



本文来自“国内外AI芯片平台分析:独立自主的AI系统级计算平台是国产AI芯片构建生态壁垒的关键”,影响AI芯片计算能力的因素除了硬件层面的芯片制程、内存、带宽等,还包括调用各硬件资源的系统级软件计算平台。AI芯片厂商开发的系统计算平台不仅仅有效提升各家AI芯片产品的算力利用率,还为各类AI应用开发提供了丰富的函数库,提供开发者简便易用的开发环境。
本文所有资料都已上传至“智能计算芯知识”星球。如“《60+份AI Agent技术报告合集》”,“《清华大学:DeepSeek报告13部曲合集》”,“浙江大学:DeepSeek技术14篇(合集)”,“《280+份DeepSeek技术报告合集》”,“《100+份AI芯片技术修炼合集》”,“800+份重磅ChatGPT专业报告”,“《12+份Manus技术报告合集》”,加入星球获取严选精华技术报告。
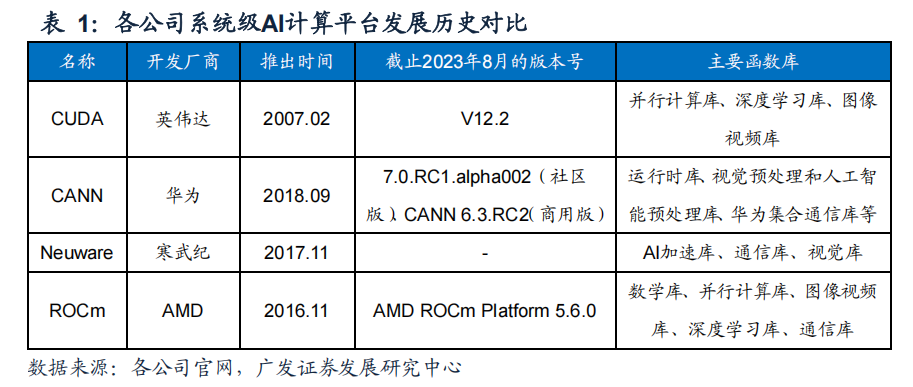
(一)CUDA:释放英伟达 GPU 算力的系统级 AI 计算平台
英伟达开发的CUDA系统计算框架构建了GPU和开发者之间的桥梁。CUDA(Compute Unified Device Architecture)是英伟达公司于2007年推出用于释放GPU并行计算能力和增强通用性的系统级计算平台。CUDA直接对接GPU的物理层,将海量数据分配给多个线程上分别处理,再调用GPU的多核心(计算单元)进行并行计算。为方便开发者更好的调用GPU的计算能力,CUDA也提供了一系列封装好的函数库和API,可在芯片物理层上实现指令级和算子的直接调用。
总体而言,CUDA一方面可高效利用底层AI芯片的算力,另一方面给予开发者便捷的开发环境,满足了开发者高效利用AI底层算力的需求。
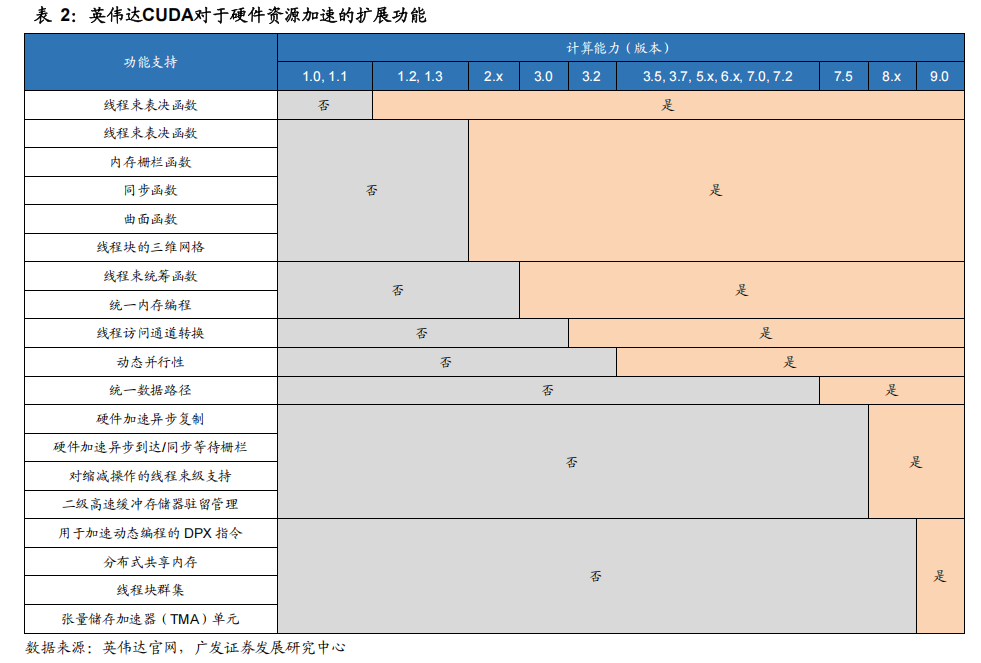
