

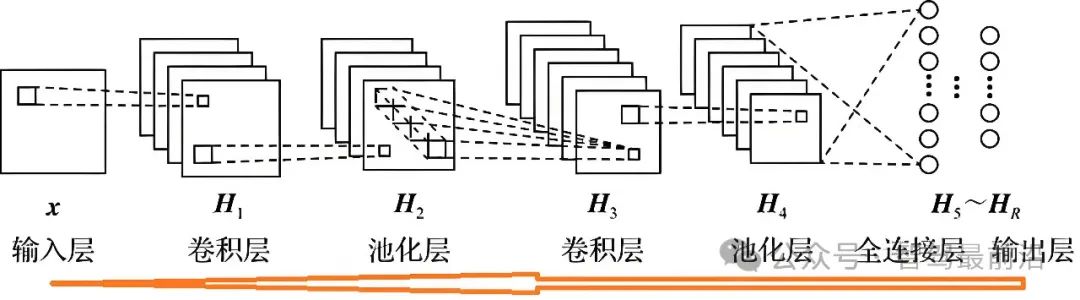
卷积神经网络(Convolutional Neural Networks, CNN)的核心技术主要包括以下几个方面:局部连接、权值共享、多卷积核以及池化。这些技术共同作用,使得CNN在图像和语音识别等领域取得了显著成就,并广泛用于车辆自动驾驶的图像目标识别中。
1.局部连接:CNN通过局部连接的方式减少了网络自由参数的个数,从而降低了计算复杂度,并使网络更易于训练。与全连接网络不同,CNN中的每个神经元仅与输入数据的一部分相连,这一部分被称为感受野。这种设计模拟了人类视觉系统对图像亮度、纹理、边缘等特性的逐层提取过程。
2.权值共享:权值共享是CNN另一个重要的特性,它进一步减少了模型参数的数量。在CNN中,同一卷积核在整个输入图像上滑动进行卷积运算,这意味着所有位置共享相同的权重参数。这样不仅减少了需要学习的参数数量,还增强了模型的泛化能力。
3.多卷积核:使用多个不同的卷积核可以从输入数据中提取出多种类型的特征。每个卷积核负责检测特定类型的模式或特征,如边缘、角点等。通过组合多个卷积核的结果,CNN能够捕捉到更加丰富和复杂的特征表示。
4.池化(Pooling):池化操作用于降低特征图的空间尺寸,减少计算量并防止过拟合。常见的池化方法有最大池化(Max Pooling)和平均池化(Average Pooling)。池化层通常紧跟在卷积层之后,通过对特征图进行下采样来保留最重要的信息,同时丢弃冗余信息。
可以将整个过程视为一个分层特征提取的过程。首先,通过卷积操作提取低级特征;然后,经过非线性激活函数处理后,利用池化操作降低维度;最后,在高层中逐步构建更为抽象和复杂的特征表示。这样的架构使得CNN特别适合处理具有网格状拓扑结构的数据,如图像和视频。
