


----追光逐电 光引未来----
本文承接前文关于批量归一化(Batch Normalization, BN)与层归一化(Layer Normalization, LN)的讨论,进一步介绍归一化技术的变体,包括实例归一化(IN)、群归一化(GN)以及一些其他新兴的归一化方式。同时,本篇也将重点关注日前在Transformer模型中出现的“去归一化”(Transformers without Normalization),为读者勾勒出归一化技术的多样化发展路径及未来研究方向。
一、归一化不可或缺?
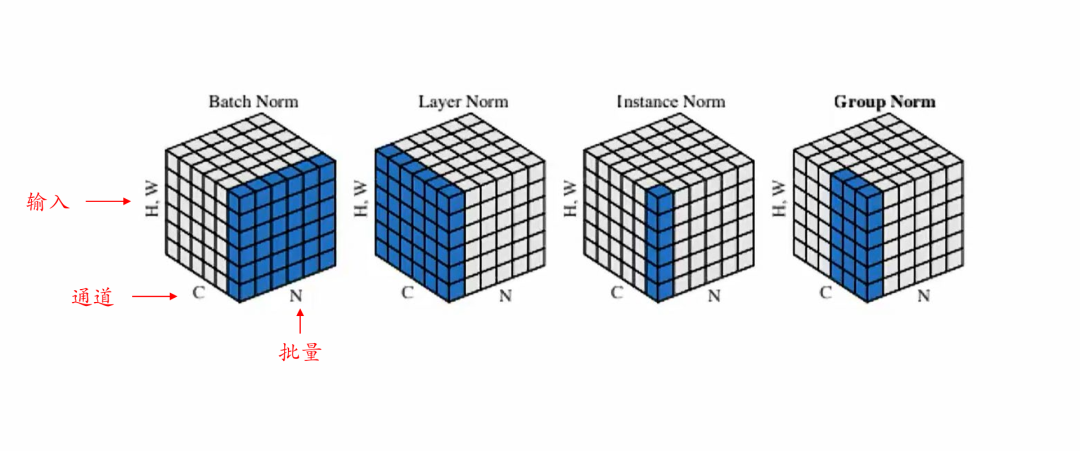
深度神经网络在训练过程中常面临梯度消失/爆炸难题,在前文中,我们已经探讨了批量归一化(BN)和层归一化(LN) 的核心原理、优缺点和适用场景。BN通过在批量维度上计算均值和方差,对图像分类等需要大批量训练的任务非常有效;而LN则在同一个样本的特征维度上执行标准化,因而适用于小批量或者序列建模(如自然语言处理)中。
然而,随着任务的多样化、硬件条件的多元化以及模型结构的不断演变,人们逐渐发现 BN 和LN也无法“一招鲜吃遍天”:在特定场景下,它们要么引入了额外计算与同步开销,要么在极端情况下(如批量大小极小或网络拓扑复杂)不能带来理想的效果。
因此,研究者针对不同场景提出了更多归一化变体,试图在“统计稳定性”、“适用场景广泛性”和“训练效率”之间取得一个平衡。例如,**实例归一化(IN)**在图像风格迁移任务上发挥奇效,**群归一化(GN)**很好地兼顾了BN与IN的优点,适合小批量条件下的卷积网络。除此之外,还有针对权重而非激活分布进行归一化的 Weight Normalization(WN),以及结合了Layer和Channel这两个维度的归一化方法等。
随着Transformer架构的崛起,层归一化(LN)成为标准组件。但最新研究表明,去归一化模型通过改造激活函数等方式,可能突破传统范式,归一化层是否一定是不可或缺的?