CUDA不仅仅是AI算法开发的工具链,还是调用底层计算资源的系统平台。与一般的软件工具不同,CUDA是更加贴近芯片物理层的系统平台,其提供的封装函数可以实现对于内存、计算单元(算术逻辑单元)、数据传输速率(带宽)等底层算力资源的调用。
因此,CUDA在设计之初的产品定位是给程序员提供对于硬件性能优化和调试的功能。后续,随着CUDA版本的升级迭代,其对于底层硬件资源调用能力持续增强。例如,CUDA 5.0版本中新增的动态并行技术,可以根据数据处理量在内核中动态调用多条线程,减少单一线程上的工作负载,从而保证了不同线程上的负载均衡。
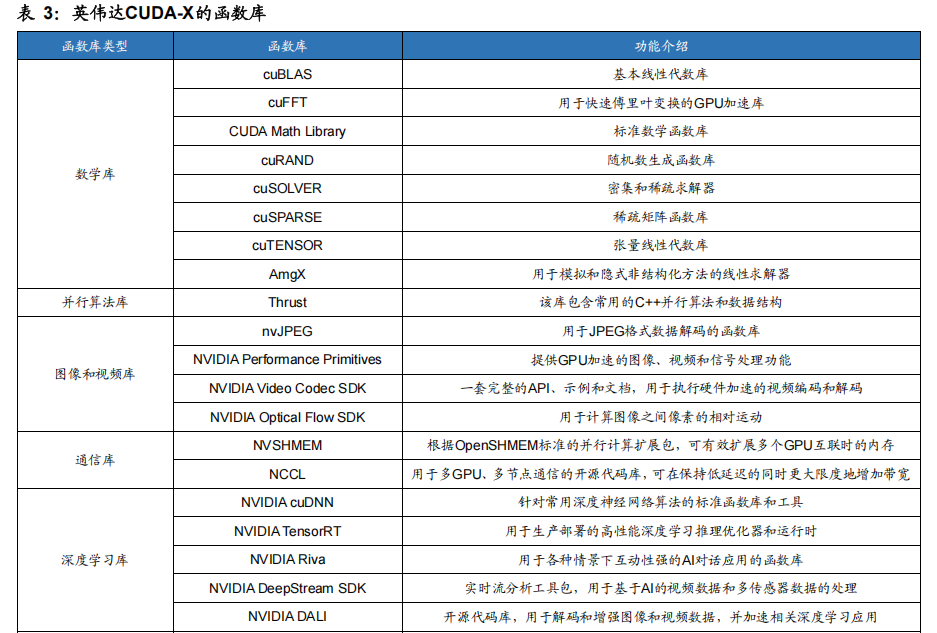
CUDA提供了易用友好的开发环境。CUDA提供了丰富的库函数和工具,方便程序员对于各类AI算法进行开发。经过多年的拓展,CUDA不仅兼容主流的AI训练框架(Tensorflow、Pytorch等),对各类AI算法(DLRM、Resnet-50、BERT等)的覆盖面也更加广阔。通过CUDA,程序员可以高效利用GPU的大规模并行计算能力来加速各种计算密集型任务,包括图像和视频处理、物理模拟、金融分析、生命科学等领域。我们认为,CUDA经过长期积累可提供对于各类AI算法开发的函数库和工具链更加丰富,对各类算法覆盖面更加广泛,在易用性方面具有一定优势。
CUDA与英伟达AI芯片强绑定,随着AI芯片迭代而持续升级。英伟达在每一代芯片架构升级的过程中,添加了一些新的特性来提升对于AI算法的计算效率。针对这些新的特性,CUDA也不断丰富SDK中的函数库从软件层面进一步对AI算法进行加速。
例如,英伟达在2017年推出Volta架构AI芯片产品的时候首次引入了Tensor Core,其将单一维度的数字运算扩展到二维度的矩阵运算,从而提升单次运算能力。在软件层面,CUDA 9.0版本则新增了各类矩阵运算操作符,对于矩阵的加载、相乘、累加都有很好的处理效果。因此,用户可以通过CUDA更好的发挥硬件层面的新特性,从而扩展产品的应用场景。
