


随着 AI 技术的飞速发展,大模型的参数量已经从亿级跃升至万亿级,这一变化不仅标志着 AI 的显著提升,也对支持这些庞大模型训练的底层硬件和网络架构提出了前所未有的挑战。为了有效地训练这些复杂的模型,需要依赖于大规模的 GPU 服务器集群,它们通过高速网络相互连接,以便进行快速、高效的数据交换。
但是,即便是最先进的 GPU 也可能因为网络瓶颈而无法充分发挥其计算潜力,导致整个算力集群的性能大打折扣。这一现象凸显了在构建大规模 GPU 集群时,仅仅增加 GPU 数量并不能线性增加集群的总体算力。相反,随着集群规模的扩大,网络通信的额外开销也会成倍增加,严重影响计算效率。
在这种背景下,算存互连(即计算与存储之间的连接)和算力互连(即计算单元之间的连接)的重要性变得日益突出。这些互连技术是实现高效大规模并行计算的关键,它们确保数据可以迅速在处理单元和存储设备间传输,最大限度地减少通信延迟,提高整体系统性能。
更多GPU技术请参考“《100+份AI芯片技术修炼合集》”,本文来自"GPU原理详解:NVLink基础与结构",“GPU原理详解:Tensor Core原理”,“GPU原理详解:Tensor Core架构演进”,“GPU原理详解:Tensor Core深度剖析”,“GPU原理详解:分布式训练与NVLink发展”和“GPU原理详解:NVSwitch基础和原理”。
PCIe 是一种高速串行计算机扩展总线标准,广泛应用于连接服务器中的 GPU、SSD 等设备。它通过提供高带宽和低延迟的数据传输,支持了复杂计算任务的需求。然而,随着计算需求的不断增长,PCIe 的带宽可能成为限制因素。
英伟达的 NVLink 技术则为 GPU 之间提供了更高速度的数据交换能力,其传输速度远超传统的 PCIe 连接,使得数据在 GPU 之间的传输更加高效。此外,NVSwitch 技术进一步扩展了这种能力,允许多达数十个 GPU 之间实现高速、高带宽的直接连接。这种先进的互连技术极大地提高了大规模 GPU 集群处理复杂模型时的数据交换效率,降低了通信延迟,从而使得万亿级别的模型训练成为可能。
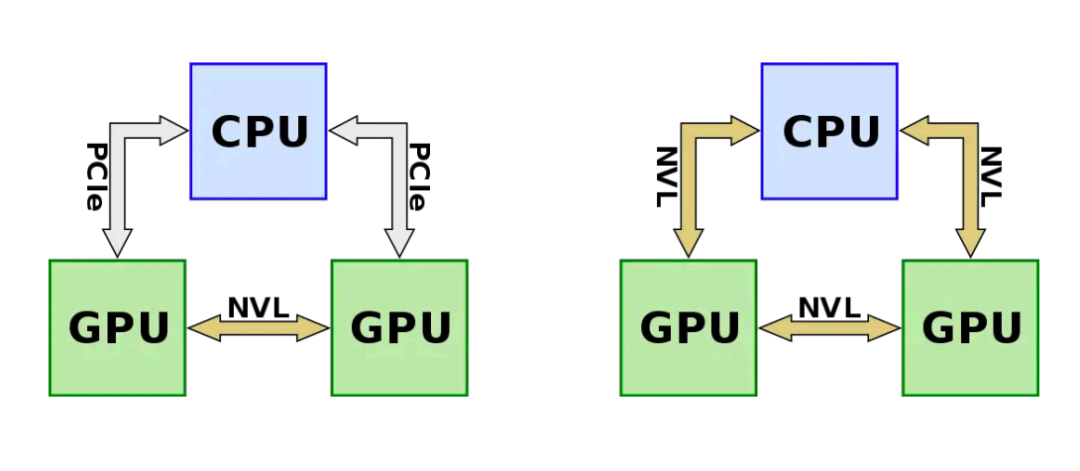
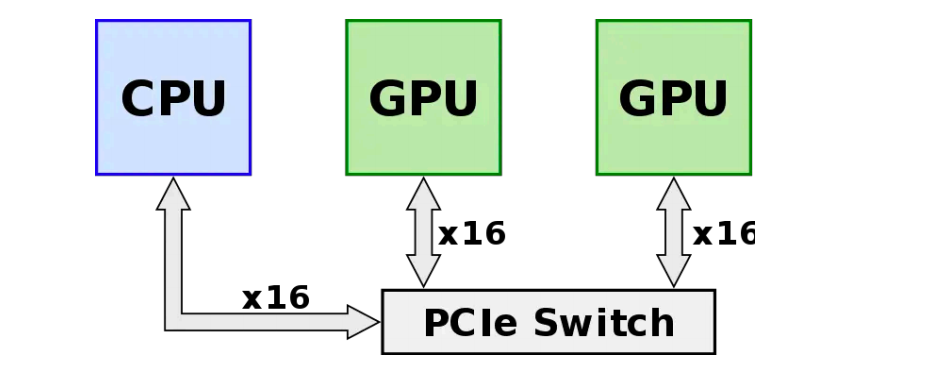
