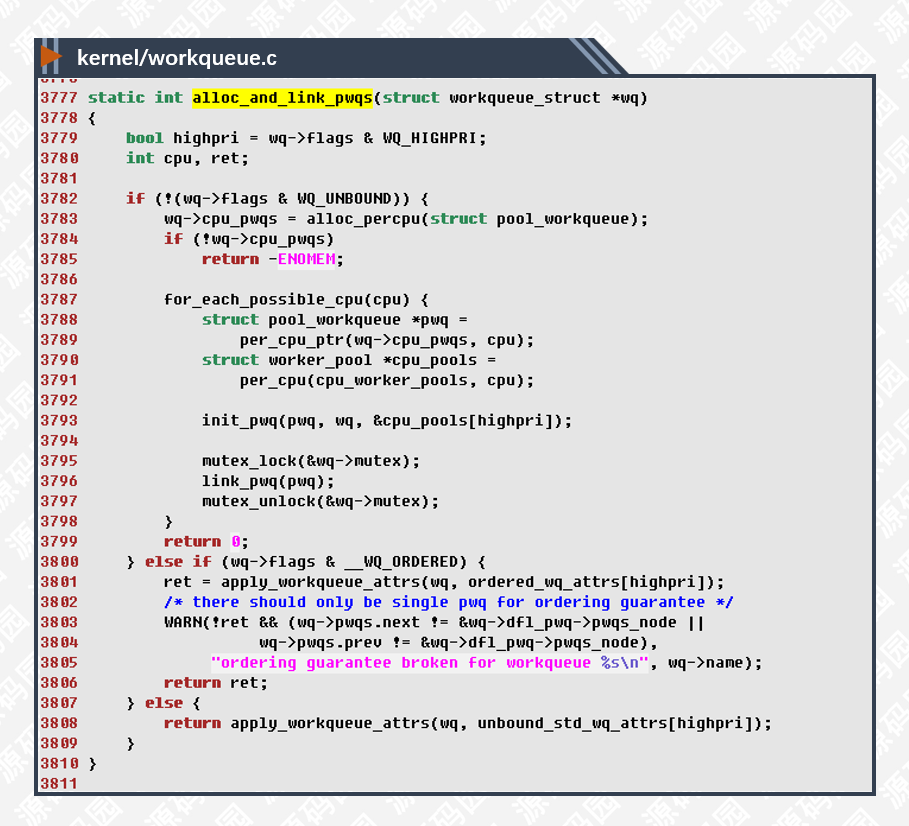
alloc_and_link_pwqs()创建pool_workqueue对象并与线程池连接。
3783行,cpu_pwqs是__percpu类型的变量,这种类型的变量为每一个CPU都分配一个副本,CPU根据自己的索引计算偏移量取出自己的副本来使用,这样可以有效降低锁的使用,提高cache利用率。
3788-3791行,取出每个CPU副本对象指针。
3793-3797行,根据队列的优先级选择相应的线程池并绑定起来。
非绑定线程池又分为有无__WQ_ORDERED标志,用于保障顺序调度,实现逻辑基本相同。
3800-3809行,非绑定线程池是通过队列属性来区分的,也就是说不同属性的队列会有相应的线程池进行调度。
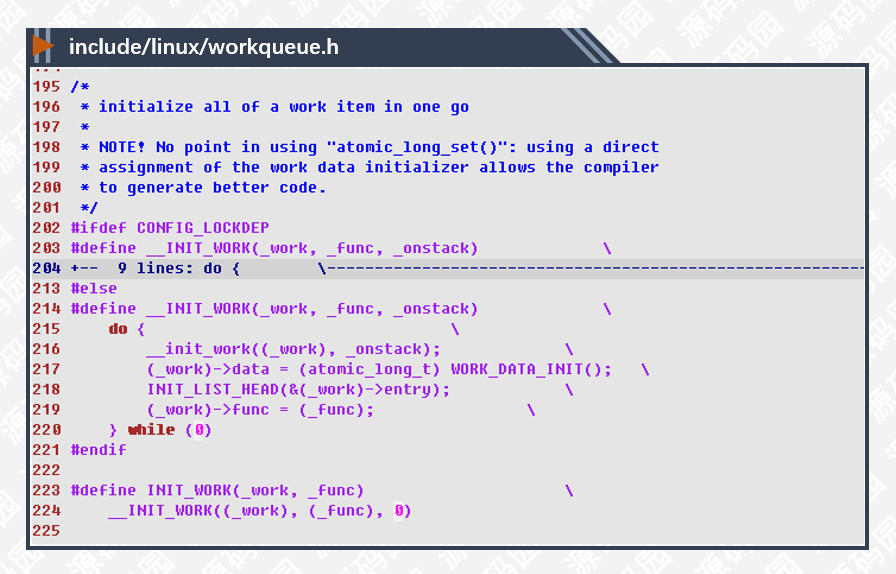
任务(work_struct)对象在使用前要先初始化,代码如下所示:
203-213行,如果定义了CONFIG_LOCKDEP,则定义多一些数据用于线程死锁检测。我们暂时不去分析死锁检测原理, 且CONFIG_LOCKDEP默认也是关闭的。
215-220行,INIT_WORK的具体实现,首先用一个do…while(0)把宏括起来,这是常见的宏定义语法,目的让宏代码更好的嵌入到使用场景中而不至于混淆展开后的代码。
217行,WORK_DATA_INIT宏把work的data成员设成枚举类型WORK_STRUCT_NO_POOL的值,表示当前还没有加入到任何线程池里。