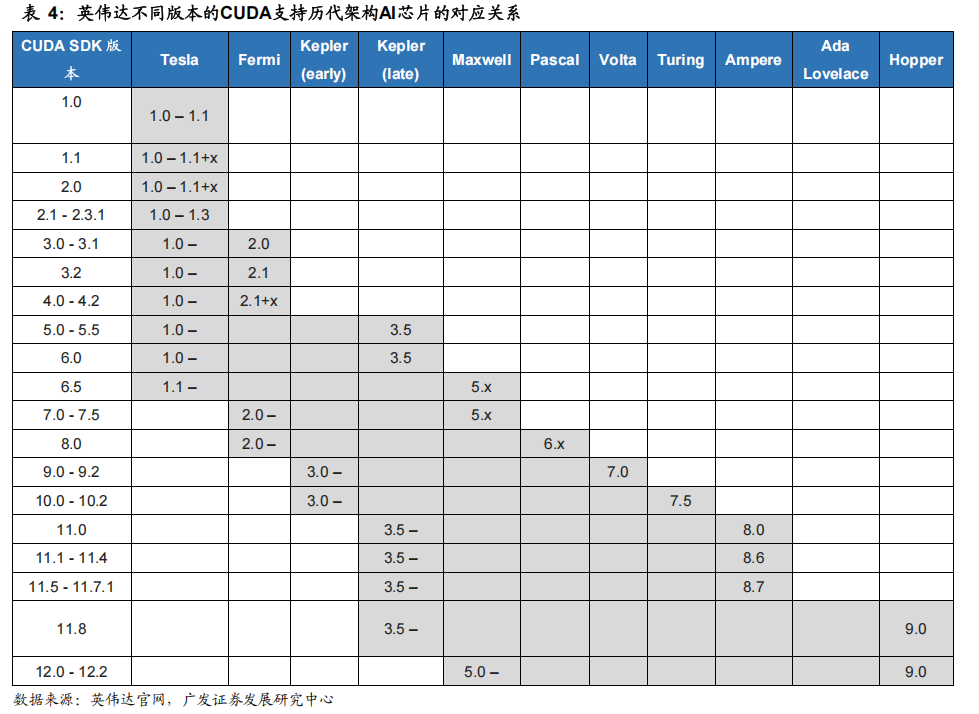
CUDA构建了英伟达长而深的生态护城河。英伟达针对数据中心场景的大数据和AI功能的开发起步早,积累深厚。自2007年,英伟达推出CUDA以来,至今已迭代了12个版本。在多年市场推广下,CUDA已成为AI算法开发主流的系统平台,具有较高的生态壁垒。截止2023年4月,海内外主要科技公司超过百万的开发人员都是基于CUDA开发AI算法。硬件层面的架构升级吸引用户采购新一代AI芯片更新换代,软件层面丰富的工具和易用的开发环境则培养了用户粘性。在长期的积累下,CUDA形成的生态壁垒较好的巩固英伟达的市场份额和龙头地位。
(二)CANN:华为拓展昇腾 AI 芯片生态的关键
CANN(Compute Architecture for Neural Networks)是华为针对AI场景推出的异构计算架构。CANN构建了从上层深度学习框架到底层AI芯片的桥梁,提供多层次的编程接口,全面支持昇思MindSpore、飞桨PaddlePaddle、PyTorch、TensorFlow、Caffe等主流AI框架,提供900多种优选模型覆盖众多典型场景应用,兼容多种底层硬件设备,提供异构计算能力,支持用户快速构建基于昇腾平台的AI应用。
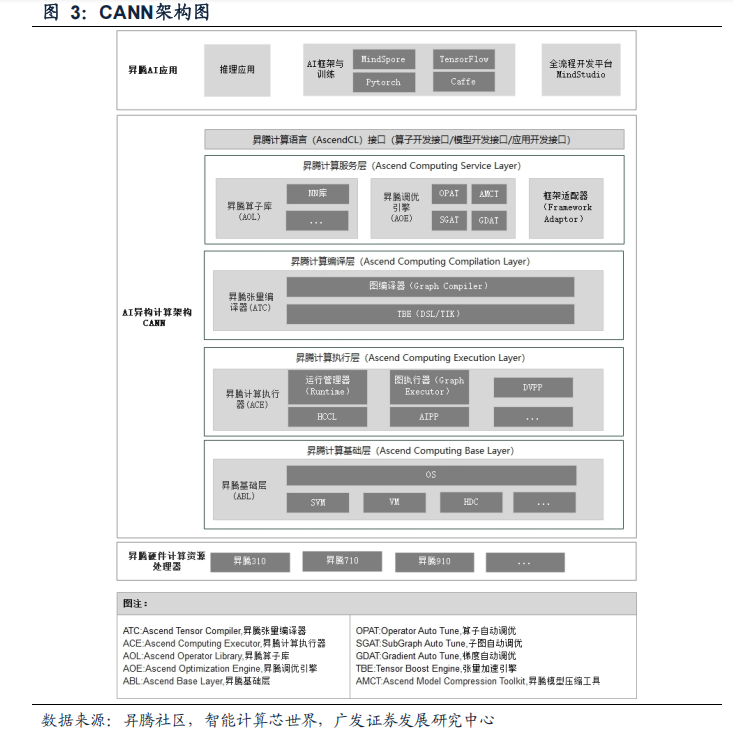
计算架构方面,CANN被抽象为五大层级,分别为计算语言接口、计算服务层、计算编译引擎、计算执行引擎和计算基础层,共同构建高效而简捷的计算平台。CANN的优势是兼容性较强,可在不同的硬件、OS和AI开发框架的异构环境中发挥较好的计算性能,实现端边云多设备的协同,赋能各场景的AI开发。
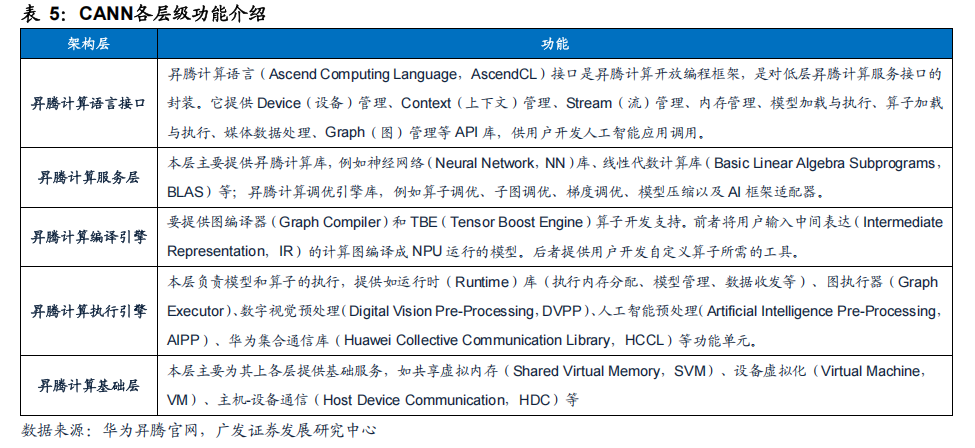
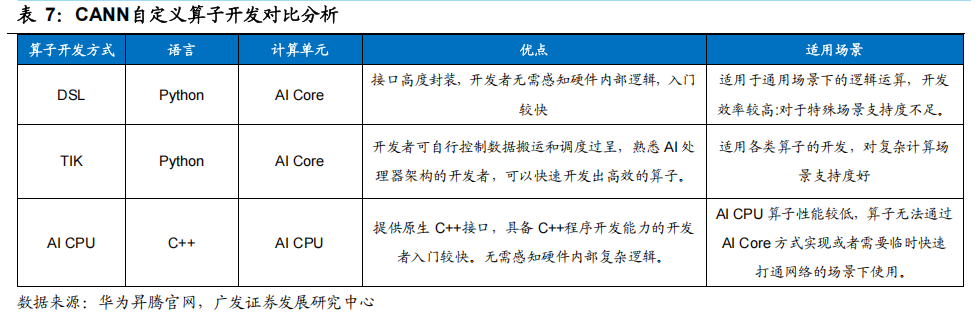
