



无论是训练大型AI模型,还是进行高性能计算(HPC),还是Deepseek私有化部署,都需要强大的GPU支持。
而英伟达(NVIDIA)作为全球领先的AI芯片制造商,推出了一系列高性能GPU,包括A100、H100、A800、H800、H20等,广泛应用于AI训练、推理、科学计算等领域。

如果想搭建一个属于自己的算力中心,该如何选择合适的GPU?本文将带你详细了解这些GPU的特性,并指导你如何搭建算力中心。
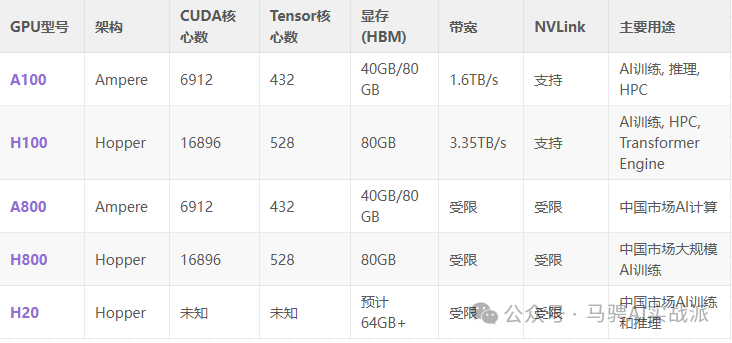
A100是英伟达2020年发布的旗舰级数据中心GPU,基于Ampere架构,主要特性包括:
A100可广泛应用于高性能计算(HPC)和深度学习任务,适用于需要大量计算资源的企业级用户。
H100是A100的升级版,采用更先进的Hopper架构,相比A100提升了数倍的计算性能,主要特性包括:
H100特别适用于大型AI模型训练,比如Llama、GPT、Stable Diffusion等,可以大幅提升训练效率。
A800和H800是英伟达专为中国市场推出的受限版GPU,以符合美国的出口管制要求:
这些GPU主要面向中国客户,如阿里云、腾讯云、百度云等云计算厂商,性能稍逊于A100和H100,但仍然具备极高的计算能力。
H20是英伟达为中国市场设计的新一代受限版H100,预计将取代H800:
H20仍然具备强大的算力,适用于AI训练和推理,但具体性能指标需等待正式发布后确认。
如果你想搭建自己的算力中心,无论是用于AI训练,还是进行高性能计算,都需要从以下几个方面考虑:
首先需要明确你的算力需求:
你可以选择以下方式搭建你的GPU算力中心:
如果对数据隐私和持续算力需求较高,建议选择本地搭建GPU集群。
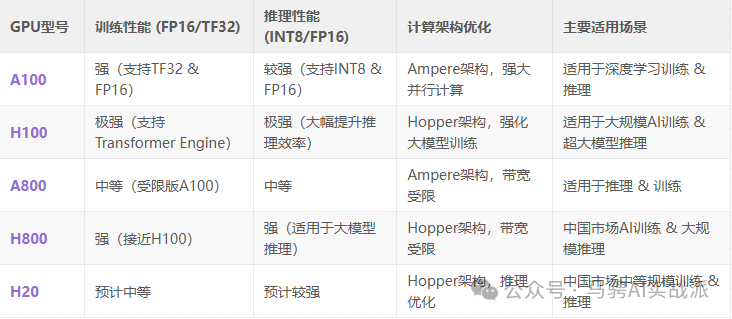
在AI训练(Training)和AI推理(Inference)场景下,不同GPU的性能表现存在明显差异。主要区别体现在计算精度、带宽需求、显存优化以及核心架构等方面。以下是详细对比:
在AI计算中,不同的数值格式影响计算速度和精度:
| FP32 | ||||
| TF32 | ||||
| FP16 | ||||
| INT8 |
H100 特别优化了 Transformer Engine,在 FP8/FP16 下可大幅提升 AI 训练和推理性能,适用于 LLM(大语言模型)如 GPT-4。
训练任务 通常需要处理大规模数据,因此高显存带宽至关重要:
推理任务 一般不需要大带宽,因为:
在计算核心优化上:
| A100 | ||
| H100 | Transformer Engine | |
| A800 | ||
| H800 | ||
| H20 |
H100 在 Transformer-based AI 任务(如 GPT)中比 A100 快 6 倍,而推理吞吐量也更高。
未来,随着 H20 逐步普及,它可能成为中国市场AI训练和推理的首选。
根据GPU型号,搭建算力中心的成本会有所不同:
一个基础的4张H100服务器可能需要20万-50万美元,而大型AI训练集群(如64张H100)则可能超过千万美元。
文章来源:马骋AI实战派
.jpg")
