



近年来随着机器学习等技术的发展,人工智能在图像识别、语音处理等方面的能力不断增强、应用范围不断扩大,这极大的方便了人们的生活。然而随之带来的安全问题也变得越来越不可忽视。
鉴于此,我们决定采用 Xilinx 的 PYNQ-Z2 开发板,将 FPGA 高度并行化的特点与人工智能安全相结合,设计了一种具有实时人脸伪造能力的视频采集设备。目的在于对视频 数据进行有针对性的伪造,协助安全系统的评估与改进。相较于传统的基于软件实现的人 脸伪造系统,采用FPGA,功耗与成本较低,实时性较高,伪造结果真实,并且隐蔽性更高。对安全系统的性能具有更大的挑战,更有助于安全系统的测试。
本作品的应用前景十分广泛,例如在人脸支付领域,可以对现有的人脸识别系统进行 测试,辅助找出人脸识别系统的漏洞,进而提高人脸识别系统的稳定性与可靠性。如果利用在会议视频中,可以协助会议平台完善对参会者的身份验证的系统,防止出现利用参会者的照片、视频信息冒名顶替的行为。
(1)总体采用 Deepfake 框架,本质是由一套人脸识别、合成、融合构成的技术框架,属 于图像模型在软硬件结合的深度学习中的应用。
(2)软件端的算法设计包括锚框、人脸特征检测、点云匹配、DeepFake Module、泊松融合、前后景融合、边缘膨胀等技术。
(3)硬件端的相关层采用 Xilinx 开发的神经网络加速 IP 核 DPU,同时结合 Vitis AI 对神经网络模型进行压缩优化编译,转换成可供 FPGA 使用的神经网络模型。
(1)延迟:使用 DeepFake 后的延迟约为 270ms。
(2) 帧率:在 640×360 的分辨率下,经过 DeepFake 后的 FPGA 输出的帧率约为 4fps。
(1)采用软硬件结合的方式来实现 Deepfake 框架,相较于传统采用 GPU 加速的方式具有功耗低、体积小、成本低的特点。
(2)对 Deepfake 算法进行了优化,一方面图像信息存储采用 int8 数据类型,激活函数采用计算更快的 ReLU。另一方面对输入输出矩阵的维度进行调整。这些优化对算法速度有很大提升。
(3)完成可配置性的设计,一方面从硬件角度采用多种视频流的接入方式(硬件摄像头/ 网络摄像头),另一方面在算法的图像融合部分设计了两种不同的算法。这些设计可以适应不同处理质量、实时性和应用场景的要求。
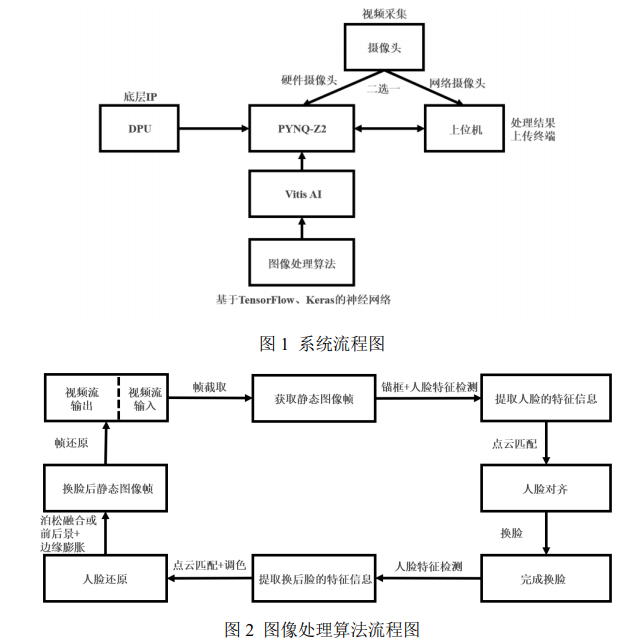
本系统由 Xilinx Zynq-7000 系列的 PYNQ-Z2 开发板作为主控中心,主要包含摄像头 (视频)采集模块、图像处理模块、数据处理终端。总体结构如图 1 所示,图像处理结构如图 2 所示。