CNN的基础框架随着研究的发展,新的改进和技术也被不断引入,例如深度可分离卷积、残差连接等,以提高性能并解决特定问题。
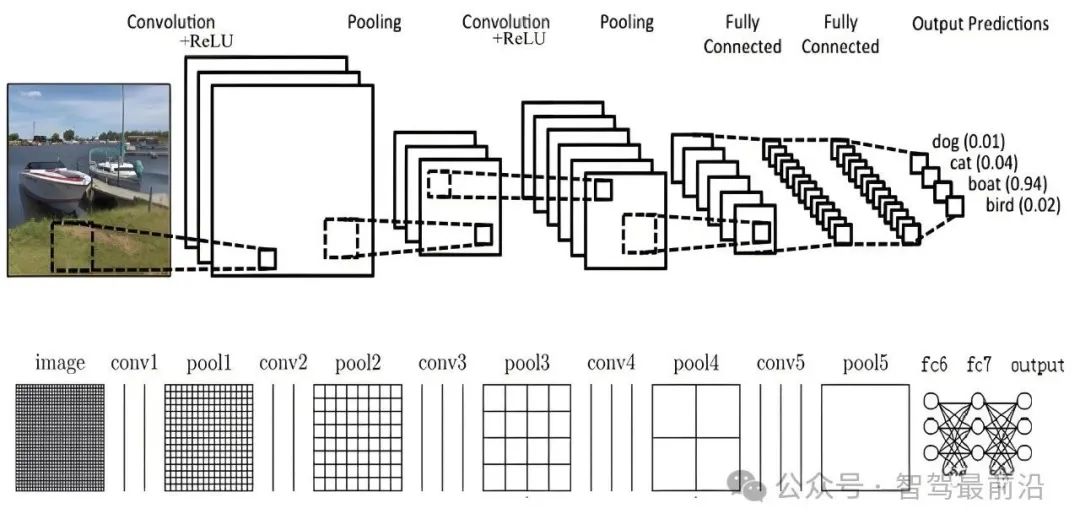
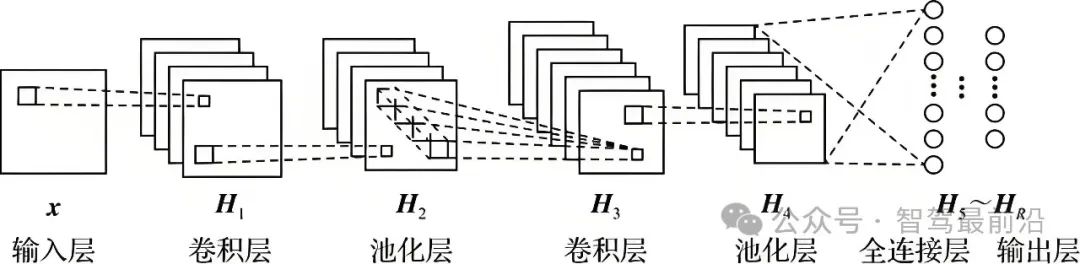
图1卷积神经网络的基本组成,图片来自网络
CNN的基础网络,无非是卷积层,池化层和全连接层(FC,full connection)。所谓输入层和输出层并不是真正的网络layer。
1.LeNet-5
由Yann LeCun杨立昆于1998年提出,主要用于手写数字识别,奠定了现代卷积神经网络的基础。
2.AlexNet
在2012年的ImageNet竞赛中赢得了冠军,显著提升了深度学习在图像分类领域的影响力。它首次大规模使用ReLU激活函数,并引入了Dropout技术来减少过拟合。
3.VGGNet
由牛津大学的Visual Geometry Group提出,以其简单而深刻的结构著称。VGGNet通过堆叠多个3x3的小卷积核来构建更深的网络,证明了深度对于提高性能的重要性。
4.GoogLeNet (Inception)
提出了Inception模块,该模块允许在一个层内同时进行不同大小的卷积操作,从而有效增加了网络宽度而不显著增加计算成本。GoogLeNet是2014年ILSVRC比赛的获胜者之一。
5.ResNet (Residual Network)
解决了非常深网络中的梯度消失问题,通过引入残差连接使得训练更深的网络成为可能。ResNet在2015年的ImageNet竞赛中取得了优异成绩,并推动了深度学习模型向更深方向发展。
残差连接是CNN发展的里程碑之一,所以展开论述。
ResNet(残差网络,Residual Network)中的残差连接通过引入直接的跳跃连接来解决深度神经网络中的梯度消失和梯度爆炸问题,从而使得训练非常深的网络成为可能。