218行,初始化entry链表,工作者线程通过此链表遍历任务列表。
219行,设置任务执行的函数,任务调度一次此函数执行一次,如果需要反复执行应在外层重复的提交任务,不能在函数内做无限循环处理,这样会堵塞线程调度影响其他任务执行。
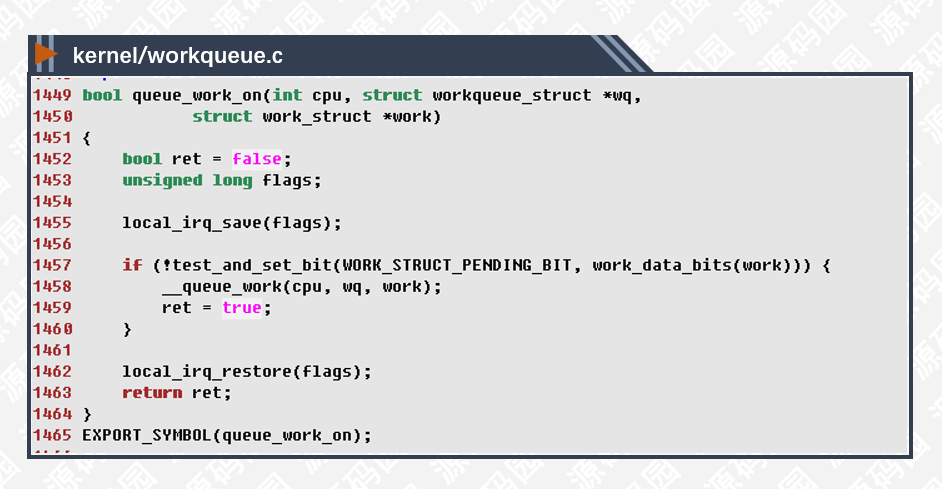
queue_work是一个inline函数,内核中很多接口采用这种用法,在头文件中定义一个inline函数包装一下实际业务的函数,这样过度一下可以有效的降低代码的耦合度。
实际执行的函数是queue_work_on,代码如下:
1455行,1462行,关闭/打开本地中断,防止work的data并发设置。
1457行,设置work->data的WORK_STRUCT_PENDING_BIT,表示任务已经在处理了,完成之前不能重复提交。
__queue_work函数比较长,同样折叠了部分代码,如下:
1365-1368行,这一部分主要获得pool_workqueue对象,跟据work_struct的标志有没有指定WQ_UNBOUND获取相应的pwq指针。
1424-1431行,判断pwq中已经激活的线程数是否小于最大线程数,如果是则加入任务队列调度执行;否则,说明线程都在忙碌的工作中,应该把任务加到延迟工作队列中,之后再调度执行。
工作队列和每一个线程池都会连接在一起,但任务在一个时刻只会插入到一个pwq对象中去,这样在执行调度的时候可以更方便的管理。
以上就是工作队列三个接口的主要实现及对象间的关系,后续我们再另文分析线程池的管理及线程的调度。(armv8, kernel4.4)