在英伟达推出其创新的 NVLink 和 NVSwitch 互联技术之前,构建强大计算节点的常规方法是通过 PCIe 交换机将多个 GPU 直接连接到 CPU,如下图所示。这种配置方式依赖于 PCIe 标准,尤其是 PCIe 3.0 版本,它为每个通道提供了大约 32GB/s 的双向带宽。虽然这在当时被视为高效的数据传输方式,但随着 AI 和机器学习领域的快速发展,数据集和模型的规模呈指数级增长,这种传统的 GPU-CPU 互联方式很快成为了系统性能提升的瓶颈。
随着新一代 GPU 性能的显著提升,它们处理数据的能力大幅增强,但如果互联带宽没有相应的提升,那么这些 GPU 就无法充分发挥其性能潜力。数据传输速度不足意味着 GPU 在处理完当前数据之前,需要等待下一批数据的到来,这导致了计算效率的显著下降。在这种情况下,即使是最先进的 GPU 也无法满足日益增长的计算需求,限制了大规模并行计算系统的整体性能。
如图所示,在现代 GPU 架构中,单个 GPU 内部包含了多个流多处理器(SM)核心,这些核心是实现并行计算的基石。通过 CUDA(Compute Unified Device Architecture)技术,开发者能够编写程序来驱动这些硬件单元并行执行复杂的计算任务。CUDA 不仅为程序员提供了一种高效的方式来利用 GPU 的并行处理能力,还极大地简化了并行计算程序的开发过程。
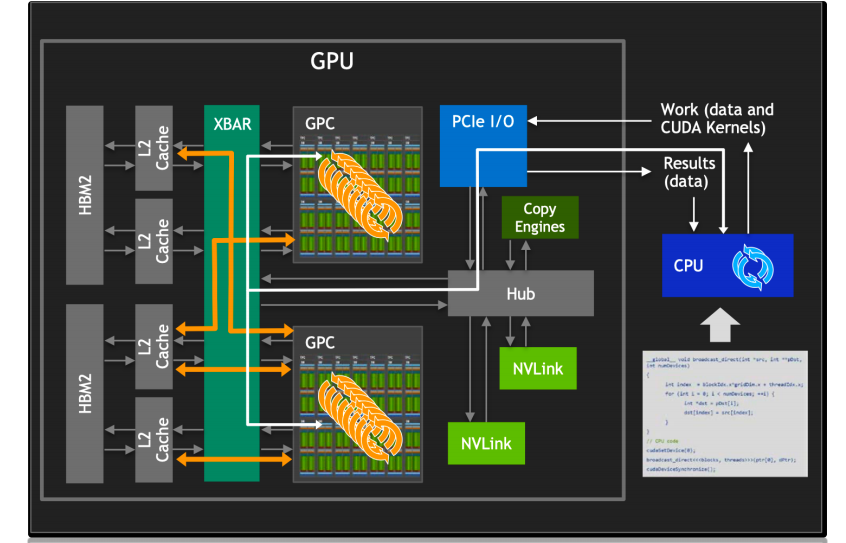
而在 GPU 内部,工作任务被划分并分配给每个图形处理簇(GPC)和流多处理器(SM)核心。这种工作分配机制确保了 GPU 的计算资源得到充分利用,每个核心都在执行计算任务,从而实现了高效的并行处理。为了支持这种高速计算,GPU 通常配备有高带宽内存(HBM),它为 GPC/SM 核心提供了快速访问大量数据的能力,从而保证了数据密集型任务的高效执行。
HBM(High Bandwidth Memory)是一种堆叠式内存技术,它通过宽接口和高传输速率显著提升了内存带宽。这对于处理大规模数据集和复杂计算尤为重要,因为它确保了数据能够迅速地供给到每个 GPC/SM 核心进行处理。此外,GPC/SM 核心之间能够共享 HBM 中的数据,这一特性使得数据交换更为高效,进一步提升了整体的计算性能。
从上面可以看出,在现代 GPU 架构中,主要涉及 GPU 之间的通信和数据交换通常涉及以下几个方面:
GPU 间 PCle 互联
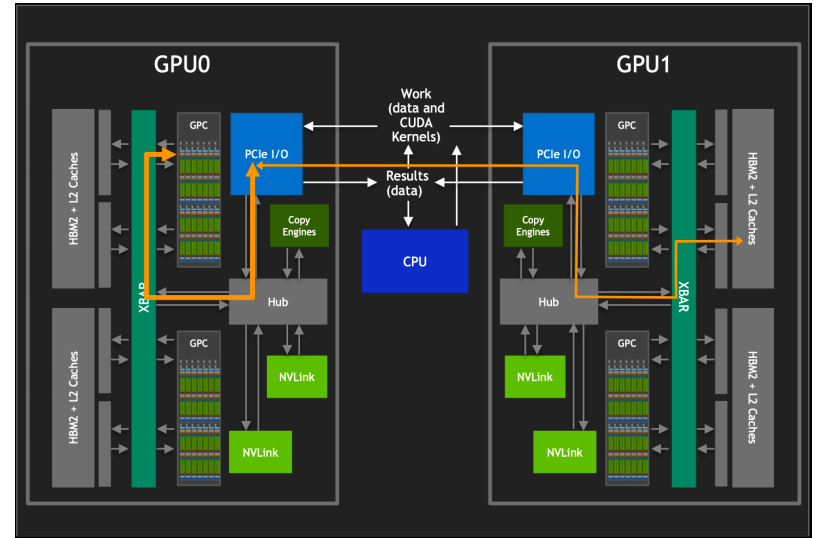
PCIe 通信:当多个 GPU 在没有专用高速互连技术(如 NVLink)的系统中协同工作时,它们之间的通信通常是通过 PCI Express(PCIe)总线进行的。PCIe 是一种高速串行计算机扩展总线标准,用于连接主板上的硬件设备。但是,由于 PCIe 的带宽有限,它可能成为 GPU 之间高速数据传输的瓶颈。