系统流程图说明:
由摄像头获取人物实时的图片信息,传送给 PYNQ-Z2 开发板,并在 PYNQ-Z2 中采用 神经网络模型对图像进行处理。最后将处理结果返回到上位机终端,实现真假人脸的转换。
图像处理算法部分说明:
首先进行帧截取,将动态视频流转换成静态帧。通过锚框将全身人像的人脸部分截取出来,再通过人脸特征检测提取出人脸的特征。再提取出特征之后,采用点云匹配算法完成整个人脸的对齐,而后直接使用 Deepfake Module 换掉对齐后的人脸,再通过点云匹配将换后的人脸对齐。然后采用泊松融合或者前后景+边缘膨胀的方式将人脸还原到静态图片帧(具体采用哪种取决于算力与实时性的要求),最终将静态图片帧还原到视频流中。

本系统主要采用 Xilinx Zynq-7000 的 PYNQ-Z2 开发板作为主控中心。从硬件方面上, 该开发板采用 FPGA+ARM 的双处理架构,拥有采用 Cortex-A9 双核处理器的 ARM 芯片, 主频可以达到 650MHz,同时还有快速的 Block RAM 芯片,速度可以达到 630KB。从软件方面上,Xilinx 提供大量的 Python API,同时提供深度学习相关的 IP 核 DPU 以及相应的配套软件 Vitis AI,可以快速部署相应的深度学习模型。

该模块采用罗技的 C270 高清摄像头。摄像头采用 USB 2.0 接口,内置麦克风,同时免驱动。捕获画面最大可达到 1280×720。使用较为简便,并且可以达到本项目的要求,因此十分适合在该项目中使用。
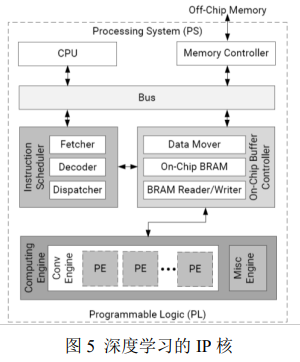
DPU 的详细硬件架构如图 5 所示。启动时,DPU 获取片内存储器中的指令来控制计算引擎的运行。这些指令是由 Vitis AI 编译器生成的,并且在编译时进行了很多优化。片上存储器用于缓冲输入,中间和输出数据,以实现高吞吐量和处理效率。DPU 中的数据均尽可能重复使用来减少内存带宽并且使用基于深度流水线设计的计算引擎。处理元件(PE) 充分利用了 Xilinx 器件中的细粒度构造块,例如多路复用器,加法器和累加器等。
同样的这里给出 DPU 的端口图如图 6 所示,端口的详细类型、数据位宽、I/O 类型以及简单的描述在图 7 中。

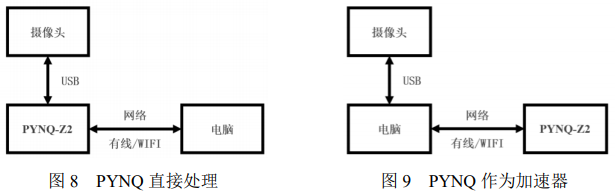
