2025年1月 – 字节发布深度推理模型豆包1.5-pro。
2025年2月 – DeepSeek开源一系列模型优化科技。
2025年2月 – 阿里发布开源深度推理模型QwQ。
2025年2月 – 腾讯发布最新混元模型Turbo S。
2025年2月 – 百度发布文心一言4.5和推理模型X1。
2025年3月 – 腾讯发布基于Mamba架构的开源深度推理模型T1。
此次评测侧重于大模型对通用知识和特定领域特定任务处理能力。本评测中评估的产品是大模型的语言能力水平和知识深度,以及基于这些大模型的相应聊天机器人。
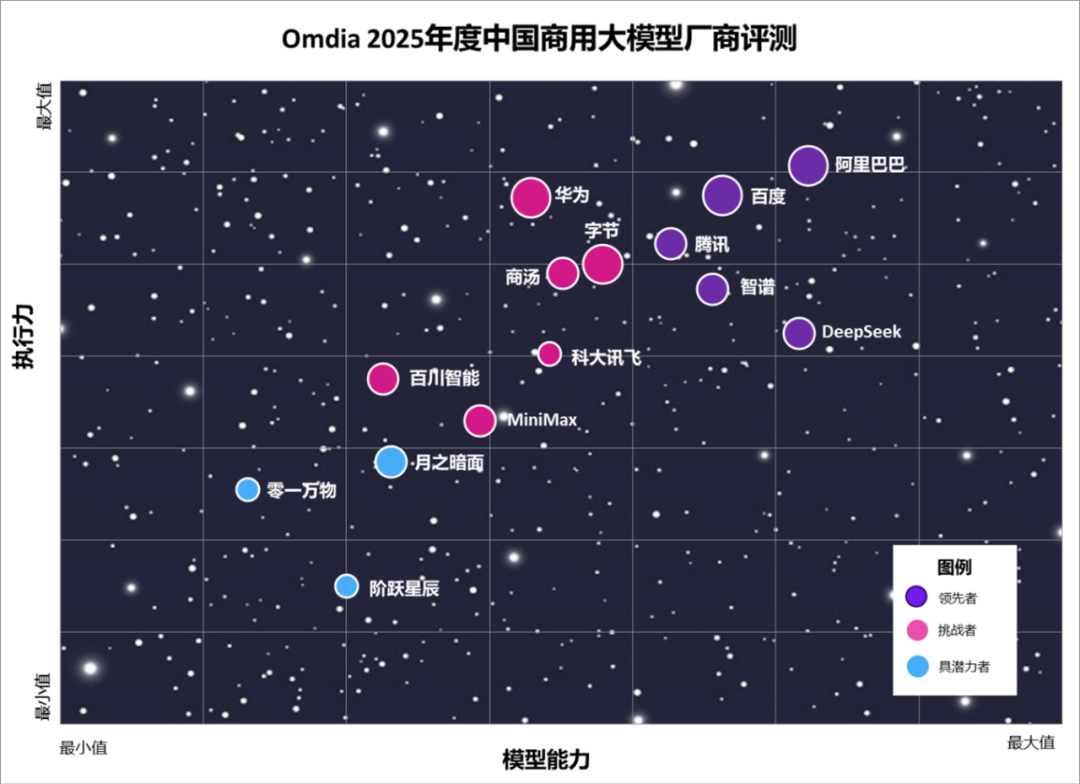
Omdia 主要用两个维度来评测厂商,即模型能力和执行能力。
模型能力的评测主要借助来自主要研究和独立第三方基准的数据,重点关注大大模型以准确、可预测和安全的方式执行通用任务和特定领域任务的能力。大大模型能力、一致性和安全性评估完全基于著名的学术研究论文和第三方评估。这种方法可确保评估过程不受参与者的偏见和影响。
通用任务执行能力:主要用CLiB、FoundaBench、Open LLM Leaderboard 2、OpenCompass 、SuperCLUE、LHMKE、AC-EVAL、C3Bench和Conceptmath的评测结果。同时也会考虑国际基准,如 MMLU、HellaSwag和 LMSYS等。
对齐:主要用AlignBench的评测结果。
安全性: 主要用CHiSafetyBench、CRiskEval、MLLMGuard和S-Eval。
特定领域任务执行能力和可信度: 主要用CFLUE、SuperCLUE-Fin、CMB、CS-Bench和NewsBench的评测结果,同时也会考虑国际基准,如HumanEval和MBPP。
深度推理能力:参考主流人工智能评估基准,包括Arena-Hard、GPQA-Diamond、MMLU-Pro、Frontier Math和LiveBench。
智能体能力:主要用Berkeley Function Calling Leaderboard v3的评测结果。
多模态人工智能:MMMU 和MMMU-Pro 是用于评估这种能力的标准基准。
推理能力:参考主流人工智能评估基准,包括Arena-Hard、GPQA-Diamond、MMLU-Pro、Frontier Math 和LiveBench。
智能体能力:主要用Berkeley Function Calling Leaderboard v3 的评测结果。
多模态人工智能:MMMU 和MMMU-Pro 是用于评估这种能力的标准基准。
执行力的评测主要基于Omdia自身定性的研究来评测以下七点:
创新力:指厂商在支持 GenAI开发和部署的基础设施方面的创新,如芯片、云基础设施、开发平台以及智算中心。
战略和路线图:指厂商针对特定垂直需求、目标受众以及与合作伙伴的需求而开发的创新。
上市战略:指厂商进入市场的渠道以及对大模型的销售和营销支持。
直行业覆盖率:指大模型所能服务的垂直行业。
客户数量:指大模型的客户总数,尤其是大型国内客户和国际客户。
部署服务:指厂商帮助企业实施基于大模型的定制应用程序的能力。
