

微信公众号:OpenCV学堂
关注获取更多计算机视觉与深度学习知识
AA-Clip介绍
异常检测(AD)识别出缺陷和病变检测中的异常值。虽然CLIP在零样本异常检测任务中显示出有希望的结果,但由于其内在的异常不感知特性,它在区分正常特征和异常特征方面存在局限性。
为了解决这个问题,我们提出了异常感知的CLIP(AA-CLIP),它增强了CLIP在文本和视觉空间中的异常辨别能力,同时保留了其泛化能力。
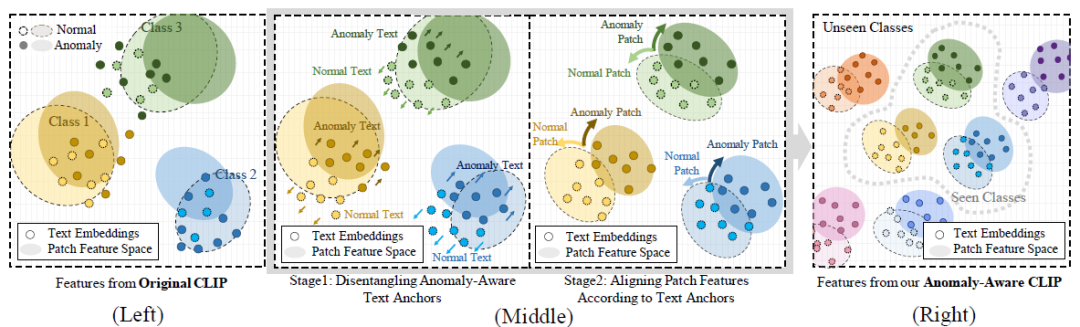
AA-CLIP通过一个简单而有效两阶段方法实现:
首先,创建异常感知文本锚点,以明确区分正常语义和异常语义;然后,将patch级视觉特征与这些锚点对齐,以精确定位异常。
这种两阶段策略在残差适配器(residual adapters)的帮助下逐步适应CLIP,以有效进行AD并保持CLIP的类别知识。大量实验验证了AA-CLIP是一种高效且资源节约的解决方案,在工业和医疗应用中实现了零样本异常检测任务的最先进结果。
在我们探索CLIP的纹理特征进行AD时,我们观察到虽然CLIP的文本编码器有效地捕捉了物体级信息,但它在区分正常语义和异常语义方面存在困难。

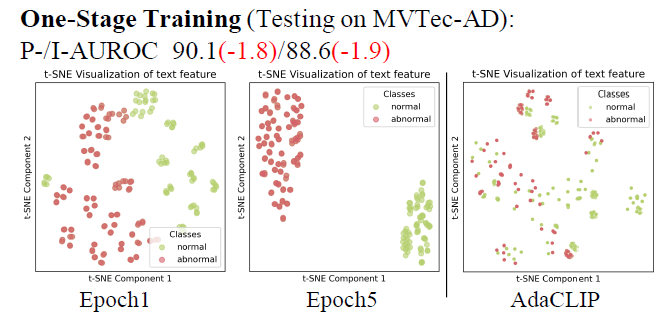
如图1(左)和图2中的示例所示,正常纹理特征和异常纹理特征的重叠影响了基于文本的异常检测的精度。我们认为使CLIP变得异常感知——通过在文本空间中建立明确区分正常语义和异常语义的界限——对于指导视觉编码器精确检测和定位异常是至关重要的。这一观察结果驱使我们通过增强文本空间的异常辨别能力来改进基于CLIP的零样本AD,这通过我们的方法Anomaly-Aware CLIP(AA-CLIP)实现——这是一个具有异常感知信息的CLIP模型。