考虑到可能的不同情境,我们为此设计了两种视频流的接入方式。一种是采用 USB 在安装好摄像头驱动的 PYNQ 开发板上直接插入摄像头(PYNQ 直接处理),另一种方式是采用网络摄像头的网络传输接入方式(PYNQ 作为加速器)。网络摄像头采用 Python 中的 socket 库进行开发,可以完成视频流的接收与转发。USB 方式和网络摄像头方式可以分别适应远程与近程两种控制模式。
锚框部分:
锚框部分是我们对整体Deepfake框架的第一次优化,因此这里首先对算法的选择进行说明。最开始时考虑使用OpenCV中内置的机器学习函数库HaarCascade。OpenCV中有Haar 级联分类器,通过分析对比相邻图像区域来判断给定图像或者图像区域与已知对象是否匹 配。可以将多个Haar级联分类器组合起来,每个分类器负责匹配一个特征区域(比如眼 睛),然后进行总体识别。也可以一个分类器进行整体区域识别(比如人脸),其他分类器可识别小的部分(比如眼睛)等。但是Opencv提供的Haar级联分类器和跟踪器并不具有旋转不变性,也就是说无法较好的识别侧脸。而且只有将输入图片的尺寸设计在64×64时才 能将时间控制在40ms以下。此时的识别效果很差,故舍弃该方法。接下来采用opencv中的dnn函数对基于mobilenet-ssd 网络设计的人脸检测模型进行推理。虽然此时的识别率较高并且清晰度也较好,但是耗时大约为300ms,时间极长,也放弃了该方法。因此,最后考虑使用Densebox方法来锚框。
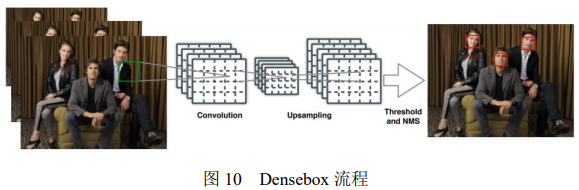
DenseBox 目标检测算法是一个集成的 FCN 框架,并且不需要生成 proposal,在训练过程中也可以达到最优。与现存的基于滑动窗的 FCN 的检测框架相类似,DenseBox 更偏重于小目标及较为模糊目标的检测,比较适合对人脸的检测。整体流程如图 10 所示。
单一的卷积网络同时输出不同的预测框及类别分数。DenseBox 中的所有目标检测模块 都为全卷积网络结构,除了 NMS 处理部分,因此没有必要生成 proposal。人脸锚框时,输 入图片大小为𝑚 × 𝑛 × 3,输出为𝑚/4 × 𝑛/4 × 5。将目标边界框左上角及右下角的点的坐标域定 义为𝑝𝑡 = (𝑥𝑡 , 𝑦𝑡)及𝑝𝑏 = (𝑥𝑏, 𝑦𝑏),则第 i 个位置的像素的输出就可以用一个 5 维向量描述
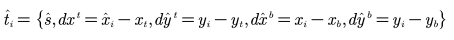