二、主流归一化方法
0. BN+IN 详见前文
批量归一化(Batch Normalization)与层归一化(Layer Normalization)深度解析(https://www.guyuehome.com/detail?id=1903812896515739649)
2.1 实例归一化(Instance Normalization, IN)
2.1.1 原理与公式
针对图像风格迁移任务,IN对单样本的每个通道独立归一化。对于输入张量[N, C, H, W][N,C,H,W],计算第nn个样本第cc通道的统计量:
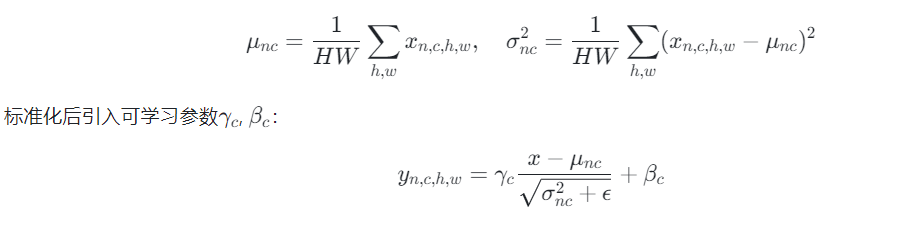
2.1.2 应用场景
IN最初并不是为了常规的图像分类或检测而设计,而是在风格迁移(Style Transfer) 中展现了巨大价值。因为在风格迁移中,我们更关注单张图像自身的“风格特征”,希望对每张图像(特别是每个通道)施加独立的归一化,以保留或改变它独有的统计属性。
同理,在一些图像生成或GAN(生成对抗网络)的任务中,实例归一化也经常被使用。其原因在于,生成网络往往希望在每个样本(图像)的特征图上进行细粒度地控制,而不希望不同样本之间的分布相互“稀释”。
2.1.3 优劣势分析
优势
1.不需要大批量统计;
2.对单张图像独立归一化,适合风格迁移、图像生成等需要保留单样本风格差异的任务;
3.实现简单,每个通道只用关注本图像的局部分布。
局限
1.与BN相反,IN往往无法从跨样本的统计量中获益,可能导致在通用图像分类、检测等任务上性能不及BN或GN;
2.无法在不同样本间“共享”统计信息,可能带来泛化能力的不足。
2.2 群归一化(Group Normalization, GN)
2.2.1 提出动机:填补BN与IN的空白
群归一化(GN) 由Wu和He在2018年ECCV提出,目的是希望在不依赖大批量的前提下,也能拥有比IN更好的表现。BN对批量大小有较强依赖,如果批量过小,估计的均值与方差会非常不稳定;而IN走向了另一个极端——只对单张图片的每个通道做独立归一化,可能过度分散统计。GN则试图在这两者之间找到平衡点,既不需要跨样本统计,又能让多个通道共同分担“信息交流”。
2.2.2 数学形式
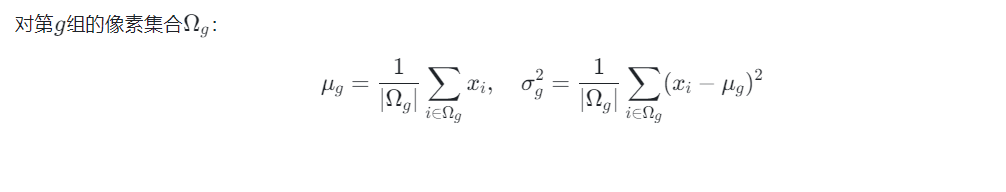

2.2.3 优势对比
优势
1.批量无关性:GN主要在单个样本的通道维度上进行分组,完全摆脱了对大批量的需求。
2.平衡通道内外信息:每个组包含一定数量的通道,组内通道共享均值、方差,有助于网络捕捉更丰富的特征统计。
3.分布式友好:多卡训练时,无需像BN那样进行跨卡同步统计量,通信开销更低。
局限
1.需要手动设置或调参分组数 GG(如8、16、32),不同任务可能需要不同配置。
2.在大批量(如batch size≥32)且是传统CNN任务中,BN往往仍能取得更好的效果。
对于高分辨率图像分割、实例分割或某些3D卷积网络任务,往往只能用很小的batch size(例如1、2甚至更小),这时BN会变得脆弱,GN则能提供更稳定的归一化,从而带来更好的收敛。许多在医疗图像处理领域或对象检测领域的小批量应用中,都成功部署了GN来替代BN。
2.3 其他归一化变种
除BN、LN、IN、GN之外,学术界和工业界还提出了不少其他类型的归一化思路,以下列举几个代表性的:
2.3.1 Layer-Channel Normalization
结合层归一化(Layer Norm)的思路和通道归一化(Channel Norm)的思路,从“层维度”和“通道维度”同时考量,意图在同一层内部既保证特征维度间的均衡,又兼顾通道间的交互。不过实际中应用尚不如GN普及。
2.3.2 Weight Normalization (WN
不再关注激活值,而是直接对权重 \mathbf{w}w 本身进行分解与标准化。例如,将权重写成 \mathbf{w} = g \cdot \frac{\mathbf{v}}{\|\mathbf{v}\|}w=g⋅∥v∥v 并让 gg 和\mathbf{v}v 作为可学习参数。这在某些需要对权重进行精细控制的场景(如生成模型、强化学习等)有不错的效果。
