我秃然想写一点迭代器的内容,先说什么是迭代器:
迭代,顾名思义就是重复做一些事很多次(就现在循环中做的那样)。迭代器是实现了__next__()方法的对象(这个方法在调用时不需要任何参数),我们在说的具体一点就是它是的实现是具有,定义了__iter__()方法和next()方法的对象。它是访问可迭代序列的一种方式,通常其从序列的第一个元素开始访问,直到所有的元素都被访问才结束。
也可以这样判断:可以直接作用于for循环的对象统称为可迭代对象:Iterable。
[注意]:迭代器只能前进不能后退
[迭代器的优点]:
使用迭代器不要求事先准备好整个迭代过程中的所有元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后元素可以不存在或者被销毁。因此迭代器适合遍历一些数量巨大甚至无限的序列。
是通过重复执行的代码处理相似的数据集的过程,并且本次迭代的处理数据要依赖上一次的结果继续往下做,上一次产生的结果为下一次产生结果的初始状态,如果中途有任何停顿,都不能算是迭代。
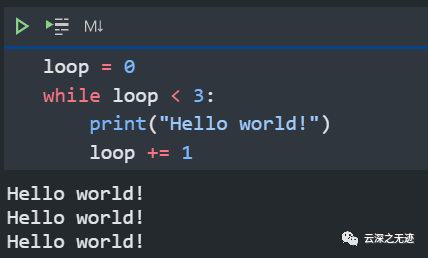
看这个只是单纯的打印而已
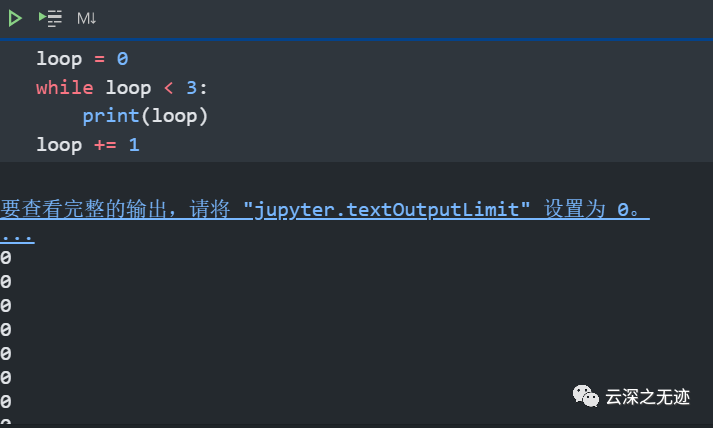
这个才是一个迭代器
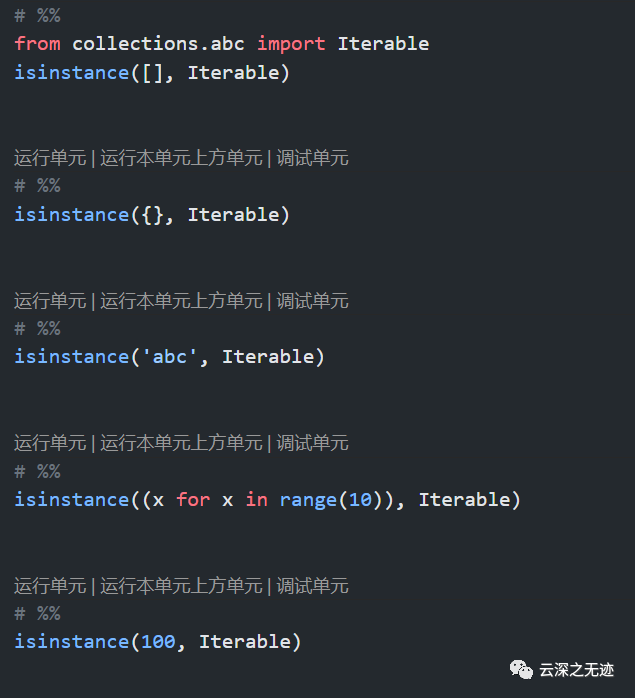
对于是否是可迭代对象,可以用这样的方法来判断
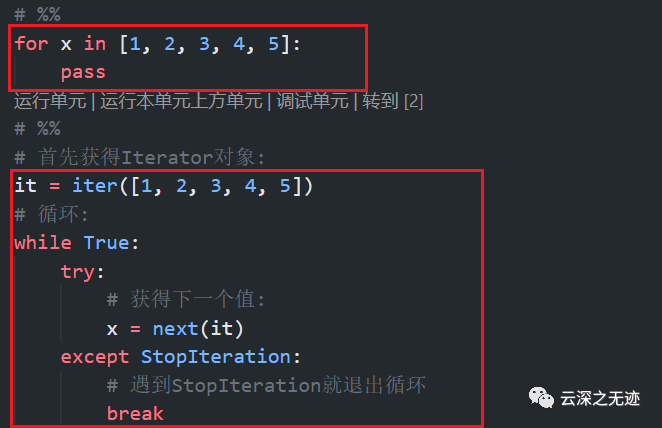
对于Python内众所周知的for循环,就是用next函数来实现的
以上两个例子是相等的,二是迭代器实现,注意最后那个错误是标识

range是一个迭代器吗?