CANN是系统级计算平台,位于物理层和基础软件层之间。CANN根据应用于不同场景中具体的算法需求,为开发者提供了可调用的计算资源以及可操作的功能模块,具体包括超过1200个算子、统一编程接口AscendCL、ModelZoo模型库以及图编译器等。CANN提供了从底层算子、模型开发再到上层应用全流程的开发工具,可覆盖全场景应用,方便开发者快速开发各类算法。作为华为昇腾AI基础软硬件平台的核心,CANN在面向底层硬件资源的调用、面向开发者的工具模块以及面向生态伙伴的接口等方面都有较好设计和提升,其具体特点包括:
1. 简便开发:针对多样化应用场景,统一编程接口AscendCL适配全系列硬件,助力开发者快速构建基于昇腾平台的AI应用和业务。
2. 性能优化:通过自动流水、算子深度融合、智能计算调优、自适应梯度切分等核心技术,软硬件协同优化,提升AI芯片的算力利用率。
3. 开放生态:丰富的高性能算子库和优选ModelZoo模型库,吸引各领域的开发者共建生态。
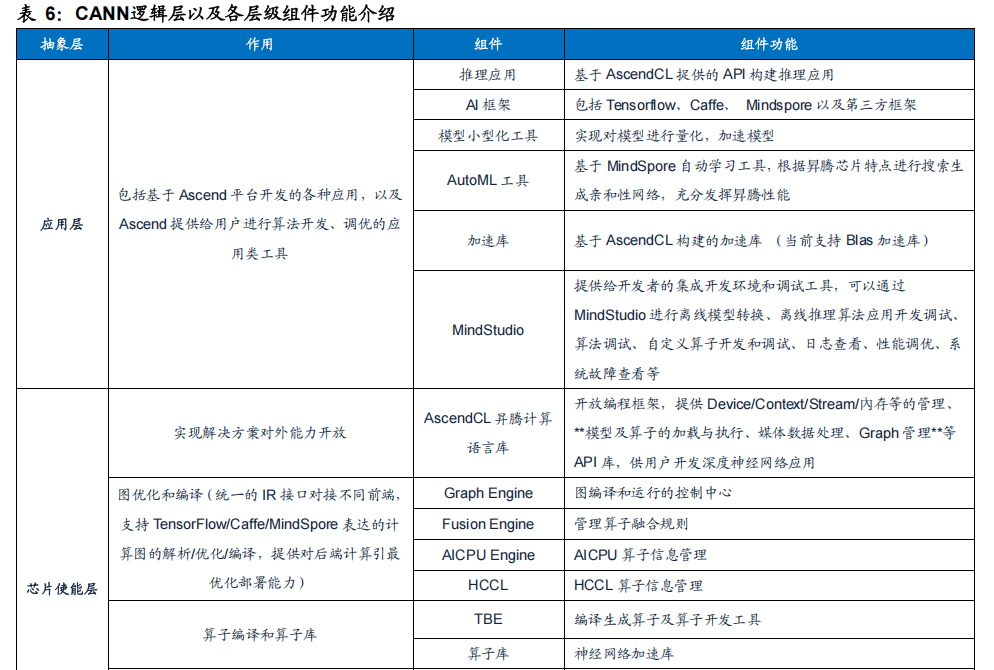
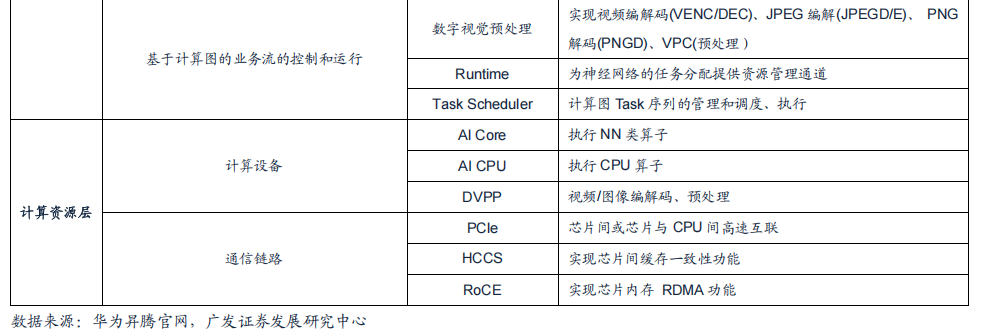
CANN提供算子层面多种开发方式,开发者对AI芯片功能拓展更具灵活性。算子通常是AI芯片的核心部件,其包含各种不同类型的运算操作符,如矩阵乘法、卷积、池化、非线性激活等。CANN提供开发者在算子层面可编程的能力。针对不同算法特点,开发者可以从更加底层修改资源调度方式,从而降低神经网络的计算复杂度和时间开销,提高模型的训练速度和精度。
CANN提供的高性能算子库有效提高训练和推理阶段的计算效率。算子库在AI模型的训练和推理阶段都有重要功能和作用。在AI训练过程中,卷积算子、全连接算子、批量归一化算子等对于神经网络的训练过程需要大量的矩阵乘法和复杂的数学运算有很好性能满足,可以显著提高训练速度和效率。在AI推理过程中,卷积算子、池化算子、激活算子等则可用于加速神经网络的推断,减少响应时间。开发者基于CANN提供的支持包括TensorFlow、Pytorch、Mindspore、Onnx框架在内超过1200个高性能算子,帮助开发者有效提升训练和推理的计算效率。