其中s^代表识别到是目标的分数,剩余几个变量代表输出像素位置与真实边框之间的距离。最后对带有边框及类别分数的框进行 NMS 处理。其中 NMS(非极大值抑制)就是抑制不是极大值的元素,可以理解为局部最大搜索。这个局部代表一个两参数可变的邻域,一是邻域的维数,二是邻域的大小。这个操作的目的实际上就是将重叠框最后减少到 只有一个框。
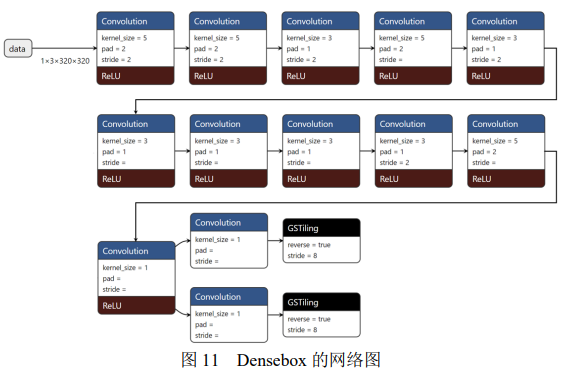
在具体的工程实现中,在权衡实时性、图片质量等多个因素之后,我们采用 320× 320 × 3的输入和 80× 80 × 4与 80× 80 × 2的输出。其中 80× 80 × 4的输出是每个框的左上角和右下角坐标。80× 80 × 2的输出是每个框是人脸的概率和不是人脸的概率。注意这里比上面的算法流程中多出一维,是因为将是人脸和不是人脸的概率均输出出来了, 而算法流程中仅输出是人脸的概率。最后在 DPU 的 IP 核上运行该算法,每检测一张人脸的耗时为 43ms。较好的平衡了计算耗时与计算效果。具体在这个工程中的网络结构如图 11 所示。
人脸特征检测部分:
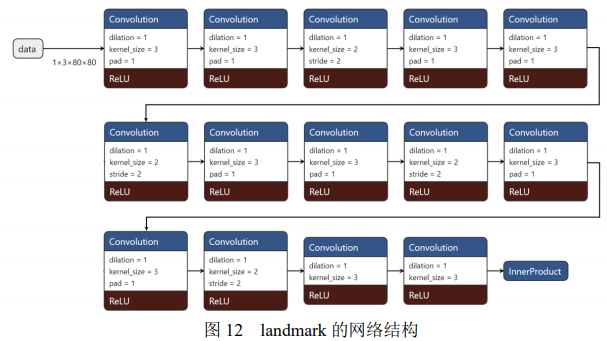
该部分网络结构的思想来自 VanillaCNN,为了更好的匹配 FPGA 的特点和处理要求, 这里将原网络调整成新的 98 个关键点的 landmark 网络。98 landmark 这个网络是专门为 DPU 计算设计的,因为 DPU 不支持 tanh 函数和绝对值单元,这里采用 ReLU 作为激活函 数。ReLU 的计算成本比较低,并且由于激活函数大部分的梯度为 0,因此训练的速度也更快。多次训练该网络,最后能将网络的测试损失从 0.022 减少到 0.019。同时为了提高该神经网络的空间分辨率,这里采用扩张卷积替换了原始算法中的池化层,这一步将网络的测试损耗从 0.019 降低到 0.011。原始算法中仅能进行 5 个特征的标注,这在 Deepfake 框架 后面的换脸中明显是不够用的,因此这里将特征的标注数量从 5 个增长到 98 个。相应的, 网络的输入层从原输入40 × 40 Pixels 变为80 × 80 Pixels,输出层由原来 10 输出的全连接层修改成 196 输出的全连接层,其中 98 个 x 坐标和 98 个 y 坐标。具体的网络结构如图 12 所示。最终采用这个网络标注一张脸花费的时间约为 7ms。
Umeyama 是一种点云匹配算法,是将源点云变换到目标点云的相同坐标系下,包含了 常见的矩阵变换和 SVD 的分解过程。算法的核心在于使变换前后两组点之间的均方距离最小。具体来说就是对两组均为 d 维的点集 A 和 B(各包含 n 个样本点),假定点集 A 的均值为𝜇𝐴,均方差为𝜎𝐴,点集 B 的均值为𝜇𝐵,均方差为𝜎𝐵,点集 A 与点集 B 之间的协方差