第三章
前文我们讲了workqueue的使用例子,及接口代码的实现,现在我们来分析一下线程池的定义及创建,线程池的初始化,及线程创建的相关源码。
Linux内核线程池分为两种,一种与CPU绑定,一种不与CPU绑定。
CPU绑定的线程在固定的CPU上执行,这样对缓存的局部性及CPU亲缘性都有好处,先看一下它的定义
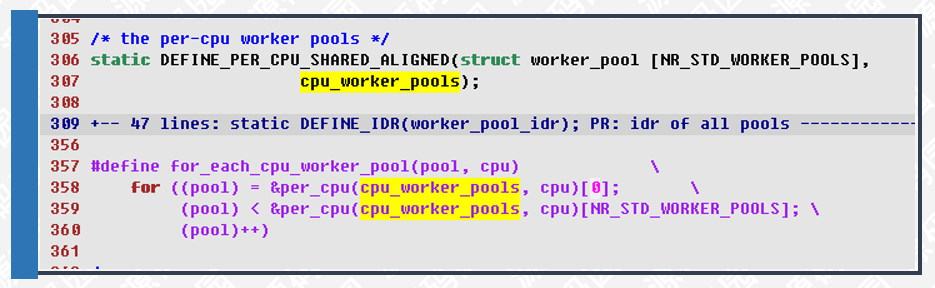
306行,定义一个与CPU关联的per_cpu类型的线程池对象cpu_worker_pools。
357行,根据CPU id遍历cpu_worker_pools对象的指针,参数pool-线程池指针,取出来使用的,cpu-指定CPU的id。
per_cpu类型的变量为每一个CPU都分配一个副本,CPU根据自己的索引计算偏移量取出自己的副本来使用,这样可以有效降低锁的使用,提高cache利用率。
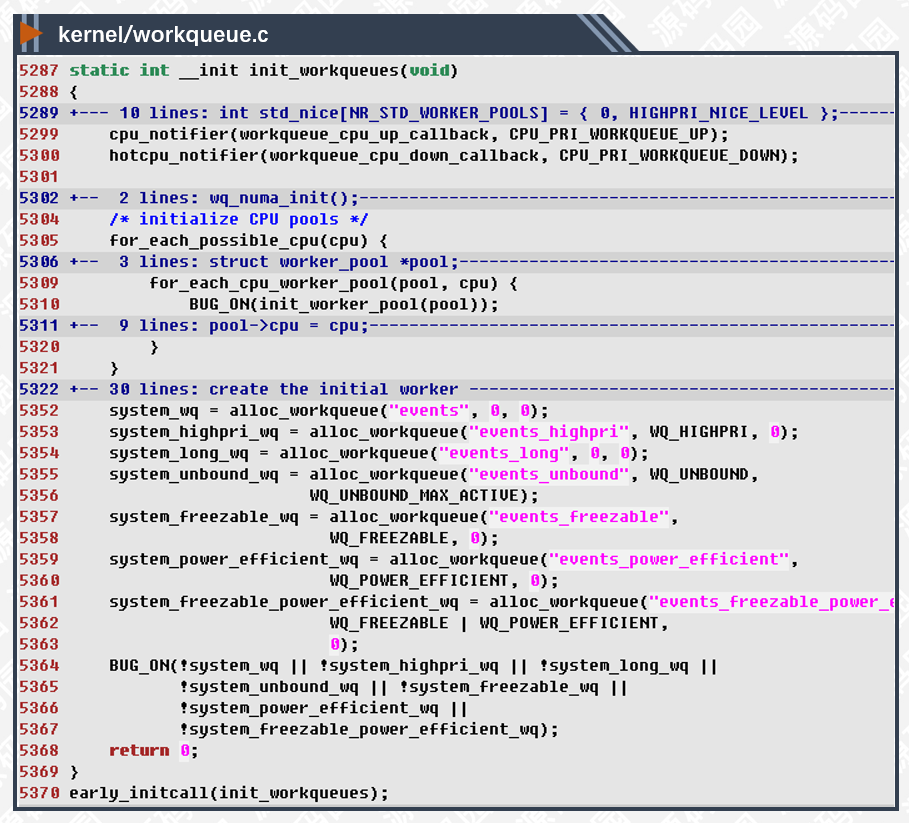
5287,5370行,定义init_workqueues函数在内核初始化early阶段中调用,这时SMP CPU还没有启动,只有CPU0在执行初始化任务。
5299-5300行,设置cpu事件的回调函数,当其他CPU启动后回调来执其他相关的初始化任务。
5352-5361行,默认创建工作队列以方便其他模块使用。
内核线程运行的时候mm的指针为空,说明没有自己的用户空间上下文,但active_mm会绑定到一个用户进程的mm来确使用