对 HBM 的访问:如果一个 GPU 需要直接访问另一个 GPU 的 HBM 内存,数据必须通过 PCIe 总线传输,这会受到 PCIe 带宽的限制。这种通信方式比 GPU 内部访问 HBM 的速度慢得多,因为 PCIe 的带宽远低于 HBM 的内存带宽。
通过 CPU 的调度:在没有直接 GPU 对 GPU 通信能力的系统中,CPU 充当数据交换的中介。CPU 负责在多个 GPU 之间分配和调度计算任务,以及管理数据在 GPU 和系统内存之间的传输。
这就使得 PCIe 的带宽限制成为多 GPU 系统中的一个限制因素。特别是当工作负载需要频繁的 GPU 间通信时,在数据传输密集型的应用中,这种限制可能导致性能下降。
GPU 间 NVLink 互联
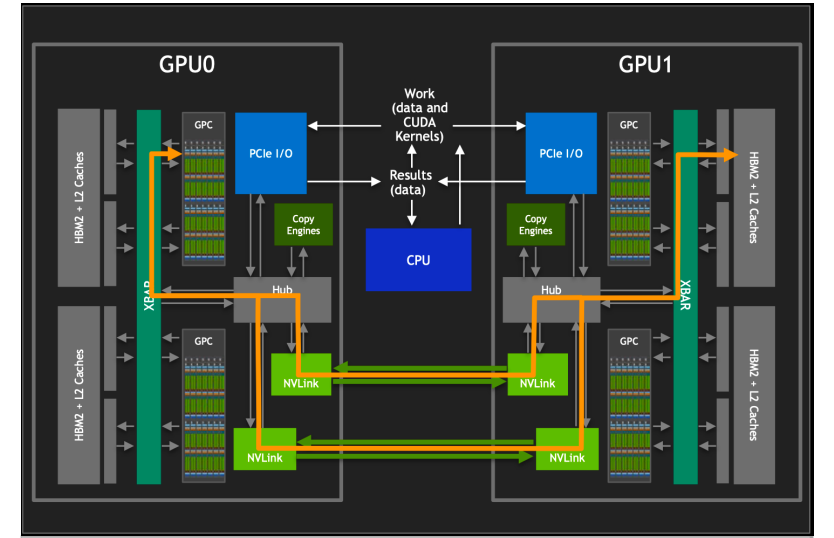
NVLink 的出现为 GPU 间的互联提供了一种革命性的方式,使得不同 GPU 之间的通信和数据共享变得更加高效和直接。
通过 NVLink,GPU 的图形处理簇(GPCs)可以直接访问连接在同一系统中其他 GPU 上的高带宽内存(HBM)数据。这种直接的内存访问机制显著降低了数据交换的延迟,并提高了数据处理的速度。同时,NVLink 支持多条链路同时操作,这意味着可以通过多条 NVLink 同时对其他 GPU 内的 HBM 数据进行访问,极大地增加了带宽和通信速度。每条 NVLink 链路都提供了远高于 PCIe 的数据传输速率,多条链路的组合使得整体带宽得到了成倍增加。
此外,NVLink 不仅仅是一种点对点的通信协议,它还可以通过连接到 GPU 内部的交换机(XBARs)来实现更复杂的连接拓扑。这种能力使得多 GPU 系统中的每个 GPU 都能以极高的效率访问其他 GPU 的资源,包括内存和计算单元。而且,NVLink 并不是要取代 PCIe,而是作为一种补充和增强。在某些情况下,系统中可能同时使用 NVLink 和 PCIe,其中 NVLink 用于高速 GPU 间通信,而 PCIe 则用于 GPU 与其他系统组件(如 CPU、存储设备)之间的通信。这种设计允许系统根据不同的通信需求灵活选择最合适的技术,从而最大化整体性能和效率。
多GPU 间 NVLink 互联
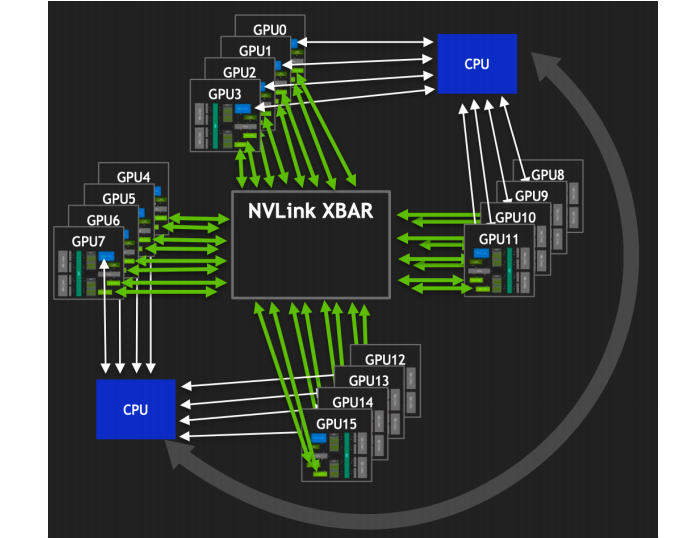
如上图所示,NVLink 技术的引入不仅仅是为了加速 GPU 间的通信,它还极大地扩展了多 GPU 系统的潜力。
