

 点击上方蓝字关注我们
点击上方蓝字关注我们微信公众号:OpenCV学堂
关注获取更多计算机视觉与深度学习知识
免费领学习资料+微信:OpenCVXueTang_Asst
YOLO12介绍
YOLOv12 超过了之前的YOLO11、 RTDETR 、 RT-DETRv2。其中YOLOv12-S 比 RT-DETR-R18 和 RT-DETRv2-R18 快 42%,使用的计算量和参数分别减少了 36% 和 45%。
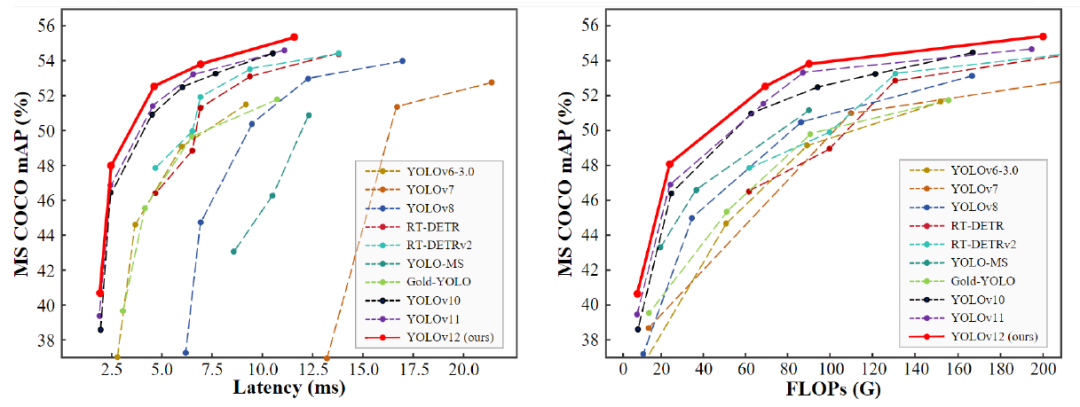
残差连接在较小模型(YOLOv12-N)中对收敛几乎没有影响,但在较大模型(YOLOv12-L/X)中对稳定训练至关重要,其中 YOLOv12-X 需要一个缩放因子为 0.01。区域注意力模块将推理时间减少了 0.7 ms,在 RTX 3080 上使用 FP32 精度进行推理时,而 FlashAttention 进一步加速了推理,时间为 0.3–0.4 ms。
可视化分析确认 YOLOv12 产生了更清晰的物体轮廓和更精确的前景激活,超过了之前的YOLO系列模型。基于卷积的注意力实现比线性替代方案更快。
此外,分层设计、扩展训练(约 600 个epoch)、优化的卷积核大小(7 × 7)、缺失位置嵌入以及 MLP 比例为 1.2 collectively 提高了框架的性能和效率。