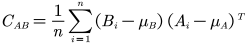
则两组点之间的均方距离用下式表示:
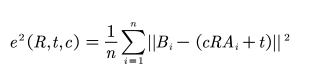
定义矩阵 S 为
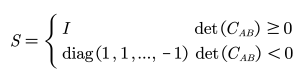
当协方差矩阵的秩恰为d-1时对 S 进行修改
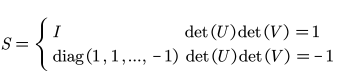
对协方差矩阵进行 SVD 分解得到
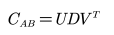
当协方差矩阵的秩不小于d-1的时候参数表示如下
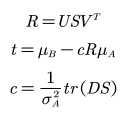
通过该算法就可以将已经标记好的人脸特征进行标准化旋转,方便下面在对应位置直接进行换脸。
网络总体采用 Encoder – Decoder 的形式。网络由一个 Encoder 和两个 Decoder 组成,两个 Decoder 分别对应换脸人照片和换脸对象照片的解码。其中 Encoder – Decoder 的网络结构如图 13 和图 14 所示。
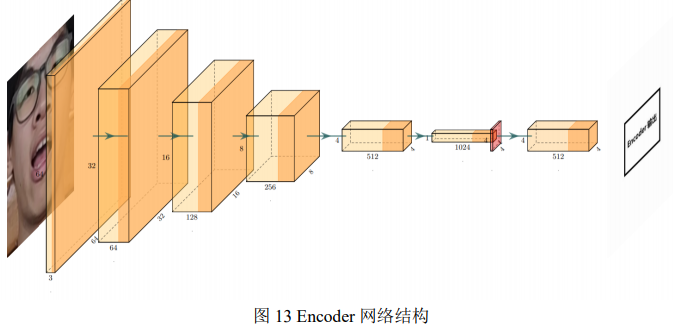
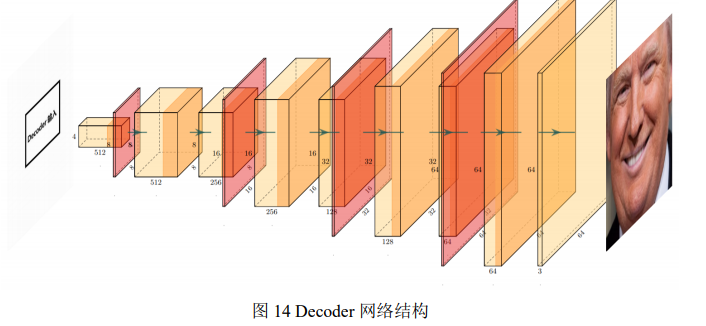
这里涉及到对 Deepfake 框架优化的第二点,相比于在 CPU 和 GPU 上运行的该框架的算法,这里为更好适应 FPGA 的特点对网络结构进行了重建。具体的网络实现如图 15 和 图 16 所示。
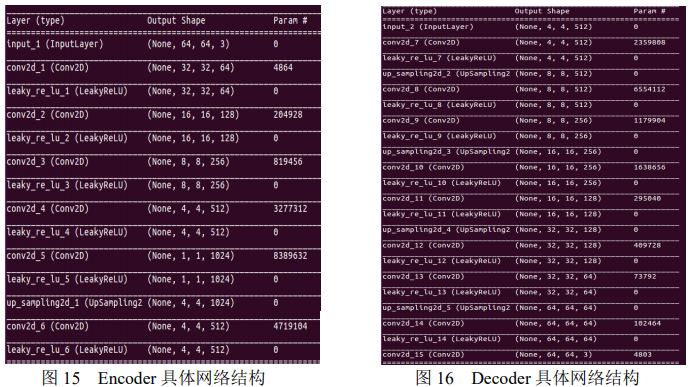
相比于原始算法中的网络结构,新的网络结构将中间 Flatten 的步骤删去。在 Encoder 中采用卷积与激活函数结合的方式,取 leak 值为 0.1,并且保证每次让区域的长和宽减小为原来的二倍,让区域的深度增长到原来的二倍。在 Decoder 中在卷积与激活函数后面加上上采样的过程,每次卷积将深度减为原来的一半,每次上采样将区域的长和宽增长到原来的两倍。
考虑到训练时换脸人与换脸对象的数据集可能在拍摄时处在不同的光线条件下,或者换脸人与换脸对象的肤色本身存在一定的差异。因此这里为了保证能更好的融合换脸人和被换脸对象的面部,提前进行调色。假定换脸人人脸的图像矩阵为 A,换脸对象的人脸图像矩阵为 B,调色后的人脸图像矩阵为 C,则有如下关系:
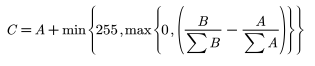
后面的融合部分采用这个调色后的图像。
考虑到该项目的实时性要求与 FPGA 有限的计算资源之间的矛盾,这里提供两种融合内核。根据不同的计算资源与实时性的要求,在项目中可以采用不同的内核。方案 A 是泊松融合内核,方案 B 是前后景+边缘膨胀的内核。总的来说第二种比第一种的融合效果稍差,但是计算的速度更快,因此实时性更好。
方案 A 泊松融合
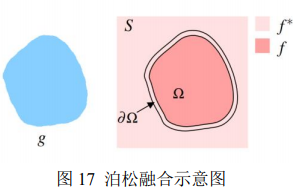
假定有待克隆的图像区域 g,还有一张背景图片 S,泊松融合能将图像 g 自然融合到背景图片 S 中。其中𝑓与𝑓 ∗代表对应区域的像素值,v 是原图像的梯度场, 是原图, 是边界。实际上就是求下面的式子的最小值。
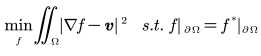
而这个最小值的解实际对应泊松等式的解:
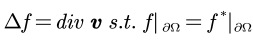
对应的算法流程如下:
Step 1:计算图像 g 的梯度场 v 和背景图片和融合图像的梯度场。
Step 2:求解融合图像的散度场即 Laplace 坐标。
Step 3:用这个 Laplace 坐标和原图求解泊松等式。
方案 B 前后景+边缘膨胀融合前后景的方法如下:
Step1:创建需要替换人脸的区域并转为灰度图片,并通过灰度设置阈值对比,建立 mask 区域。
Step2: 分别对需要替换人脸的区域和用来替换的人脸进行掩膜保护,留下需要的图片。
Step3:将人脸区域和用来替换的人脸进行合并。 边缘膨胀: 为了保证融合后的边缘过渡的更加自然,这里采用边缘膨胀进行边缘的完善。 定义像素点的膨胀范围卷积核如下

指定范围为9 × 9的矩阵,表示每个像素点的膨胀范围,对原图像进行卷积操作就可以完成 边缘膨胀。
由于这个项目采用的是神经网络、Python 与 FPGA 的联合开发,因此这里有必要对文件在 Vitis AI、DNNDK 中的综合以及在 DPU 中的调用流程进行一定的说明。 文件的综合:
对于采用 TensorFlow 编写的神经网络,首先要生成 frozen_float.pb 文件,然后对该文件进行量化生成 deploy_model.pb 文件。对于采用 caffe 编写的神经网络,首先要生成 float. caffemodel 以及 float.prototxt 文件,然后对这些文件进行量化生成 deploy.prototxt 以及 deploy.caffemodel 文件。在生成上面的文件后,使用 dnnc 工具将上面的文件转换成 model.elf 文件,通过链接生成对应的 libdpumodel.so 文件,然后就可以在 PYNQ 中直接调用了。
