作者:Quenton Hall,赛灵思公司工业、视觉、医疗及科学市场的 AI 系统架构师
在本系列的前几篇文章中 ( "人工智能引发能源问题,我们该怎么办 (一) “ 和”在 "人工智能引发能源问题,我们该怎么办 (二)"),我们讨论了 Dennard Scaling 和摩尔定律的细目以及对专用和适应性加速器的需求。然后,我们深入研究了功耗问题,并讨论了网络压缩的高级优势。
在这第三篇文章中,我们将探讨专门构建的“计算有效”神经网络模型的优点和挑战。
神经网络可以被归类为一组大致模仿人脑建模方式的算法,能够通过引入新数据来完成“学习”过程。事实上,开发专用的“计算高效型”神经网络模型能提供大量优势。然而,为了确保模型的有效性,需要考虑几项关键需求。
关键点之一是在实现推断加速器(或就此点而言,广义的硬件加速器)时应采用何种方式访问存储器。在机器学习 (ML) 推断范畴内,我们特别需要考虑如何将权重和中间激活值一起存储。过去几年里已有多种方法投入使用并获得不同程度的成功。相关的架构选择带来的影响十分显著:
时延:对 L1、L2 和 L3 存储器的访问表现出相对较低的时延。如果与下一个图形运算有关的权重和激活值被缓存起来,那么我们就能保持合理水平的效率。然而,如果我们要从外部 DDR 提取数据,就会发生流水线停顿,进而影响时延和效率。
功耗:访问外部存储器的能耗至少比访问内部存储器大一个数量级。
计算饱和:一般而言,应用要么受计算限制,要么受存储器限制。这可能会影响给定推断范式中可实现的 GOP/TOP,而且在某些情况下,这种影响不可小视。如果被部署的具体网络的实际性能是 1 TOP,那么使用能达到 10 TOP 峰值性能的推断引擎价值就不大。
在此基础上更进一步,考虑到访问现代赛灵思器件里的内部 SRAM(熟悉赛灵思 SoC 的人也称其为 BRAM 或 UltraRAM)的能耗大约在几微微焦耳,与访问外部 DRAM 的能耗相比,低大约两个数量级。
我们可以考虑将 TPUv1 作为架构示例。TPUv1 内置有一个 65,536 INT8 MAC 单元,与 28MB 的片上存储器结合,用于存储中间激活值。权重从外部 DDR 提取。TPUv1 的理论峰值性能是 92 TOPS。
图 1:TPUv1 架构
参考资料:Jouppi 等,2017 年,https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
TPU 是其中一种非常普遍的 Tensor 加速器。它使用复杂的编译器来调度图形运算。这种 TPU 对于特定工作负载(引用 CNNO 的速率达到 86 TOPS)体现出极为优异的吞吐效率。然而,CNN 的计算/内存引用比低于 MLP 和 LSTM。因此我们可以看出这些特定的工作负载受存储器限制。在必须将新权重加载到矩阵单元中时,会导致流水线停顿,CNN1 性能也就会随之劣化(14.1 TOPS)。
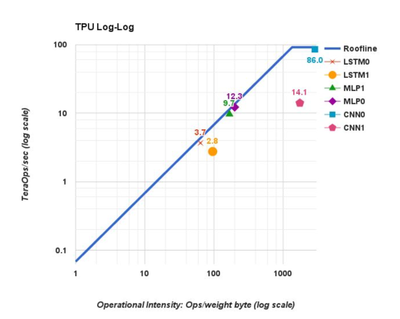
图 2:各种网络拓扑下 TPUv1 的极限性能水平
参考资料:Jouppi 等,2017 年,
https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
神经网络架构对性能有巨大影响,而且对于选择推断解决方案而言,峰值性能指标的价值微乎其微(除非我们能为需要加速的特定工作负载实现高水平的效率)。如今,众多 SoC、ASSP 和 GPU 厂商继续为 LeNet、AlexNet、VGG、GoogLeNet 和 ResNet 等经典图像分类模型推广性能测试基准。然而,图像分类任务的实际用例数量有限,而许多时候这种模型只是用作对象检测与分割等更复杂的任务的后台特征提取器。
更贴近现实的实际可部署模型的示例包括对象检测与分割。尽管众多市售半导体器件标榜可提供数十 TOP 的性能,而这又与不得不花长时间为 YOLOv3 和 SSD 等网络辛苦找寻正式的 IPS 性能基准测试的现状有何关联?开玩笑的说,如果只是要在云存储中简单查找照片,比如找出您的猫的照片,我看这真不是什么问题:

图 3:作者收养的家猫“TumbleWeed”
大量开发者在首次尝试设计带有 AI 功能的产品时往往以不能满足性能要求而告终,迫使他们在设计中途迁移到不同的架构上。这不足为奇。如果这么做意味着需要同时对 SOM 基板的软硬件进行重新构建,难度将不可小觑。选择赛灵思 SoC 的主要原因在于,与竞争对手的解决方案不同的是,赛灵思推断解决方案能在保持处理器和推断加速器架构不变的情况下,直接提供超过一个数量级的性能缩放。
2017 年谷歌的一个研发团队(Howard 等,《MobileNet:面向移动视觉应用的高效卷积神经网络》https://arxiv.org/pdf/1704.04861.pdf )发表了针对移动应用的一类新的模型。MobileNet 的优势在于它能在保持高精度水平的同时,显著降低计算成本。MobileNet 网络采用的重大创新之一是深度可分卷积。在经典卷积中,每个输入通道对每个输出通道都有影响。如果我们有 100 个输入通道和 100 个输出通道,就有 100x100 条虚拟路径。然而对深度卷积而言,我们将卷积层划分为 100 个群组,因此只得到 100 条路径。每个输入通道仅与一个输出通道相连接,这样就能节省大量计算。
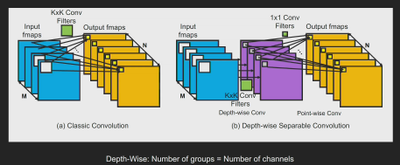
图 4:经典卷积和深度卷积的连接方式
参考资料:Song Yao,Hotchips Hc30,第 8 节:
https://www.hotchips.org/archives/2010s/hc30/
其结果之一就是 MobileNet 的计算/内存引用比得以下降,这意味着存储器带宽和时延对实现高吞吐量来说起着至关重要的作用。
可惜的是,计算效率高的网络未必适合用硬件实现。在理想情况下,时延应随 FLOP 的降低而呈线性比例下降。然而诚如老话所言,天下没有免费的午餐。例如,根据下面的比较,MobileNetv2 的计算工作负载不足 ResNet50 的计算工作负载的十分之一,然而时延并未体现出相同的降幅。
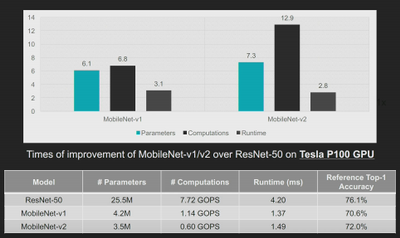
图 5:MobileNet 与 ResNet50 的计算量及时延对比
参考资料:Song Yao,Hotchips Hc30,第 8 节:
https://www.hotchips.org/archives/2010s/hc30/
从上面的分析中可以看出,时延并未随 FLOP 的降低发生成比例的 12 倍下降。
那么我们如何解决这个问题?如果我们比较片外通信/计算比,会发现 MobileNet 的模式与 VGG 有很大不同。就 DWC 层而言,我们可以看到该比例为 0.11。因为 PE 阵列中的众多单元犹如数据中心内的“黑暗”服务器,不从事任何有用的工作,只纯粹消耗功耗并占用晶片面积,导致加速器受存储器限制,效率水平下降。
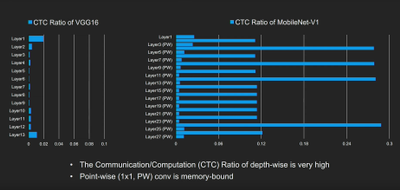
图 6:VGG16 与 MobileNetv1 的片外通信/计算比
参考资料:Song Yao,Hotchips Hc30,第 8 节:
https://www.hotchips.org/archives/2010s/hc30/
赛灵思之所以推出 DPUv1,是为了加速常规卷积(以及其他运算)。常规卷积要求缩减输入通道数量。这种缩减更适合用于硬件推断,因为它提高了计算/权重存储比及计算/激活值存储比。从计算能耗与存储能耗相权衡的角度来看,这是一种非常优秀的做法。基于 ResNet 的网络在高性能应用中得到如此广泛的部署的原因之一在于,与众多传统的主干架构相比,使用 ResNet 能提高计算/内存引用比。
深度卷积无法实现这样的通道数缩减。存储器性能变得更加重要。
