随着嵌入式系统在各种应用中的普及,NAND闪存作为存储介质,因其高密度、低成本、低功耗等优势,广泛应用于智能手机、嵌入式设备、消费电子、汽车电子等领域。
然而,NAND闪存并非完美无缺,存在着坏块(Bad Block)的问题。
坏块会导致数据无法正常读写,因此必须采取有效的管理和恢复策略。
1
NAND闪存的工作原理
在深入坏块管理之前,了解NAND闪存的基本工作原理是必要的。
NAND闪存由多个块(Block)组成,每个块中包含若干页(Page)。每页的容量通常为2KB到16KB不等。写操作是按页进行的,擦除操作则是按块进行的。擦除周期和写入周期是有限的,这使得闪存具有有限的使用寿命。
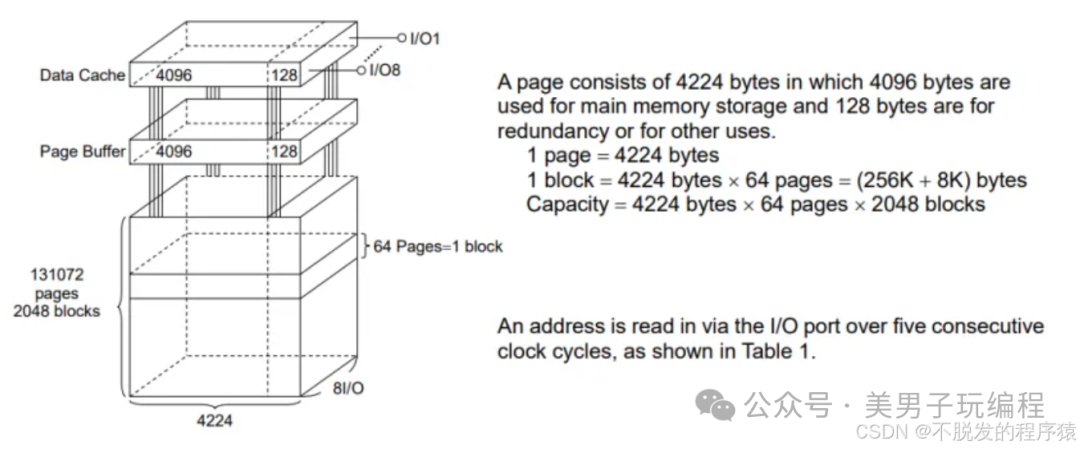
由于NAND闪存的工作机制,在长时间使用后,部分块可能出现故障,无法正确读写,这些故障的块即为坏块。坏块一旦被发现,必须标记为不可用,且在以后进行数据存储时,应该避免对这些块进行访问。
NAND闪存的坏块是指在出厂时或使用过程中出现故障的块。坏块的故障类型通常包括:
由于NAND闪存是块为单位进行管理的,因此一旦一个块被标记为坏块,整个块都会被视为不可用。
2
坏块管理策略
2.1. 坏块标记与管理
坏块的标记通常是通过一个坏块标记表(Bad Block Table, BBT)来实现。BBT是一个映射表,用于记录哪些块是坏块。该表一般保存在NAND闪存的预留区域(如主引导区)中。每次擦除NAND闪存时,都会检查每个块的健康状况,并更新坏块表。
在NAND闪存的初始化过程中,系统会扫描所有的块,并测试每个块的读写能力。对于无法正常工作或表现异常的块,系统会将其标记为坏块,并将其从正常使用的块列表中移除。这个过程被称为坏块管理。
2.2. 物理坏块与逻辑坏块
在实际应用中,坏块的管理不仅仅是物理坏块的处理,还包括逻辑坏块的管理。逻辑坏块是指系统认为已经失效的块,但实际上它可能只是部分页出现故障。通过逻辑块替换机制,系统可以将部分页故障的块的使用范围缩小,从而延长闪存的使用寿命。
2.3. 使用过期块替换策略
在一些嵌入式设备中,如果一个块被发现是坏块,并且无法修复,系统需要通过替代块的方式进行替换。这个过程通常使用过期块替换策略,通过将坏块中的数据迁移到其他健康块来解决问题。操作系统会保持对每个块的管理,确保坏块被及时替换并减少数据丢失的风险。
3
错误恢复策略
3.1. ECC(错误检测与纠正)
错误检测与纠正(Error Correction Code, ECC)是NAND闪存中常用的一种技术。NAND闪存的一个重要特点是它可能会发生数据位翻转,导致存储的数据错误。
为了防止这种错误带来的数据丢失,ECC通过编码技术为每个数据块增加冗余位。当数据读取时,如果检测到错误,ECC可以使用冗余位进行纠正,从而恢复正确的数据。
常见的ECC算法包括汉明码、BCH码、Reed-Solomon码等。这些算法在读取数据时能够对误码进行修正,提高数据的可靠性。
3.2. 迁移与冗余技术
如果某一块出现持续性的错误,系统可以使用迁移技术将数据迁移到新的块中。
具体而言,当一个块被标记为坏块后,系统会将该块中的有效数据迁移到健康块上,并更新相应的坏块表。通过冗余技术,系统可以确保数据不因单块故障而丢失。
3.3. 坏块擦除与再利用
对于一些设备,擦除坏块是一个常见的策略。
系统可以尝试擦除坏块并重新使用它,但这并不总是可靠,尤其是对于严重损坏的块。
因此,在擦除坏块之前,必须对其进行全面的检测,确保它确实可以重新使用。