文件的调用:
在程序开始时调用 dpuOpen 打开 DPU,然后调用 dpuLoadKernal 将先前综合好的网络模型加载到 DPU 中。调用 dpuCreateTask 为该网络模型创建一个任务,同时调用 dpuRunTask 运行这个网络模型。当这个模型计算完成后,调用 dpuDestroyKernel 释放这个 DPU 内核。最后当全部的计算完成后,调用 dpuClose 关闭整个 DPU。
通过 vivado 搭建了神经网络加速的底层 IP 核,vivado 生成的 Block Design,如图 18 所示。图中展示了各 IP 之间的连接关系和数据流的传输过程。
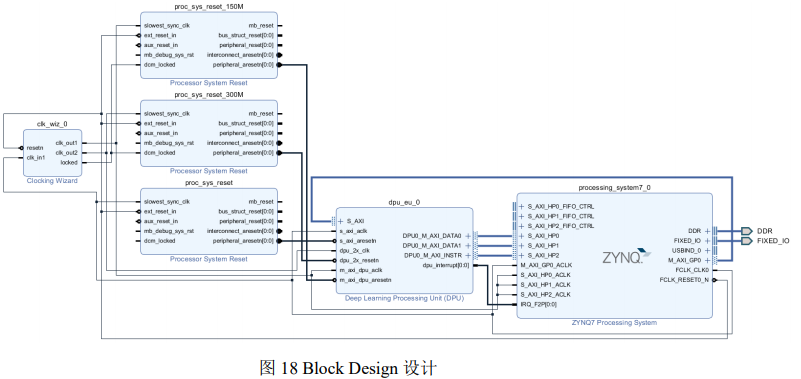
如图 19 所示,底层采用单一的 DPU 核,并选取 B1152 的 DPU 架构。使用较少的 RAM 并允许通道增强、允许带有维度信息的卷积和平均池化操作,选择的激活函数为ReLU 类。因为 PYNQ 的 DPU 不支持 softmax,因此这里不选用 softmax,softmax 的计算在 ARM 的内核中实现。
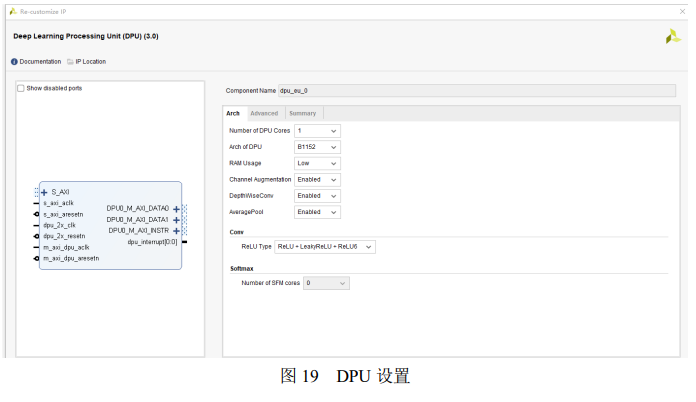
如图 20 所示,系统目前 LUT 占用 68%,BRAM 占用 88%,DSP 占用 96%,FF 占用 59%。
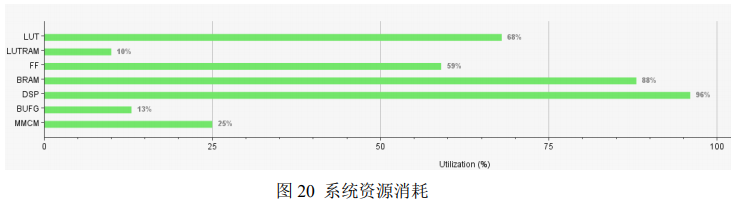
可以看到 DenseBox 网络代码大小为 0.09MB,参数占用大约 0.50MB,乘加操作 485.38 百万次/秒,IO 存储占 0.49MB。
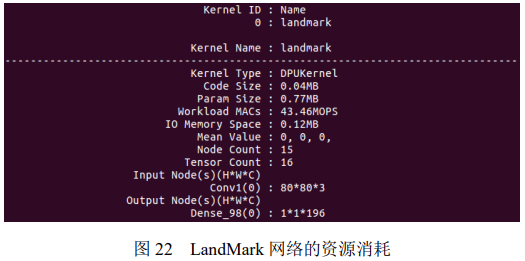
可以看到 LandMark 网络代码大小为 0.04MB,参数占用大约 0.77MB,乘加操作 43.46 百万次/秒,IO 存储占 0.12MB。
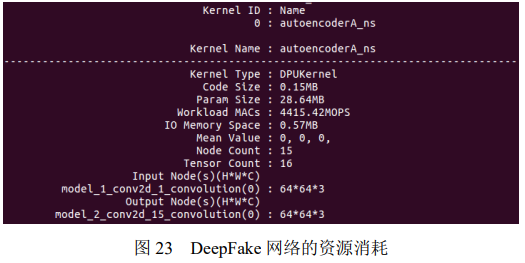
可以看到 DeepFake 网络代码大小为 0.15MB,参数占用大约 28.64MB,乘加操作 4415.42 百万次/秒,IO 存储占 0.57MB。
首先从视频流中截取出静态图,如图 24 所示

