

微信公众号:OpenCV学堂
关注获取更多计算机视觉与深度学习知识
免费领学习资料+微信:OpenCVXueTang_Asst
YOLO11框架
YOLO11 是一个多功能的深度学习框架,支持多种计算机视觉任务。该框架可以用于对象检测、实例分割、OBB(定向边界框)、姿态估计等。每项任务都有不同的目标和应用场景,使您能够使用一个框架解决各种计算机视觉挑战。
OpenCV DNN介绍
OpenCV(开源计算机视觉库)的DNN模块是其重要组成部分之一,它允许开发者通过深度神经网络执行推理任务。该模块支持多种预训练模型,包括SqueezeNet、AlexNet、VGG、GoogleNet、ResNet等,这些模型广泛应用于图像识别、目标检测、语义分割等任务。
使用OpenCV的DNN模块,开发者可以轻松地将这些预训练模型加载到他们的应用程序中,进行推理或进一步的微调。此外,DNN模块还提供了多种后处理技术,如NMS(非极大值抑制)和阈值过滤,以便从模型的输出中提取有用的信息。
通过OpenCV的DNN模块,开发者可以利用硬件加速功能来提高推理速度,这包括对CPU、GPU以及专用的深度学习加速器如NVIDIA TensorRT的支持。这种灵活性和高效性使得OpenCV的DNN模块成为许多计算机视觉和机器学习应用中的重要工具。
基于最新OpenCV4.10版本的DNN已经支持YOLO11全系模型推理。代码实现与分别演示如下
YOLO11对象检测
YOLO11对象检测模型 OpenCV DNN部署推理演示如下:
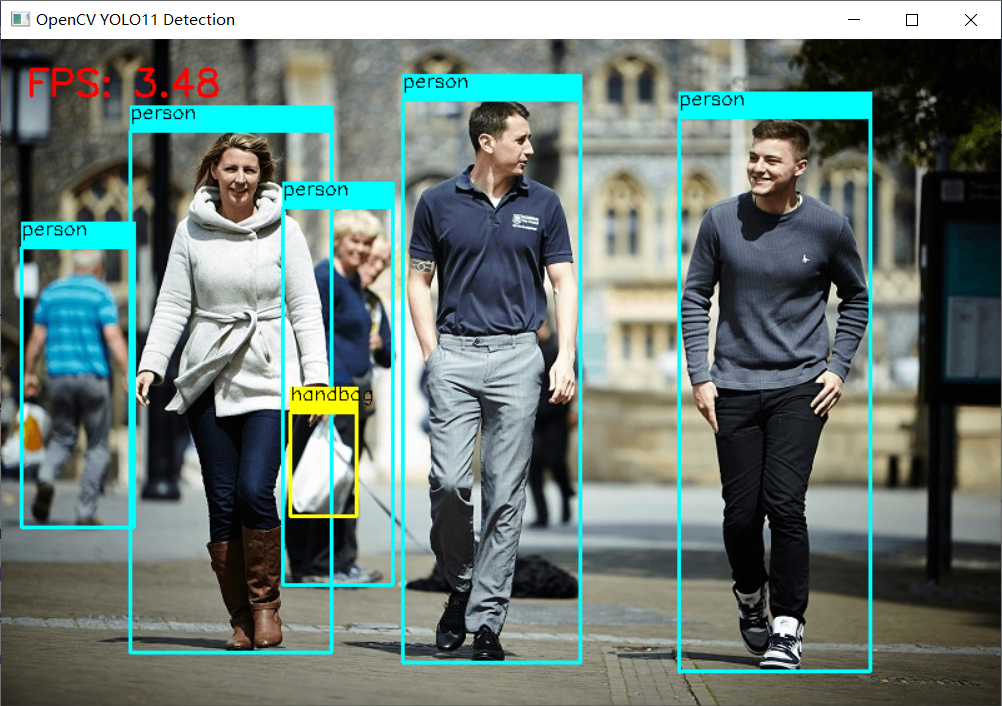
Python实现的代码如下:
model = cv.dnn.readNetFromONNX("D:/python/yolov5-7.0/yolo11n.onnx")frame = cv.imread("D:/city_walk.jpg")bgr = format_yolov5(frame)img_h, img_w, img_c = bgr.shapestart = time.time()image = cv.dnn.blobFromImage(bgr, 1 / 255.0, (640, 640), swapRB=True, crop=False)model.setInput(image)# 进行推理outputs = model.forward()rows = np.squeeze(outputs, 0)class_ids =confidences =boxes =x_factor = img_w / 640y_factor = img_h / 640for r in range(rows.shape[0]):row = rows[r]classes_scores = row[4:]max_indx = np.argmax(classes_scores) #cv.minMaxLoc(classes_scores)class_id = max_indxif (classes_scores[class_id] > .5 ):confidences.append(classes_scores[class_id])class_ids.append(class_id)x, y, w, h = row[0].item(), row[1].item(), row[2].item(), row[3].item()left = int((x - 0.5 * w) * x_factor)top = int((y - 0.5 * h) * y_factor)width = int(w * x_factor)height = int(h * y_factor)box = np.array([left, top, width, height])boxes.append(box)indexes = cv.dnn.NMSBoxes(boxes, confidences, 0.25, 0.45)for index in indexes:box = boxes[index]color = colors[int(class_ids[index]) % len(colors)]cv.rectangle(frame, box, color, 2)cv.rectangle(frame, (box[0], box[1] - 20), (box[0] + box[2], box[1]), color, -1)cv.putText(frame, class_list[class_ids[index]], (box[0], box[1] - 10), cv.FONT_HERSHEY_SIMPLEX, .5, (0, 0, 0))end = time.time()inf_end = end - startfps = 1 / inf_endfps_label = "FPS: %.2f" % fpscv.putText(frame, fps_label, (20, 45), cv.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)cv.imshow("OpenCV YOLO11 Detection", frame)cc = cv.waitKey(0)cv.destroyAllWindows()
YOLO11 实例分割