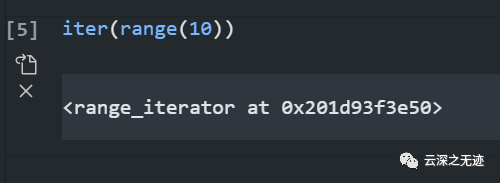
此为转换
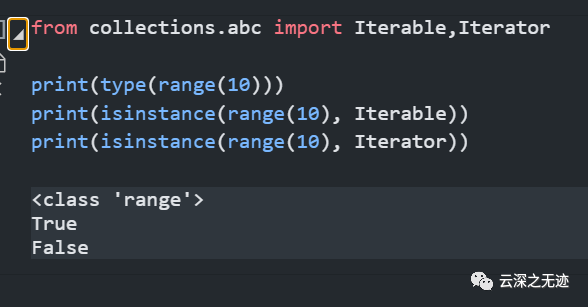
此为用函数判断
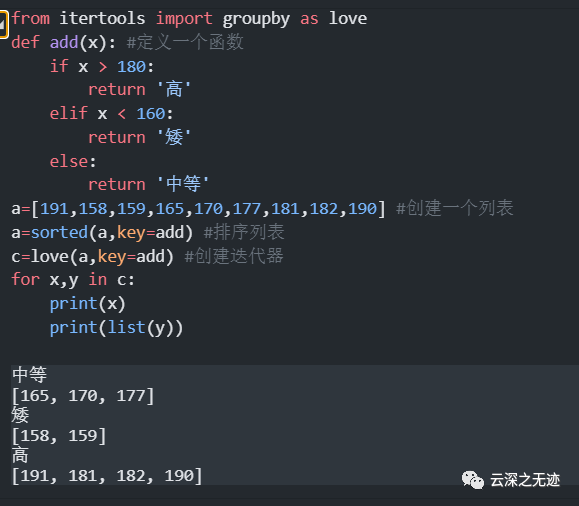
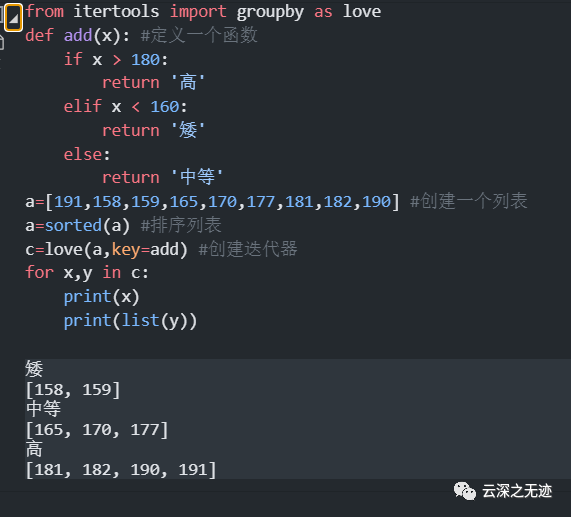
自己找找区别在哪里
https://www.cnblogs.com/LaoYuanPython/p/11144518.htmlPython的Iterator(可迭代)对象表示的是一个数据流,可以把这个数据流看做是一个有序序列(一个接一个),但我们却不能提前知道序列的长度,所以Iterator的计算是惰性的(纯函数的想法,值只在需要时被计算),只有在需要返回下一个数据时它才会计算;
Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误,注意这个错误是对于辨认可迭代对象很重要的一个特征;
所有的Iterable可迭代对象均可以通过内置函数iter()来转变为迭代器Iterator。__iter__( )方法是让对象可以用for … in循环遍历时找到数据对象的位置,next( )方法是让对象可以通过next(实例名)访问下一个元素。除了通过内置函数next调用可以判断是否为迭代器外,还可以通过collection中的Iterator类型判断。如:isinstance(’’, Iterator)可以判断字符串类型是否迭代器。注意:list、dict、str虽然是Iterable,却不是Iterator。