残差连接的核心思想是在网络的一层或多层之间引入直接连接,允许输入特征未经处理地传递到后续层。这样做的目的是让网络学习输入和输出之间的残差(即差异),而不是直接学习一个完整的映射。这种机制有助于梯度在训练过程中更有效地回流,减轻了深度网络中梯度消失的问题。
在ResNet中,每个卷积块(Residual Block)都包含一个或多个卷积层,并且通过残差连接将当前块的输出与前一个块的输出相加,然后通过激活函数(如ReLU)进行激活。具体来说,给定一个输入x,经过一个残差块后,输出可以表示为:
y=F(x)+x
其中F(x) 表示通过卷积层和其他非线性变换后的结果,而 x 是原始输入。这种结构允许网络学习残差函数 F(x)=y−x,从而更容易优化深层网络。
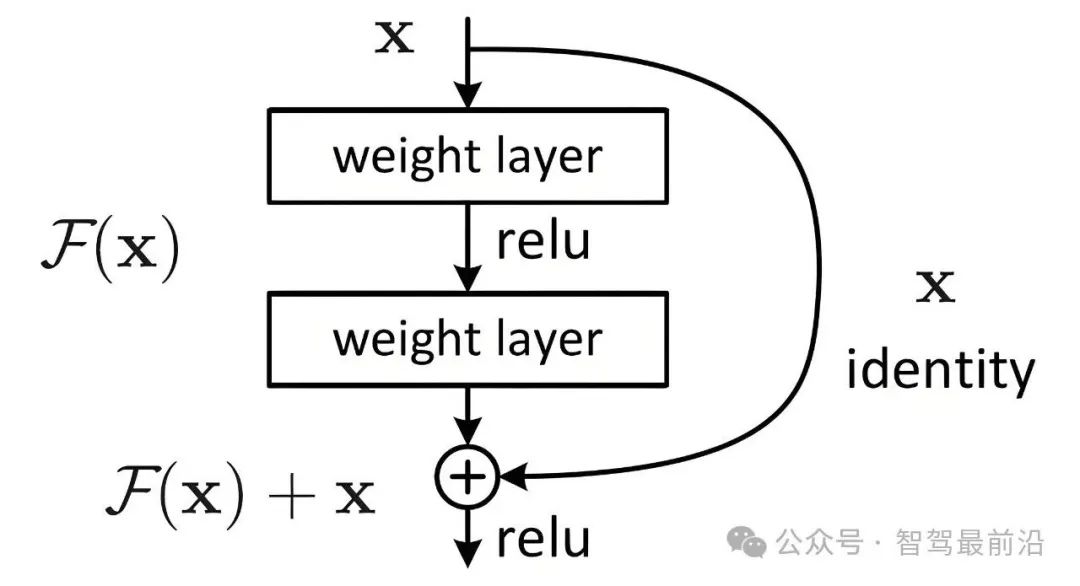
图2跨层残差设计,图片来自网络
残差连接的作用包括缓解梯度消失问题:通过残差连接,梯度可以在训练过程中更直接地从后向传播到前面的层,避免了梯度消失现象的发生;促进信息流动:残差连接提供了一条额外的数据路径,使数据能够跳过某些层直接到达网络的更深部分。提高模型表达能力:残差块的设计使得每一层不仅可以学习新的特征,还可以保留来自前面层的信息,增强了模型的整体表达能力。
敏锐的读者会注意到残差连接会越过两层,为什么不是单层呢?
残差连接经过两层的设计主要是为了更好地学习复杂的残差函数,同时避免了单层网络可能带来的局限性。主要考虑有如下几个:
复杂函数逼近:在残差网络中,假设期望的结果为一个潜在映射(),可以表示为 ()=()+。其中 ()是残差块中的主要学习部分。如果仅使用一层卷积层来构建 (),则可能无法充分捕捉到输入数据的复杂特征。通过引入两层卷积层,模型能够更有效地逼近复杂的非线性映射关系(单层点积是线性,多层叠加表示是非线性关系),从而提高模型的表现力。