多 GPU 互联能力的提升:NVLink 极大地提高了多 GPU 之间的互联能力,使得更多的 GPU 可以高效地连接在一起。这种增强的互联能力不仅提升了数据传输的速度和效率,而且还使得构建大规模 GPU 集群成为可能。在深度学习、科学模拟等领域,这意味着可以处理更复杂的问题,实现更高的计算性能。
单一 GPU 驱动进程的全局控制:通过 NVLink,单个 GPU 驱动进程可以控制所有 GPU 的计算任务,实现任务的高效分配和管理。这种集中式控制机制简化了多 GPU 系统的编程和使用,使得开发者能够更容易地利用系统中所有 GPU 的计算能力,从而加速复杂计算任务的处理。
无干扰的 HBM 内存访问:NVLink 还允许 GPU 在不受其他进程干扰的情况下直接访问其他 GPU 的 HBM 内存。通过使用 LD/ST 指令和远程直接内存访问(RDMA)技术,数据可以在 GPU 之间高效地传输,极大地提高了内存访问的速度和效率。这种无干扰的访问机制对于需要大量数据交换的应用至关重要,因为它减少了数据传输的延迟,提高了整体的计算性能。
XBAR 的独立演进与带宽提升:GPU 内部的交换机(XBAR)作为桥接器,可以独立于 GPU 核心演进发展,提供更高的带宽和更灵活的连接拓扑。这种设计使得 NVLink 不仅能够支持当前的高性能计算需求,而且还具备了未来进一步扩展和提升性能的潜力。随着 XBAR 技术的发展,我们可以期待 NVLink 将会支持更加复杂和高效的多 GPU 连接方案,进一步推动高性能计算的极限。
本文所有资料都已上传至“智能计算芯知识”星球。如“《60+份AI Agent技术报告合集》”,“《清华大学:DeepSeek报告13部曲合集》”,“浙江大学:DeepSeek技术14篇(合集)”,“《280+份DeepSeek技术报告合集》”,“《100+份AI芯片技术修炼合集》”,“800+份重磅ChatGPT专业报告”,“《12+份Manus技术报告合集》”,加入星球获取严选精华技术报告。
下载链接:
8、《3+份技术系列基础知识详解(星球版)》
9、《12+份Manus技术报告合集》
10、《100+份AI芯片修炼合集》
11、《60+份AI Agent技术报告合集》
《270+份DeepSeek技术报告合集》
《42篇半导体行业深度报告&图谱(合集)
亚太芯谷科技研究院:2024年AI大算力芯片技术发展与产业趋势
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