(三)Neuware:寒武纪实现训练推理一体化的 AI 计算平台
寒武纪Cambricon Neuware是针对其云、边、端的AI芯片打造的软件开发平台。为了加快用户端到端业务落地的速度,减少模型训练研发到模型部署之间的繁琐流程,Neuware整合了训练和推理的全部底层软件栈,包括底层驱动、运行时库(CNRT)、算子库(CNNL)以及工具链等,将Neuware和深度学习框架Tensorflow、Pytorch深度融合,实现训推一体。依托于Cambricon Neuware,开发者可完成从云端到边缘端、从模型训练到推理部署的全部流程,提升AI芯片的算力利用率。
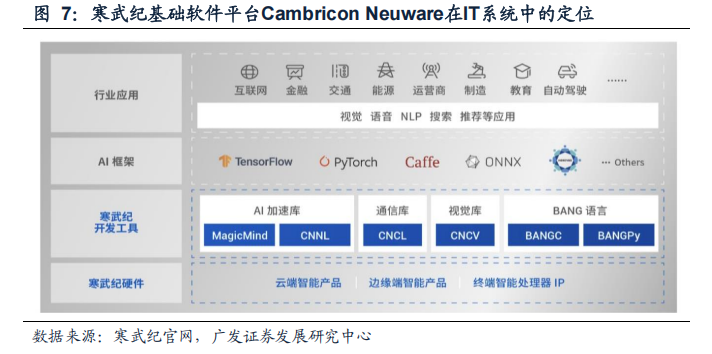
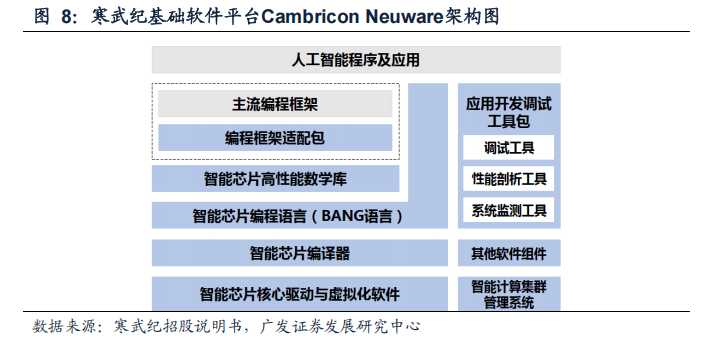
Neuware提供了全面的AI算法开发工具。Neuware包括编程框架适配包、智能芯片高性能数学库、智能芯片编程语言、智能芯片编译器、智能芯片核心驱动、应用开发调试工具包和智能芯片虚拟化软件等关键组件。在开发应用时,用户既可以基于TensorFlow和PyTorch等主流编程框架接口编写代码,也可以通过公司自研的BANG编程语言对算子进行扩展或直接编写代码。智能芯片编译器可以完成BANG 语言到MLU指令的编译,使得AI算法各项指令高效地运行于思元系列AI芯片上。
在开发过程中,用户还可以通过应用开发调试工具包所提供的调试工具、性能剖析工具和系统监测工具等高效地进行应用程序的功能调试和性能调优。此外,Neuware也可以通过智能芯片虚拟化软件为云计算与数据中心场景提供关键支撑。
训练任务方面,Neware的训练软件平台拥有多项强大特性,为用户提供高效且灵活的训练环境。