梯度流动与稳定训练:深层神经网络的一个常见问题是梯度消失或爆炸,这会阻碍模型的有效训练。通过增加额外的一层(即两层结构),可以在一定程度上缓解这一问题。具体来说,这种设计允许梯度通过跳跃连接直接传递到较深的层,而不需要完全依赖每一层的学习效果。这样不仅促进了梯度的流动,还使得训练更加稳定和高效。
增强表达能力:尽管单层残差块理论上也可以工作,但它们通常缺乏足够的容量去描述那些需要更高维度特征空间才能准确表达的模式。相比之下,双层架构提供了更多的自由度,让网络能够在保持简单性的同时拥有更强的表达能力。此外,多层结构还有助于减少过拟合风险,并且更容易实现正则化目标。
理论支持与实验验证:从理论上讲,具有两个卷积层的残差块可以看作是在原始输入基础上叠加了一个小的修正项。这种方法既保留了原始信号的信息,又允许网络专注于学习剩余的变化部分。
实验表明,双层残差设计优于单层。
6.DenseNet (Densely Connected Convolutional Networks)
每一层都与之前的所有层直接相连,最大限度地重用特征,减少了参数数量并增强了特征传播。这种设计有助于缓解梯度消失问题并促进特征复用。
7.ZFNet
是AlexNet的一个改进版本,在保持相似复杂度的情况下提高了精度。ZFNet调整了卷积核尺寸和其他超参数以更好地适应特定任务。
总结表如下:
CNN 架构 | 年份 | 主要贡献 | 特点 |
LeNet-5 | 1998 | 手写数字识别 | 简单有效的卷积层和池化层 |
AlexNet | 2012 | ImageNet竞赛冠军 | 大规模ReLU、Dropout、GPU加速 |