我已经给它封装成一个类调用代码如下:
weight_file_path = "D:/python/yolov5-7.0/yolo11n-seg.onnx"label_map_file_path = "D:/python/yolov5-7.0/classes.txt"detector = YOLOv8SegDetector(weight_file_path, label_map_file_path)image = cv.imread("D:/city_walk.jpg")detector.infer_image(image)cv.imshow("YOLO11-Segmentation Demo", image)cv.waitKey(0)cv.destroyAllWindows()
YOLO11姿态评估
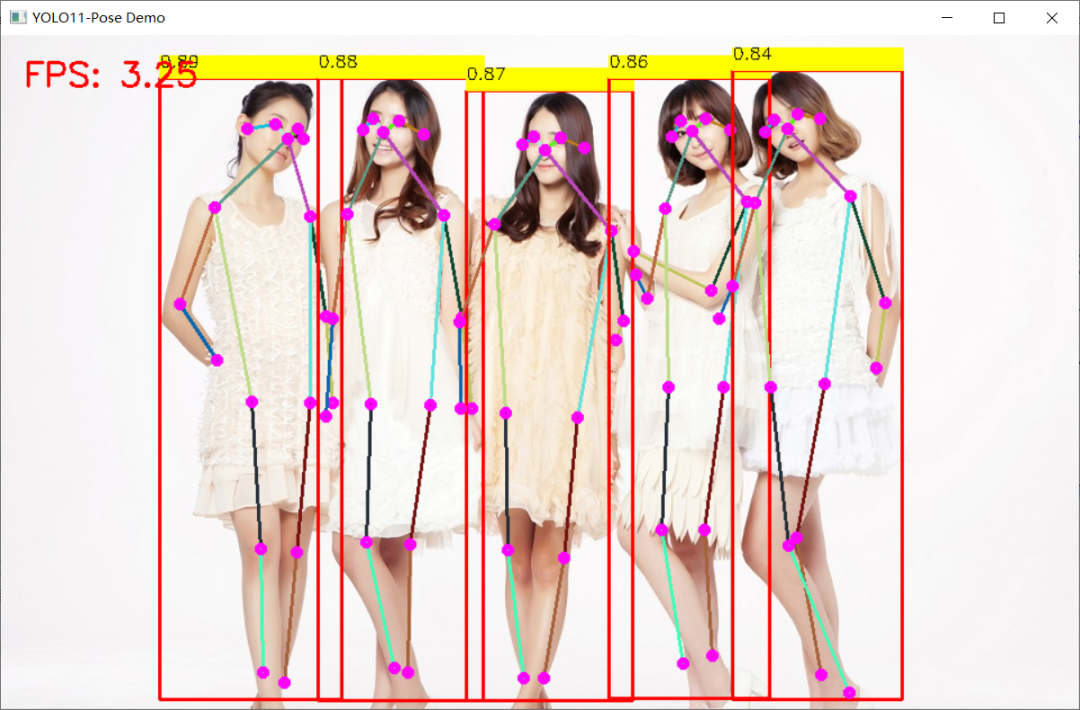
weight_file_path = "D:/python/yolov5-7.0/yolo11n-pose.onnx"label_map_file_path = "D:/python/yolov5-7.0/classes.txt"detector = YOLO11PoseDetector(weight_file_path, label_map_file_path)image = cv.imread("D:/kgroup.jpg")detector.infer_image(image)cv.imshow("YOLO11-Pose Demo", image)cv.waitKey(0)cv.destroyAllWindows()
玩转YOLOv8通杀YOLO系列所有模型!


推荐阅读
OpenCV4.8+YOLOv8对象检测C++推理演示
ZXING+OpenCV打造开源条码检测应用
攻略 | 学习深度学习只需要三个月的好方法
三行代码实现 TensorRT8.6 C++ 深度学习模型部署
实战 | YOLOv8+OpenCV 实现DM码定位检测与解析
对象检测边界框损失 – 从IOU到ProbIOU
初学者必看 | 学习深度学习的五个误区