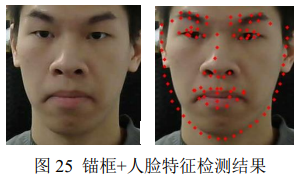
然后经过锚框与人脸特征检测处理,处理结果如图 25 所示
在上面处理的基础上经过点云变换和 DeepFake Model 产生换完脸后的图,同时这里要对换完的脸再次进行特征提取,这几步操作结果分别如图 26 和图 27 所示。

最后采用泊松融合或者前后景+边缘膨胀后接调色+点云匹配的方式将换完的人脸融合到被换脸人的脸上,就可以得到最终的换脸结果如图 28 所示。

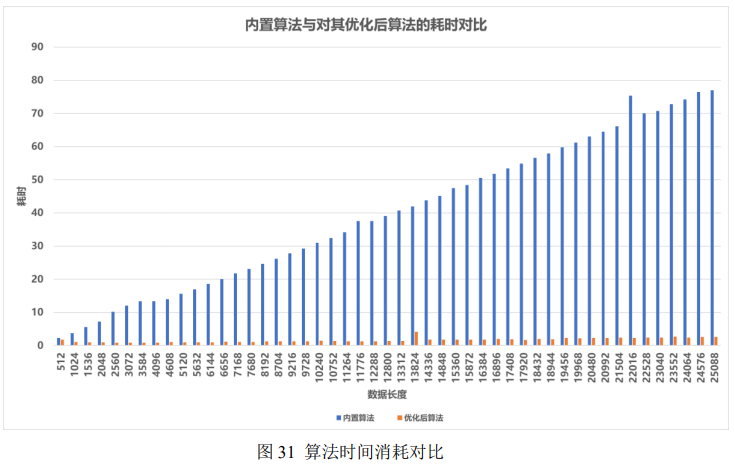
最初开发中,我们使用 DPU 在 Python 的 n2cube API 上进行开发,但是在模型推理结束,读取模型结构到内存的过程中我们发现 n2cube.dpuGetOutputTensorInXXX 这几个 API 函数具有较大的性能瓶颈。在读取 Densebox 的80 × 80 × 4 + 80 × 80 × 2的 int8 的结果时耗时接近 300ms,远不能满足实时性的要求。因此我们着手对这几个读取数据的 API 接口进行优化,具体的优化和每步的耗时如图 29 和图 30 所示。


可以看出,优化后的 API 接口在相同数据长度的条件下处理耗时要少得多。通过测试,优化后的算法比优化前的算法快约 30 倍。
(1)从算力角度上讲: 由于 PYNQ-Z2 的计算能力有限,因此一方面视频处理的实时性和效果存在一定的局限性,另一方面无法同时处理音频与视频。之后考虑可以采用算力更高的 Ultra96 开发板进 行音视频的协同 DeepFake,或者采用 FPGA 阵列提高单位时间内的处理能力,甚至在云端接入 GPU,将 FPGA 作为实体输入,加速深度网络的计算。
(2)从算法角度讲: 这里采用的 DeepFake Model 相对比较简单,仅使用了类似 Unet 的 Encoder-Decoder 模型,图像处理的质量存在较大的改进空间,这里可以考虑在算力有了一定提升的基础上在 计算损失函数时增加 GAN 的处理部分,提高图像处理的质量。
END
往期精选




FPGA技术江湖广发江湖帖
无广告纯净模式,给技术交流一片净土,从初学小白到行业精英业界大佬等,从军工领域到民用企业等,从通信、图像处理到人工智能等各个方向应有尽有,QQ微信双选,FPGA技术江湖打造最纯净最专业的技术交流学习平台。
FPGA技术江湖微信交流群

加群主微信,备注姓名+公司/学校+岗位/专业进群
FPGA技术江湖QQ交流群

备注姓名+公司/学校+岗位/专业进群