。由于默认队列是全局性的,当调度的时候,其active_mm指向的是前一个进程的mm,并不能保证是在当前所需的上下文中运行,不过在工作队列中使用的mm的情况相当少(甚至没有),
基本上都是通过container_of取出work_struct的包含对象来使用。
如果外部模块使用默认的工作队列,每个默认队列的功能大同小异,根据名称即可理解大致的功能,任务的管理及调度和自己创建是一样的,所以可以省去创建队列及指定属性的麻烦事,只需关注任务实际需要执行的功能就够了。
非绑定的线程池通过队列的属性动态创建,也就是说在内核运行的过程中,相同属性使用相同的线程池,不同属性使用不同的线程池,如果相关属性没有对应的线程池则会动态创建一个。
所有非绑定CPU的线程池都保存在unbound_pool_hash哈希表里,使用的时候,以队列属性(nice,cpumask)为key计算出hash值,然后从哈希表里取出对象使用。
3232行,根据队列属性workqueue_attrs计算hash值。
3240-3245行,根据hash值取出worker_pool对象指针,并返回。
3259行,如果哈希表没有找到相应的对象,则动态创建一个。
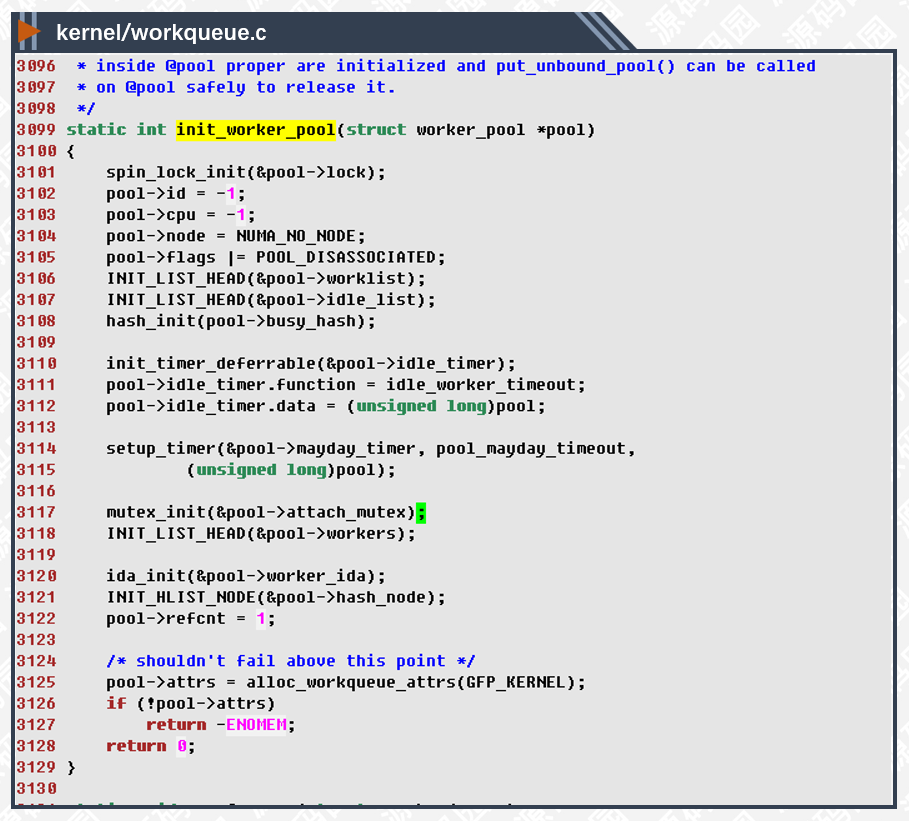
不管是绑定CPU的还是非绑定的线程池,都需要进行初始化。
3104行,初始化NUMA_NO_NODE,在一般的SMP系统中不会用到NUMA,所以不必管它。
3106,3107,3118行,初始化worklist,idle_list,workers链表,用于管理任务,空闲线程,工作线程。