原理与创新
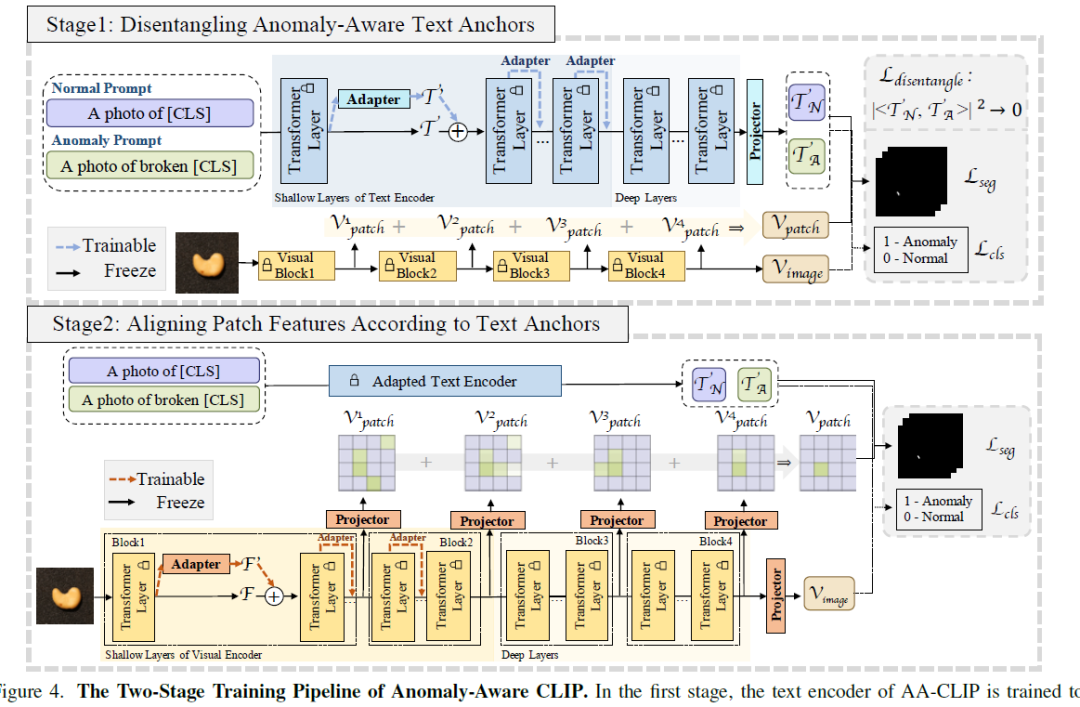
AA-CLIP通过一种新颖的两阶段适应方法实现。
在第一阶段,AA-CLIP使用冻结的视觉编码器适配文本编码器,为每个训练类别创建“锚点”,用于异常感知的语义文本空间。如图1(中间)所示,每个类别的文本特征被分解成不同的锚点,明确区分异常。值得注意的是,这种分解也适用于未见过的类别,支持AD任务中有效的零样本推理(参见图1(右))。
在第二阶段,AA-CLIP将patch级视觉特征与这些特别适配的文本锚点对齐,引导CLIP的视觉编码器集中于异常相关的区域。这种两阶段方法确保了一个集中和精确的异常检测框架。
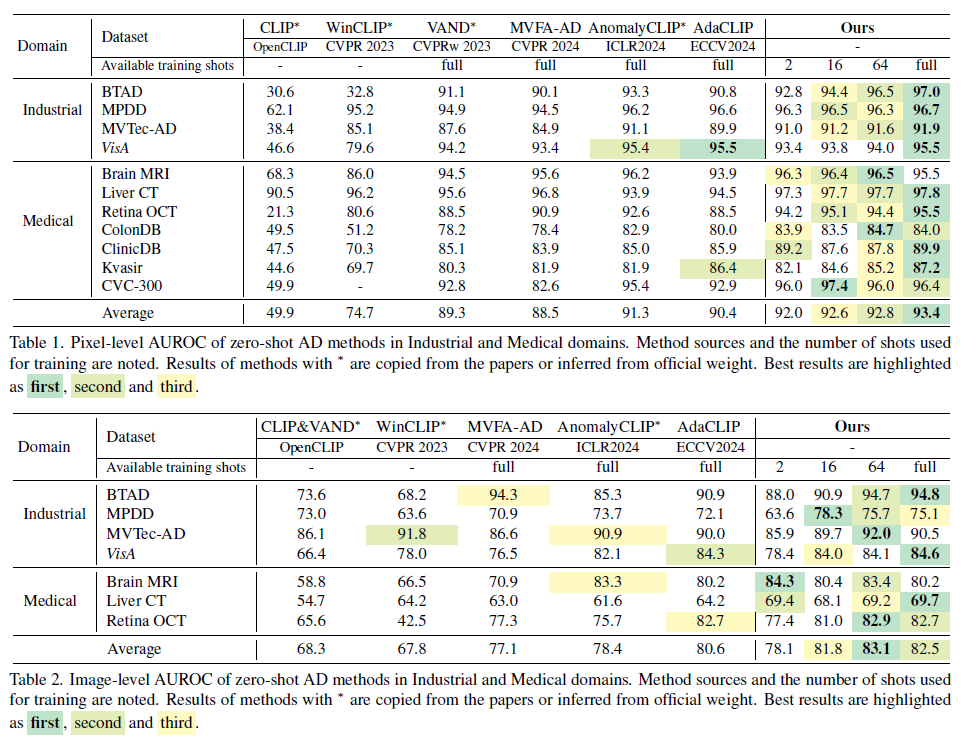
在我们的工业和医学领域的广泛实验中,我们的简单方法使CLIP具备了改进的零样本AD能力,即使在数据有限的情况下也是如此。
通过使用最少的样本进行训练——例如每个类别一个正常样本和一个异常样本(2-shot)——并在未见过的数据集上进行测试,我们的方法实现了与基于CLIP的其他AD技术相当的零样本性能。在训练集中看到每个类别的64个样本时,我们的方法在跨数据集的零样本测试中达到了最先进(SOTA)的结果,验证了AA-CLIP方法在最小数据需求下最大化CLIP的AD潜力的能力。
AA-Clip创新点如下:
1. 异常感知CLIP,具有增强且可泛化的异常辨别能力。我们引入了AA-CLIP,它 sequentially in text and visual spaces, encoding anomaly-aware information
2. 使用残差适配器进行高效适应。我们实现简单的残差适配器以提高零样本异常检测性能,而不会牺牲模型的泛化能力。
3. SOTA性能与高训练效率。我们的方法在不同数据集上实现了SOTA结果,展示了即使在有限的训练样本下也能进行鲁棒的异常检测能力。
架构与实现细节
使用OpenCLIP与ViT-L/14架构作为骨干网络,并将输入图像调整为518×518。所有CLIP的参数保持冻结。
设置λ为0.1,KT为3,KI为6,γ为0.1。为了进行多级特征提取,我们利用视觉编码器的第6、12、18和24层的输出组成整体输出。
第一阶段,我们对模型训练5个周期,学习率为1×10−5。
第二阶段,我们继续训练20个周期,调整学习率为5×10−4。
参数通过Adam优化器进行更新。
所有的实验都在单个NVIDIA GeForce RTX 3090 GPU上进行。
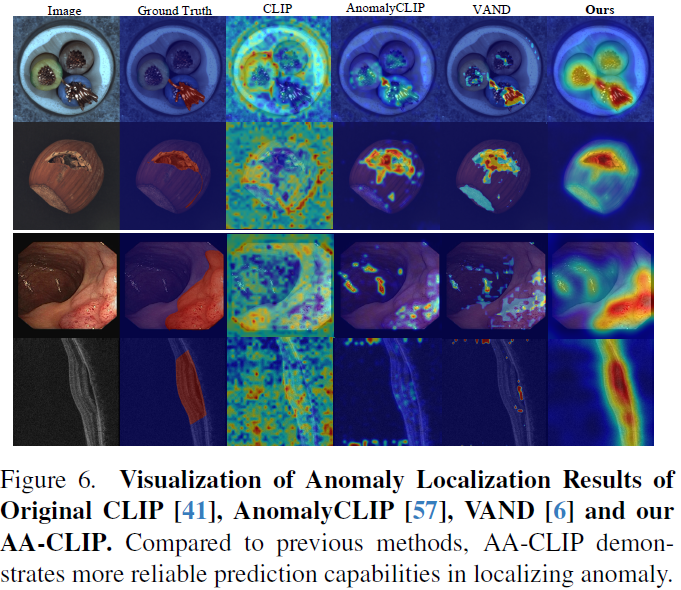
训练效果对比

推荐阅读
OpenCV4.8+YOLOv8对象检测C++推理演示
ZXING+OpenCV打造开源条码检测应用
攻略 | 学习深度学习只需要三个月的好方法
三行代码实现 TensorRT8.6 C++ 深度学习模型部署
实战 | YOLOv8+OpenCV 实现DM码定位检测与解析
对象检测边界框损失 – 从IOU到ProbIOU
初学者必看 | 学习深度学习的五个误区