为了开展推断,我们一般将 DWC 卷积与 PWC 卷积融合,并将 DWC 激活值存储在片上存储器里,然后立即启动 1x1 PWC。就原始 DPU 而言,没有为 DWC 提供专门的硬件支持,因此效率低于理想水平:
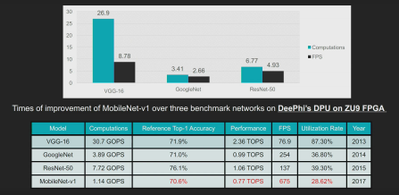
图 7:MobileNet 与 ResNet50 的运算与时延对比 – DPUv1(无原生 DWC 支持)
参考资料:Song Yao,Hotchips Hc30,第 8 节:
https://www.hotchips.org/archives/2010s/hc30/
为了在硬件中提高 DWC 性能,我们对赛灵思 DPU 中的处理单元 (PE) 的功能进行了修改,并将 DWC 运算符与点卷积融合。第一层处理完毕一个输出像素后,激活值立即流水线到 1x1 卷积(通过 DPU 中的片上 BRAM 存储器),而无需写入到 DRAM。我们可以运用这种专用方法显著提高部署在 DPU 上的 MobileNet 的效率。
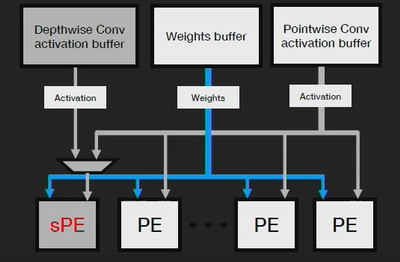
图 8:DPUv2,专用 DWC 处理单元
参考资料:Song Yao,Hotchips Hc30,第 8节:
https://www.hotchips.org/archives/2010s/hc30/
采用这种改进型 DPUv2 架构,我们能够显著提高 MNv1 推断的效率。此外,通过提高片上存储器的容量,我们还能进一步提高它的效率,使之与我们在 ResNet50 上获得的结果相媲美。所有这些都是在 CPU 和硬件架构不变的情况下实现的!
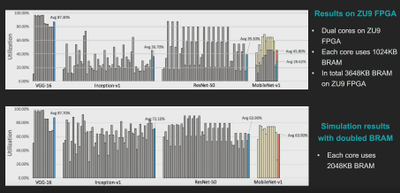
图 9:MobileNet 与 ResNet50 的时延比较,DPUv1 对比 DPUv2(支持 DWC)
参考资料:Song Yao,Hotchips Hc30,第 8 节:
https://www.hotchips.org/archives/2010s/hc30/
广泛采用的做法是互不关联地分别优化推断硬件和神经网络模型。应该注意到的是,网络一般使用 GPU 进行训练,然后在边缘部署在架构显著不同的 SoC 或 GPU 上。为真正优化性能,我们必须适配硬件,才能高效完成模型(不一定对硬件友好)部署。在这种情况下,自适应硬件的主要优势在于赛灵思器件提供在流片后继续联合演进软硬件的特有能力。
为进一步理解这个问题,不妨考虑题为《彩票假说》的一篇独创论文(Frankle 和 Carbin,2019 年https://arxiv.org/pdf/1803.03635.pdf)的寓意。在该论文(摘得 2019 年国际学习表征大会桂冠的两篇论文之一)中,作者“详细阐述了一种假说”,即“含有子网络(中奖彩票)的密集随机初始化前馈网络,如果单独训练,测试精度可媲美经过类似数量(训练)迭代的原始网络”。显然根据这个假说,网络剪枝的前景仍然光明,AutoML 等技术将很快为我们指明网络发现与优化过程中的“中奖彩票”。
同样地,为保证在边缘实现高效、高精度的部署,当今最优秀的解决方案仍保留着传统主干架构的通道剪枝。这些主干架构的部署效率也许不高,但这些主干架构的半自动化通道剪枝可提供极为高效的结果(参见赛灵思 VGG-SSD 示例)。因此,我可以将这个假说解释成:只要您选择的下一个推断架构能让您的设计永不过时,您就可以在今天轻松地找到“中奖彩票”。它能帮助您充分发挥未来网络架构和优化技术的优势,同时向您的客户保证产品经久不衰。

图 9:我个人的“中奖彩票”假说
我可以非常肯定的是,从“彩票假说”衍生出的未来研究有望引领我们开发出新一代剪枝技术,赢得更大程度的效率提升。此外,我感觉只有采用可提供多维度可扩展性的自适应硬件才能收获这样的成果。这并非纯粹是我的直觉。
购买ZCU104,下载Vitis-AI,立刻开启您驶向未来 AI 的旅程吧。