VGGNet | 2014 | 深度与小卷积核 | 堆叠多层3x3卷积核 |
GoogLeNet | 2014 | Inception模块 | 不同尺度的卷积操作 |
ResNet | 2015 | 残差连接 | 训练极深网络 |
DenseNet | 2017 | 密集连接 | 最大化特征重用 |
表1 CNN架构著名神经网络发展史
池化层的首要目的是减少参数数量,也就是减少网格数量:在卷积层之后,特征图的尺寸往往较大,包含大量的参数。池化层通过对特征图进行下采样,能够显著减少特征图的尺寸,从而减少后续层的参数数量。例如,使用最大池化或平均池化操作,将特征图的长和宽缩小为原来的一半,那么参数数量就会减少到原来的四分之一。这样可以有效降低模型的复杂度,减少计算量和内存占用,提高训练和推理的速度。
其次的目的是缓解过拟合,可以看做是某种程度的正则化:过多的参数容易导致模型过拟合,即模型在训练集上表现良好,但在测试集上表现不佳。池化层通过减少参数数量,能够在一定程度上缓解过拟合问题,提高模型的泛化能力。
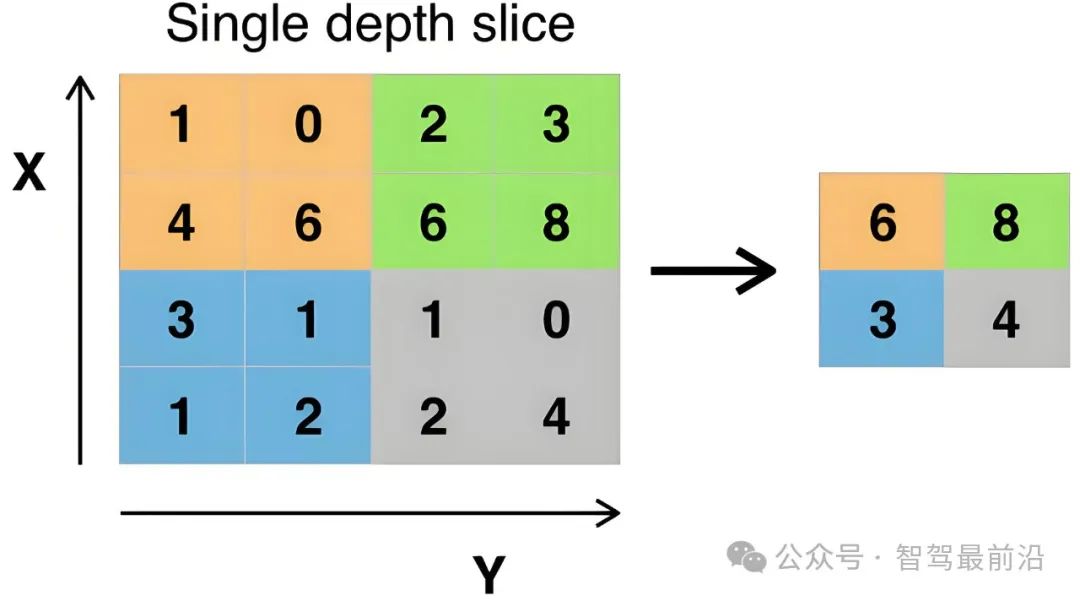
图3最大池化,每一颜色的区域里面所有格子选最大的那一个代表本区域,图片来自网络
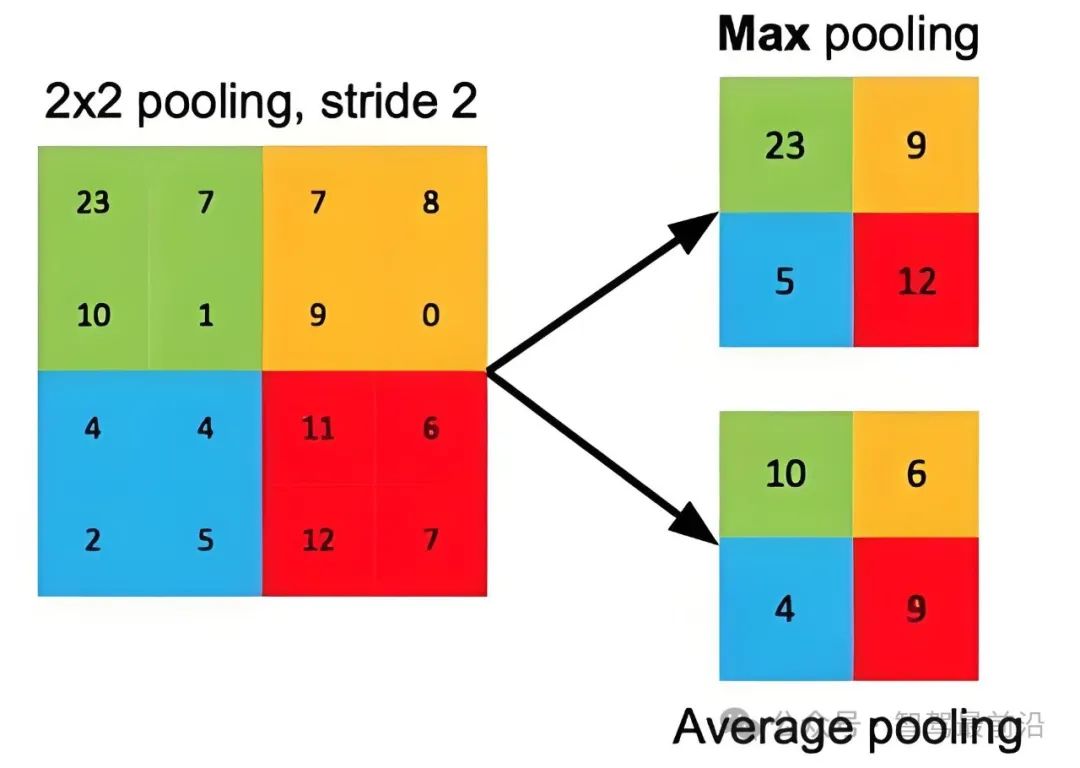
图4平均池化,每个区域取自己所有格子的平均值作为本区域代表值,图片来自网络
直观讲,图片池化的效果是某种程度的模糊化。

图5池化前(左)后(右)效果对比图,图片来自网络
卷积层和全连接层,有明确的连接权重和权重梯度,可以用反向传播算法来根据梯度来更新权重。
不同于卷积层和全连接层,池化层没有明确的连接权重和权重梯度,无法用于反向传播算法。那么在从尾部到头部训练CNN算法时,如何越过池化层?池化层会不会中断整个训练过程?