(1)首先,平台支持主流开源框架原生分布式通信方式以及Horovod开源分布式通信框架,使用户能够轻松实现从单卡到集群的分布式训练任务。多种网络拓扑组织方式的支持,使得用户可以根据需求灵活地选择适合的分布式训练方式,包括数据并行、模型并行和混并行的训练方法。
(2)其次,训练软件平台提供丰富的训练任务支持,涵盖图形图像、语音、推荐以及NLP等多个领域。用户可以在一个统一的平台上完成各类训练任务,极大地简化了训练流程,提高了开发效率。另外,通过底层算子库CNNL和通信库CNCL,训练件平台在实际训练业务中达到了业界领先的硬件计算效率和通信效率。这意味着用户可以获得更快的训练速度和更高的计算性能,从而加速模型的训练过程。
(3)最后,训练软件平台提供了模型快速迁移方法,帮助用户快速完成现有业务模型的迁移。这为用户节省了大量的时间和工作,让他们能够更快地将已有模型应用到新的平台上,提高了平台的易用性和适配性。
推理任务方面,寒武纪自研的MagicMind推理引擎对主流推理场景应用加速效果较好。
2021年底,公司将Neuware架构升级了一个新的模块,MagicMind推理引擎。MagicMind推理引擎支持跨框架的模型解析、自动后端代码生成及优化,可帮助用户在MLU、GPU、CPU训练好的算法模型上,降低用户的研发成本,减少将推理业务部署到寒武纪AI加速卡产品上。此外,MagicMind和深度学习框架Tensorflow、Pytorch深度融合,使得用户可以无缝地完成从模型训练到推理部署的全部流程,进行灵活的训练推理业务混布和潮汐式的业务切换,可快速响应业务变化,降低运营成本。MagicMind的特点包括:
1. 训练到推理的无缝衔接:MagicMind和人工智能框架TensorFlow,PyTorch深度融合,模型训练到推理一键部署。
2. 多种计算精度支持:支持FP32、FP16、INT16、INT8等多种计算精度,支持用户指定不同层级计算精度以及定义量化方法细节。