3110-3115行,初始化两个定时器,分别执行idle_worker_timeout和pool_mayday_timeout函数,用于管理空闲线程和,rescue线程。
线程池根据一定的策略来创建线程,并不是越多越好,但至少会创建一个线程,用于管理自己及调度任务。
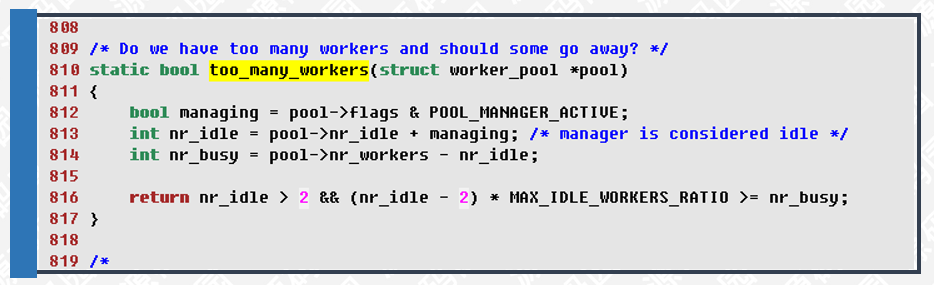
806行,根据已经创建的线程数及是否有空闲线程来判断是否创建新的线程。
816行,根据空闲线程数是否大于busy线程数的1/4来判断是否应该销毁多余的线程。
每个线程池管理一批的工作者线程,根据一定的策略创建新的或销毁多余的线程,
这些线程就是驱动任务完成的推手。
我们来看一下线程是如何创建的
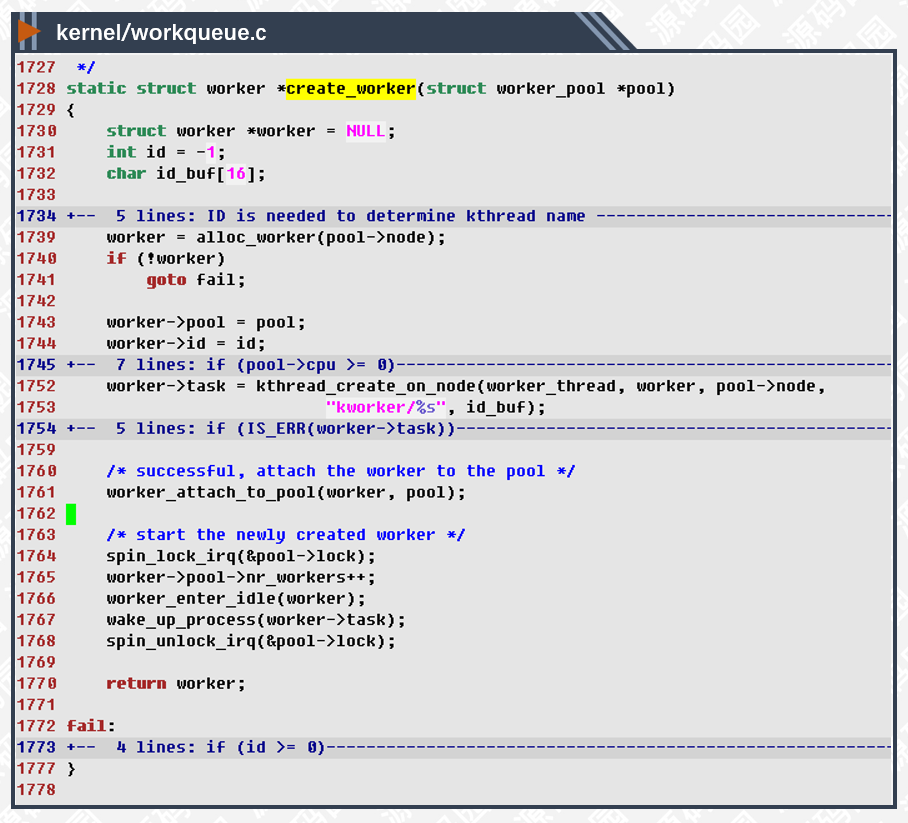
1739行,分配工作者线程所需的内存空间,并初始化相关链表节点。
1752行,创建内核线程,此函数创建的内核线程可以通过ps命令查看到,名称由kworker/%s指定。
1761行,绑定线程与线程池对象,其实就是把线程加入到pool->workers链表里。
1766-1767行,线程设置为空闲线程,并开始调度执行。
以上就是线程池的定义及创建,初始化,及线程创建的相关源码分析,线程的调度逻辑我们下文再述。(armv8, kernel4.4)
·················· END ··················
点击关注公众号,回复【1024】免费领学习资料