图
6箭头方向为反向传播训练方向,需要经过池化层实际上,反向传播算法经过池化层时,采取了直接反向赋值的简化方法。
当反向传播经过池化层时,其过程与其他层有所不同,下面针对不同的池化方式(最大池化和平均池化)分别展开说明。
对于最大池化层的反向传播
最大池化在正向传播时,会在每个池化窗口中选取最大值作为输出。在反向传播时,梯度只会传递给正向传播时选取最大值的那个位置,而其他位置的梯度为0。以下是具体步骤:
1.记录最大值位置:在正向传播进行最大池化操作时,要记录每个池化窗口中最大值所在的位置。
2.分配梯度:在反向传播时,对于每个池化窗口,将从下一层传来的梯度分配给正向传播时最大值所在的位置,而其他位置的梯度设为 0。
假设正向传播时最大池化的输入矩阵为:
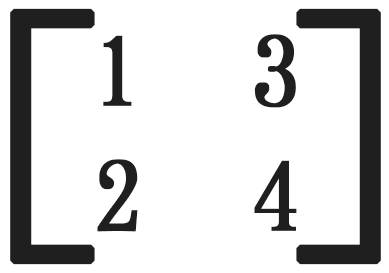
使用2*2的池化窗口,池化结果为 4。若从下一层传来的梯度为 1,那么在反向传播时,梯度分配如下:
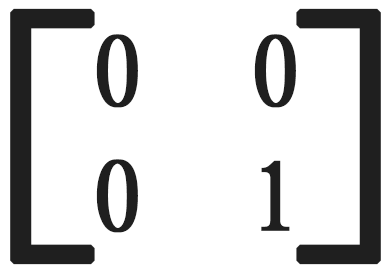
平均池化层的反向传播
平均池化在正向传播时,会计算每个池化窗口内元素的平均值作为输出。在反向传播时,从下一层传来的梯度会平均分配给池化窗口内的所有元素。具体步骤如下:
1.确定池化窗口大小:明确平均池化操作所使用的池化窗口大小。
2.分配梯度:将从下一层传来的梯度平均分配给池化窗口内的所有元素。
假设正向传播时平均池化的输入矩阵为:
使用2*2的池化窗口,池化结果为(1 + 3 + 2 + 4) / 4 = 2.5)。若从下一层传来的梯度为 1,那么在反向传播时,梯度分配如下:

代码示例(Python + NumPy),展示了最大池化和平均池化的反向传播过程:
import numpy as npdef max_pool_backward(dout, cache):"""最大池化层的反向传播:param dout: 从下一层传来的梯度:param cache: 正向传播时记录的最大值位置:return: 本层的梯度"""x, pool_param = cacheN, C, H, W = x.shapepool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']stride = pool_param['stride']dX = np.zeros_like(x)for n in range(N):for c in range(C):for h in range(0, H - pool_height + 1, stride):for w in range(0, W - pool_width + 1, stride):window = x[n, c, h:h + pool_height, w:w + pool_width]max_idx = np.unravel_index(np.argmax(window), window.shape)dX[n, c, h + max_idx[0], w + max_idx[1]] += dout[n, c, h // stride, w // stride] //stride是卷积核的移动步长return dXdef avg_pool_backward(dout, cache):"""平均池化层的反向传播:param dout: 从下一层传来的梯度:param cache: 正向传播时的输入:return: 本层的梯度"""x, pool_param = cacheN, C, H, W = x.shapepool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']stride = pool_param['stride']dX = np.zeros_like(x)for n in range(N):for c in range(C):for h in range(0, H - pool_height + 1, stride):for w in range(0, W - pool_width + 1, stride):window_size = pool_height * pool_widthdX[n, c, h:h + pool_height, w:w + pool_width] += dout[n, c, h // stride, w // stride] / window_size //stride是卷积核的移动步长return dX

归根结底,人工智能和优化算法以及启发式算法一样,是应用数学,而非纯数学。和追求严格证明的纯数学不一样,应用数学允许和欢迎“有效的”人为简化。所谓有效的,是指第一能达成预定功能,第二是在达成功能的前提下,所采取的人为简化足够简单足够自然。
如果在理解和应用人工智能的过程中,采取了纯数学的严格思维,这是一个错误的思考方向。这个错误思考方向,会导致很多概念难于理解和难于想象。
正确的思考方向是,理解人工智能是应用数学,是实验科学,允许各种人为简化,只要这些人为简化在实验中表现出有效性和高效性即可。本文所描述的卷积神经网络中,反向传播算法穿过无梯度的池化层,就是诸多人为简化的例子之一。
-- END --