合作伙伴和生态系统:指厂商在本地市场和全球渠道分销合作伙伴及系统集成商的多样性,以及对全球开源生态系统的贡献。
由于可供选择的范围广泛,Omdia 通过对 14 家主要大模型供应商进行基准测试,旨在为中国商业大模型用户提供指导。我们的评估主要基于第三方基准、各种GenAI技术的创新以及通过一级和二级研究获得的商业性能信息。
以下是评估结果(供应商名称按英文字母顺序排列):
领导者: 阿里巴巴、百度、DeepSeek、腾讯、智谱
挑战者: 百川、字节跳动、华为、科大讯飞、MiniMax、商汤
具潜力者: 零一万物、月之暗面、阶跃星辰
领先者必须拥有顶级的通用和特定领域任务性能。阿里、DeepSeek、百度、智谱和腾讯这些大模型在能力、一致性和安全性方面都获得了高分。其中,阿里胜在大模型多模态和深度推理能力以及模型的丰富性。DeepSeek不仅自身模型表现卓越,将开源模型的能力发挥极致,带动开源潮流,还凭着优秀的模型优化技术领先大部分厂商。2025年的智谱在智能体方面有亮眼的突破。百度和腾讯则继续保持在特定领域任务执行的卓越表现。
同时,这些厂商的大模型具有多种商业化战略,并为 GenAI应用开发和部署提供了强有力的支持。大多数市场领导者都涵盖了各种 GenAI能力,从芯片到云基础设施、大模型库、开发人员工具和服务。企业需要满足多种技术要求来充分发挥大模型的能力,包括可靠的数据收集和管理流程、访问人工智能训练和推理芯片、模型托管、部署、维护平台以及模型集成和更新支持。领先的厂商必须具备解决这些问题的能力,而阿里、百度和腾讯利用自身强大的云基础设施为企业有效的解决的这方面的挑战。
市场挑战者主要包括中国的云计算和人工智能巨头,它们拥有强大的基础设施和通用人工智能能力。它们并不缺乏开发强大大模型的资源。相反,它们将重点放在选定的用例或专有解决方案上。华为和商汤主要服务企业。字节跳动和MiniMax聚焦于消费者应用。百川在2025年更是做出转型,主要聚焦在医疗和金融两大行业。
中国大模型市场正式进入DeepSeek时代。DeepSeek的崛起象征着中国厂商已经贴近甚至在某些方面超越了国际厂商的能力。这次评测背后的真正意义是中国厂商再次显示他们在既定赛道上的卓越竞争力。
与此同时,DeepSeek让中国厂商看到了全栈GenAI产品以外的商机。在积极支援DeepSeek大模型的同时,厂商们也在积极开发自身的开源深度推理大模型和多模态模型,接下来会将资源投向小模型、行业模型和智能体等赛道。
此份中国大模型厂商竞争力评测报告仅是代表着Omdia对目前大模型市场的一个主观判断。由于围绕大模型的技术发展迅速,在创新速度丝毫没有减慢的情况下要做出非常完善的比较是很困难的。虽然Omdia尽力做到全面的覆盖及考量,此评测不足之处仍敬请见谅。尽管如此,Omdia会持续跟进,对大模型市场发展提出独特观点。
本文作者

苏廉节
首席分析师 - AI&IoT
文章版权和解释权归微信平台Omdia所有


Omdia隶属于Informa TechTarget, Inc. (纳斯达克代码: TTGT),是一家专注于技术研究与咨询的机构。通过深入科技市场的洞察力和可行性建议,Omdia帮助组织做出明智的增长决策。
omdia.com
Joyce.Liu@Omdia.com