2.3.3 温度加权、可学习偏置的归一化变体
一些论文将 \epsilonϵ 动态化,或在归一化层中加入更多可学习参数(如可学习的“温度”或“门控”因子),试图更灵活地调节模型中每层、每通道的尺度。
整体而言,归一化技术正沿着多种方向不断演化:从激活分布到权重分布,从跨批量统计到单通道、群通道统计,从静态的 \gamma, \betaγ,β 到动态可学习的多参数模型等等。这些新型方法或多或少都是为解决BN、LN等方法在特定场景下的不足,帮助深度网络在更广泛的任务和硬件条件下取得理想效果。
三、去归一化Transformer:
颠覆传统认知
在深度学习应用不断多元化的背景下,另一条正在崛起的研究思路是:如果能完全去掉归一化层,是否也能让网络保持稳定训练?
3.1 归一化在Transformer中的地位与疑问
众所周知,Transformer在自然语言处理、计算机视觉、语音等领域取得了巨大成功。而在Transformer结构中,层归一化(LN) 几乎是标配:多头自注意力和前馈网络之间需要LN做标准化,以避免激活分布在深层堆叠后失控。然而也正因为如此,对LN的依赖也引发了若干问题:
1.额外的计算与通信开销:在大规模或分布式训练时,LN对张量的均值方差操作仍是一种额外负担,尤其在模型参数量数以亿计甚至千亿级时,这部分开销不可忽视。
2.创新空间受限:网络结构在很多情况下都被迫围绕LN做设计,是否可以通过其他途径(例如特殊的激活函数或初始化)来保持模型稳定,从而减小对归一化层的依赖?
3.动态特性不足:传统LN依赖全层特征的均值和方差来做一次性标准化,若输入数据分布在不同阶段差异较大,LN无法自适应地对激活函数的形状做出即时调整。
3.2 Dynamic Tanh (DyT) 方案
传统观点认为,归一化层(如LN)对Transformer的稳定训练至关重要。然而,论文通过实验发现:LN层的输入-输出映射呈现类似tanh的S型曲线。这一现象表明,LN的作用可能通过非线性缩放实现。基于此,作者提出了Dynamic Tanh(DyT),直接模拟这一行为,无需计算统计量。
核心公式:
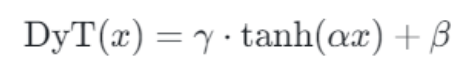

代码实现:
class DyT(nn.Module):def __init__(self, dim, init_alpha=0.5):super().__init__()self.alpha = nn.Parameter(torch.tensor(init_alpha))self.gamma = nn.Parameter(torch.ones(dim))self.beta = nn.Parameter(torch.zeros(dim))def forward(self, x):return self.gamma * torch.tanh(self.alpha * x) + self.beta
从最初的批量归一化(BN)到后来的层归一化(LN),再到实例归一化(IN)、群归一化(GN) 等不断涌现的变体,深度学习的归一化技术已经走过了不短的探索历程,也在实际应用中取得了巨大的成功。可以说,归一化已经成为几乎所有现代深度模型的基础组成,它所带来的收敛加速、分布稳定、容忍高学习率等优势,在诸如图像分类、目标检测、语音识别、自然语言处理、风格迁移等诸多任务中都有体现。
然而,正如最新研究发现的:归一化层并不一定是不可替代的。随着网络深度和任务复杂度的不断提升,研究者开始思考:能否通过改造激活函数(如Dynamic Tanh)、重新设计残差结构或初始化策略,甚至将归一化的功能嵌入到更加底层的计算中,最终减少甚至彻底移除对显式均值方差归一化层的需求?“这类 无归一化”模型的兴起,恰恰说明了深度学习的创新仍在持续进行,所谓“终极范式”并未到来。
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