模型架构与创新
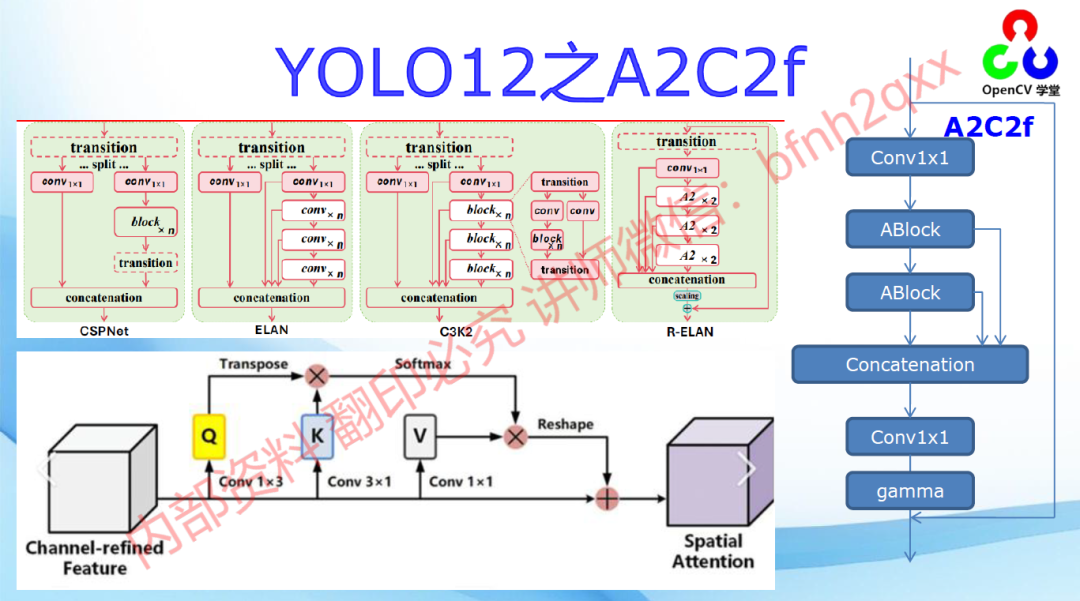
YOLOv12 架构展示了 A2(区域注意力)模块、R-ELAN(残差高效层聚合网络)块和简化检测头的先进集成。
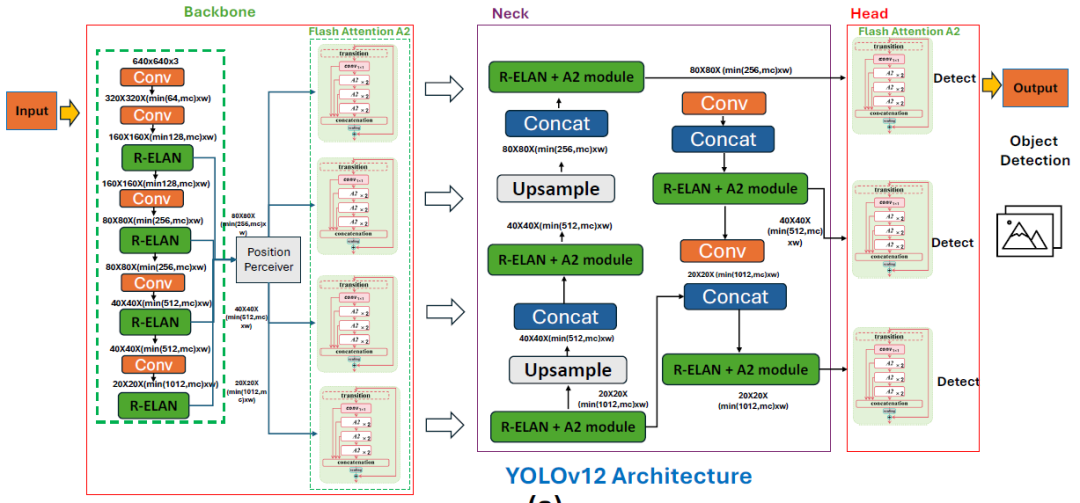
这种设计优化了模型的视觉信息处理,同时保持了高准确性。YOLOv12 架构的主要创新如下:
• 区域注意力(A2)模块:该模块通过空间重塑实现分段特征处理,集成了 Flash Attention,通过减少计算复杂度降低了 50%,同时保持了大的感受野。AA 使得在固定 n = 640 分辨率下进行实时检测成为可能,并通过优化的内存访问模式实现了这一点。
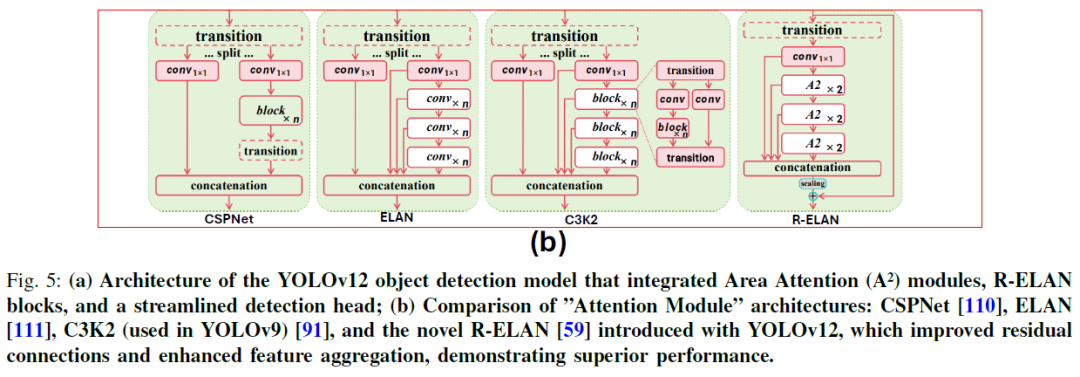
• 残差 ELAN(R-ELAN)层次结构:R-ELAN 结合了残差快捷方式(缩放因子为 0.01)和双分支处理以减轻梯度消失问题。模型还具有简化的最终聚合阶段,该阶段将参数减少了 18%,并将 FLOPs 减少了 24% 与基线架构相比。
• 高效的架构修改:YOLOv12 用 7×7 深度卷积替换位置编码,以实现隐式空间感知。它还实现了自适应 MLP 比例(1.2×)和浅层块堆叠以平衡计算负载,在 V100 硬件上实现了 4.1 ms 推理延迟。