3. 原生支持动态张量输入:具有完备动态张量表达能力,原生支持任意数据规模的动态张量输入。
4. 丰富的调试调优工具:丰富的调试调优工具以及相应的文档和指引,便利的调试调优体验。
(四)ROCm:为海光 DCU 提供高兼容性的 AI 计算平台
海光DCU全面兼容ROCm GPU计算生态。ROCm(Radeon Open Compute Platform)是AMD基于开源项目的GPU计算生态系统,支持多种编程语言、编译器、库和工具,以加速科学计算、人工智能和机器学习等领域的应用。ROCm还支持多种加速器厂商和架构,提供了开放的可移植性和互操作性。海光的DCU兼容ROCm生态的特性使得其得到国际主流商业计算平台生态系统和社区的支持,可以利用现有的AI平台和共享计算资源,快速实现模型训练和推理的性能提升,短期内有利于其DCU产品的推广。
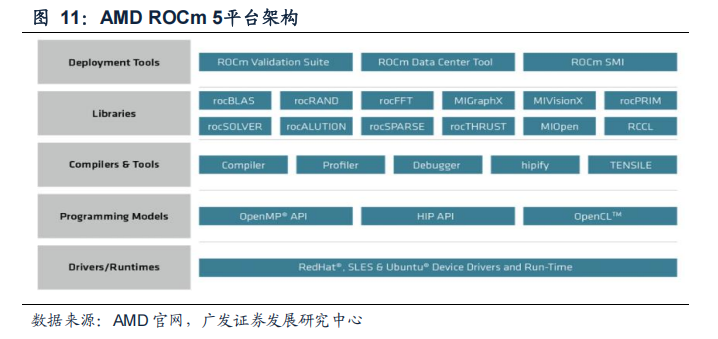
在架构层面,ROCm与CUDA相似度较高。ROCm和CUDA在生态、编程环境等方面具有高度的相似性,两者能很好地兼容兼容,因此ROCm也被称为“类CUDA”。
ROCm为了更好的兼容CUDA,其实现了源码级的对CUDA程序的支持。AMD团队不仅推出了与CUDA API高度类似的“HIP”工具集(Heterogeneous-compute Interface for Portability),使得AI算法工程师在编写ROCm的代码风格上与CUDA尽量贴近,还提供了Rocblas(类似于Cublas)、Hcsparse(类似于Cusparse)等一系列CUDA生态函数库的替代版本。CUDA用户可以以较低代价快速迁移至ROCm平台。
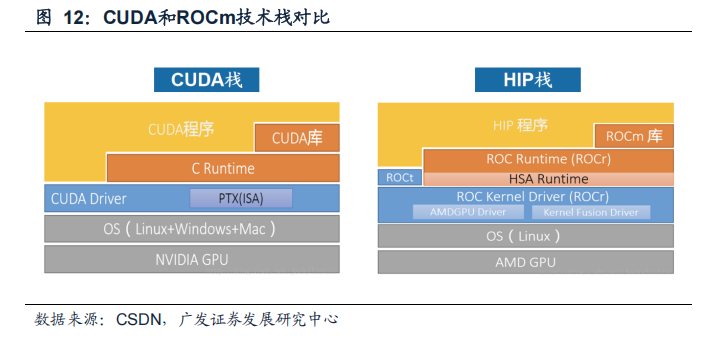