3.4. 故障预测与提前处理
现代NAND闪存控制器可以通过分析块的健康状况,预测故障的发生时间。
例如,一些闪存控制器会通过分析读写次数、擦除次数和数据误差来推测块的健康状况,从而提前做出应对措施。这可以通过定期对NAND闪存进行健康检查来实现。
以下是一个简化的坏块管理与错误恢复的示例代码,展示了如何在嵌入式系统中实现基本的坏块标记、管理和恢复策略。
typedefstruct {uint32_t block_id;bool is_bad;} BlockInfo;BlockInfo bad_block_table[MAX_BLOCKS];// 模拟NAND闪存块初始化voidnand_flash_init(){// 假设块初始化时扫描所有块并检测坏块for (int i = 0; i < MAX_BLOCKS; i++) {if (is_bad_block(i)) {bad_block_table[i].block_id = i;bad_block_table[i].is_bad = true;} else {bad_block_table[i].block_id = i;bad_block_table[i].is_bad = false;}}}// 模拟判断块是否为坏块boolis_bad_block(uint32_t block_id){// 这里假设块ID为偶数的块是坏块return (block_id % 2 == 0);}// 模拟读取数据intnand_flash_read(uint32_t block_id, uint32_t page_id, uint8_t *buffer){if (bad_block_table[block_id].is_bad) {printf("Block %d is bad. Reading from another block...\n", block_id);// 在坏块发生时,可以进行数据迁移或读取其他块return-1; // 读取失败}// 正常读取操作printf("Reading data from Block %d, Page %d...\n", block_id, page_id);return0; // 读取成功}// 模拟写入数据intnand_flash_write(uint32_t block_id, uint32_t page_id, uint8_t *buffer){if (bad_block_table[block_id].is_bad) {printf("Block %d is bad. Cannot write data.\n", block_id);return-1; // 写入失败}// 正常写入操作printf("Writing data to Block %d, Page %d...\n", block_id, page_id);return0; // 写入成功}intmain(){// 初始化闪存并检测坏块nand_flash_init();// 尝试读取一个坏块的数据uint8_t buffer[256];nand_flash_read(2, 0, buffer);return0;}
代码说明:
NAND闪存的坏块管理与错误恢复策略是嵌入式系统开发中的一个重要问题。通过有效的坏块标记、ECC算法、迁移与冗余技术等手段,可以有效提高系统的可靠性和数据安全性。
随着技术的不断进步,未来的NAND闪存控制器将能够更好地处理坏块,提高闪存的使用寿命和稳定性,为嵌入式系统提供更加可靠的存储解决方案。