• 优化的训练框架:该模型使用 SGD 和余弦调度进行了 600 个周期的训练(初始 lr=0.01)。模型还结合了 Mosaic-9 和 Mixup 增强,在 COCO 数据集上获得了 12.8% mAP 的增益,通过选择性内核卷积集成保持实时性能。
关键模块结构解读
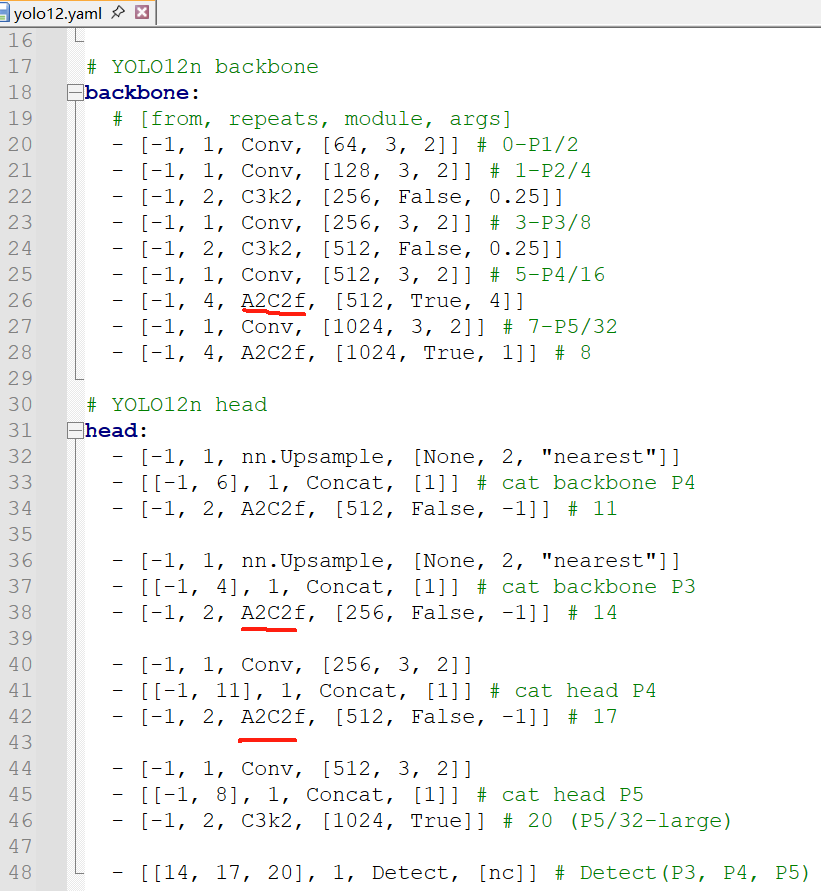
其中A2C2f是YOLO12模型的关键结构,主要模型结构由以下几个部分组成:
模型推理与测试
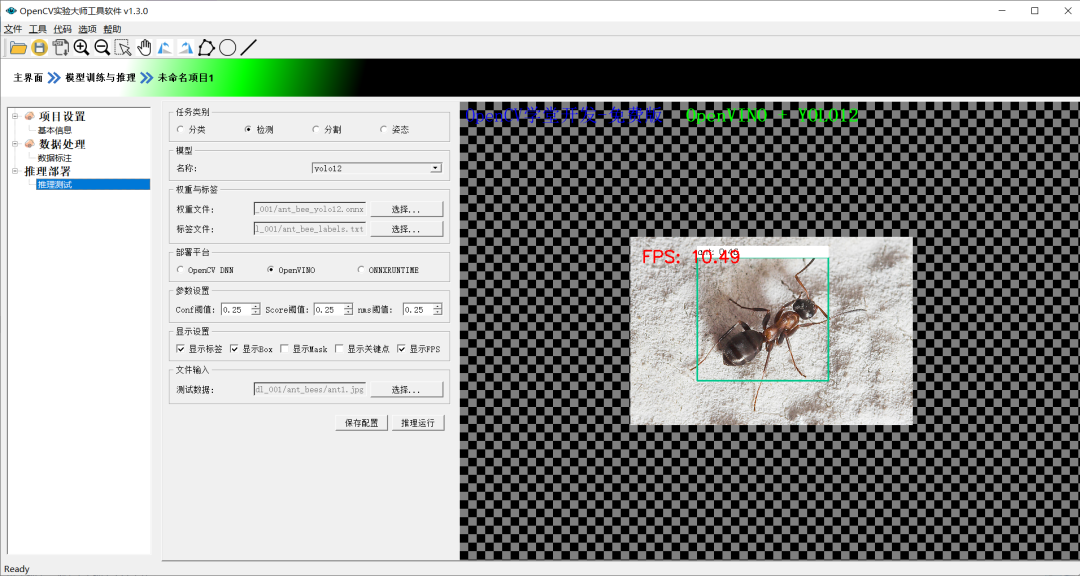
OpenCV实验大师工具软件已经完成YOLO12模型推理支持,下载软件以后,直接配置好即可运行。下图是YOLO12自定义对象检测模型的推理演示:
YOLO12分割模型的工业品缺陷检测

学会YOLOv8就会通杀YOLO系列所有模型!


推荐阅读
OpenCV4.8+YOLOv8对象检测C++推理演示
ZXING+OpenCV打造开源条码检测应用
攻略 | 学习深度学习只需要三个月的好方法
三行代码实现 TensorRT8.6 C++ 深度学习模型部署
实战 | YOLOv8+OpenCV 实现DM码定位检测与解析
对象检测边界框损失 – 从IOU到ProbIOU
初学者必看 | 学习深度学习的五个误区