ROCm已实现包括函数接口、编译器和函数库等各方面对CUDA的兼容。API函数接口方面,开发者可以在HIP里得到与CUDA类似的编程语法和大量API指令集,以类似CUDA的风格为AMD GPU编程。函数库方面,ROC库提供了实现常用AI算法的功能,允许开发人员使用类似于CUDA的函数,便捷开发支持ROCm的AI应用。
最后在编译环节,HCC(Heterogeneous Compute Compiler)也是对应CUDA的NVCC的编译器。ROCm实现了对CUDA的全面兼容,使得原本为CUDA编写的代码可以在ROCm平台上重新编译和运行,从而在AMD GPU上实现GPU加速计算。
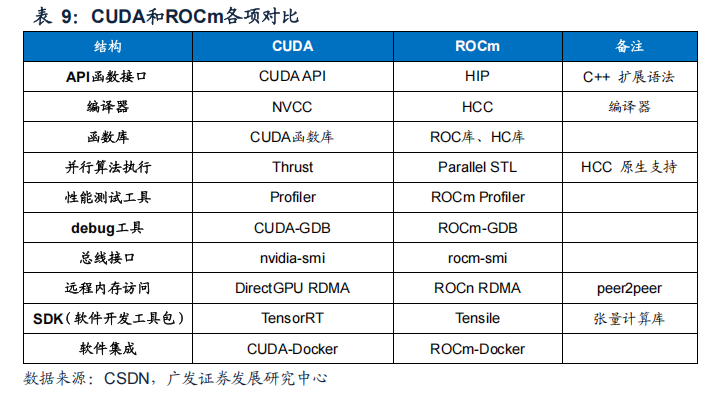
英伟达的CUDA计算平台是主流AI应用开发平台。通过对比各公司开发的AI计算平台,我们发现英伟达的CUDA开发时间最早,积累的开发者数量最多。CUDA推出的的时间是2007年,相较于其他厂商早了十年左右。
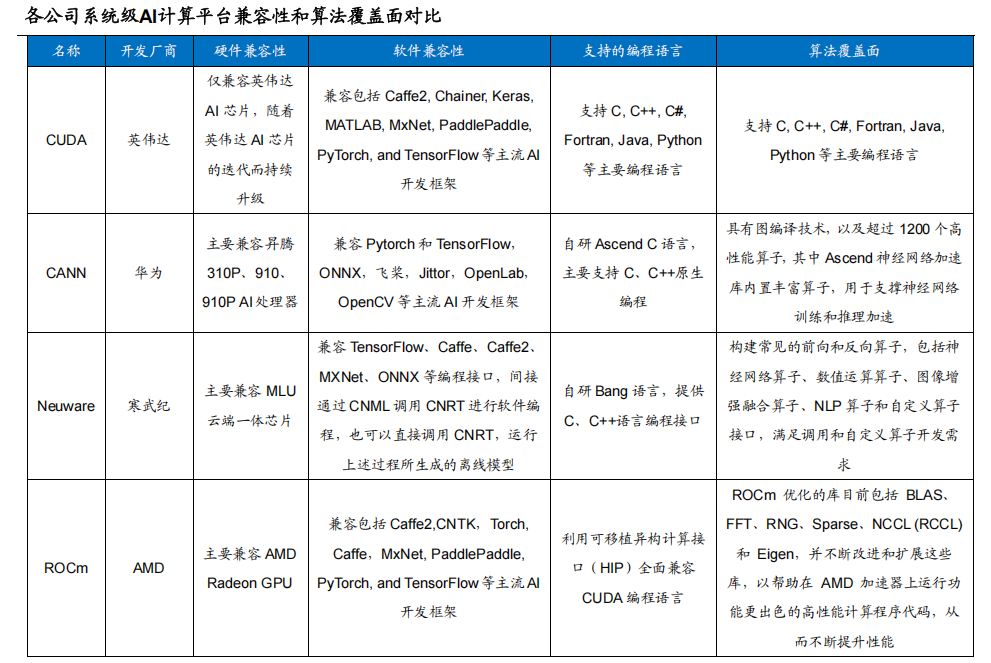
2012年,以Alexnet为代表的识别类AI技术取得突破后带来的AI算法开发的初期阶段,CUDA即取得了先发优势,在AI算法开发群体中快速推广使用。之后,英伟达一方面依靠AI芯片优异的硬件性能快速获客,另一方面持续拓展CUDA的算法覆盖面,不断巩固客户群体。英伟达通过“滚雪球”式的软硬件协同创新,将其AI芯片的市场份额不断扩大,并构建起了深厚的生态壁垒。
下载链接:
8、《3+份技术系列基础知识详解(星球版)》
9、《12+份Manus技术报告合集》
10、《100+份AI芯片修炼合集》
11、《60+份AI Agent技术报告合集》
《270+份DeepSeek技术报告合集》
《42篇半导体行业深度报告&图谱(合集)
亚太芯谷科技研究院:2024年AI大算力芯片技术发展与产业趋势
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