迭代器优点:节约内存(循环过程中,数据不用一次读入,在处理文件对象时特别有用,因为文件也是迭代器对象)、不依赖索引取值、实现惰性计算(需要时再取值计算);
举例:用迭代器的方式访问文件
这样每次读取一行就输出一行,而不是一次性将整个文件读入,节约内存。事实上说起来这个迭代器的一个最大的用处就是这个对于文件的读取了
for line in open(“test.txt”):print(line)6.迭代器使用上存在限制:只能向前一个个地访问数据,已访问数据无法再次访问、遍历访问一次后再访问无数据:
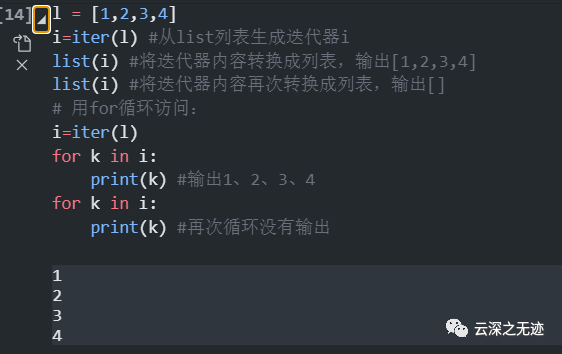
结果
https://blog.csdn.net/LaoYuanPython/article/details/89609187文章后面来源于以上博客,感兴趣可以去围观
最后总结一下:Iterable:可迭代的,可迭代的数据范围要比Iterator要大,但没有next()函数,可迭代对象是将所有已知数据存贮于内存中,注意:数据必需是已知的,有确定的个数和值,因此可迭代对象占用的内存是与其所存贮的数据数据成正比的
Iterator:迭代器,是一个对像,即迭代器对象,有next()函数,迭代器提供的是一个计算出下一个值的方法,不知道数据的个数,只提供一个方法,所占用的内存总是有限。
但是可迭代对象可以通过iter()函数获取一个迭代器~
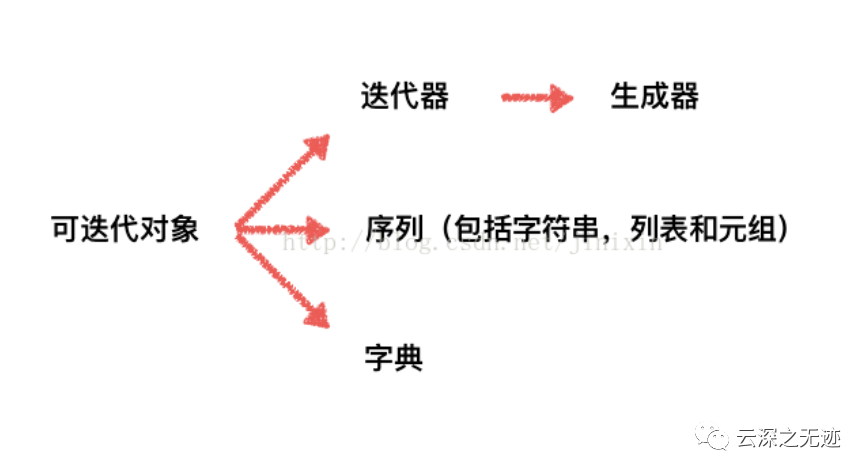
简要的再说一下这些个名词的之间的关系
