




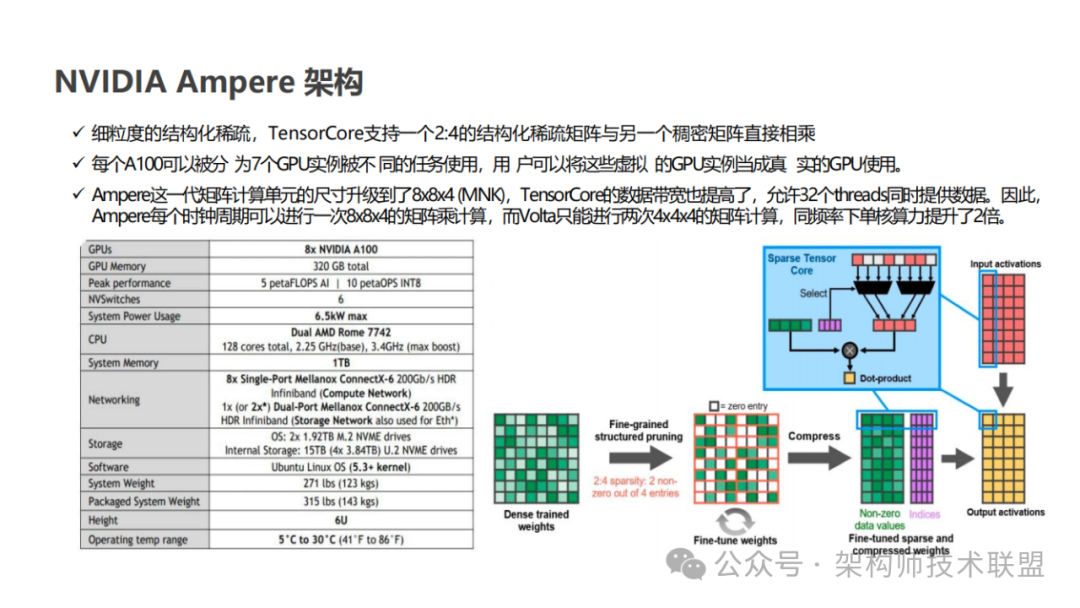
2020 年,Ampere 架构的推出再次刷新了人们对 Tensor Core 的认知。Ampere 架构新增了对 TF32 和 BF16 两种数据格式的支持,这些新的数据格式进一步提高了深度学习训练和推理的效率。同时,Ampere 架构引入了对稀疏矩阵计算的支持,在处理深度学习等现代计算任务时,稀疏矩阵是一种常见的数据类型,其特点是矩阵中包含大量零值元素。传统的计算方法在处理这类数据时往往效率低下,而 Ampere 架构通过专门的稀疏矩阵计算优化,实现了对这类数据的高效处理,从而大幅提升了计算效率并降低了能耗。此外,Ampere 架构还引入了 NVLink 技术,这一技术为 GPU 之间的通信提供了前所未有的高速通道。在深度学习等需要大规模并行计算的任务中,GPU 之间的数据交换往往成为性能瓶颈。而 NVLink 技术通过提供高带宽、低延迟的连接,使得 GPU 之间的数据传输更加高效,从而进一步提升了整个系统的计算性能。

2024 年,英伟达推出了 Blackwell 架构为生成式 AI 带来了显著的飞跃。相较于 H100 GPU,GB200 Superchip 在处理 LLM 推理任务时,性能实现了高达 30 倍的惊人提升,同时在能耗方面也实现了高达 25 倍的优化。其中 GB200 Superchip 能够组合两个 Blackwell GPU,并与英伟达的 Grace 中央处理单元配对,支持 NVLink-C2C 互联。此外,Blackwell 还引入了第二代 Transformer 引擎,增强了对 FP4 和 FP6 精度的兼容性,显著降低了模型运行时的内存占用和带宽需求。此外,还引入了第五代 NVLink 技术,使每个 GPU 的带宽从 900 GB/s 增加到 1800 GB/s。
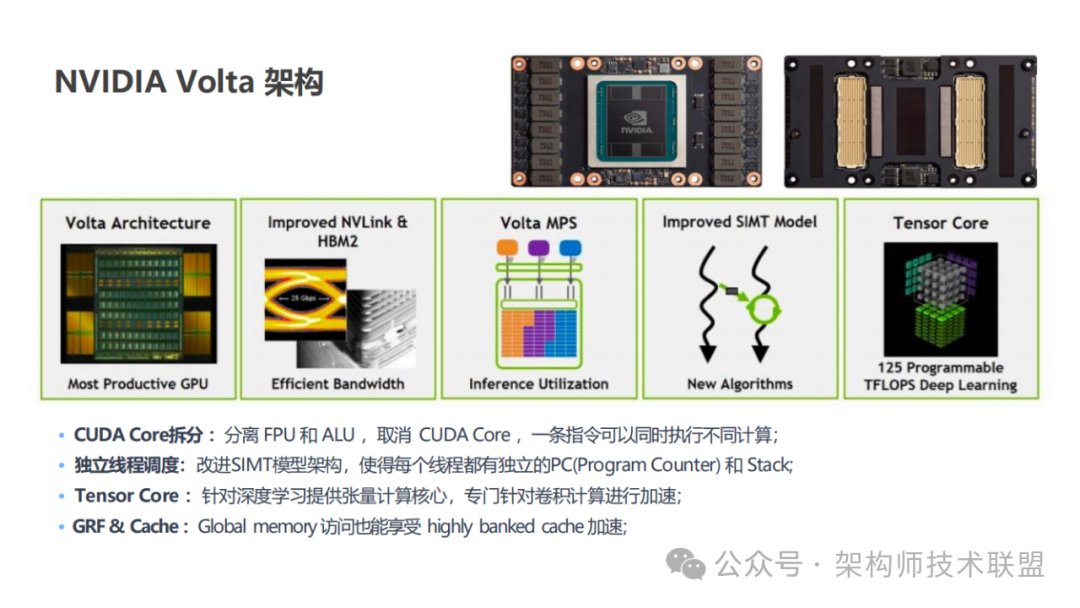
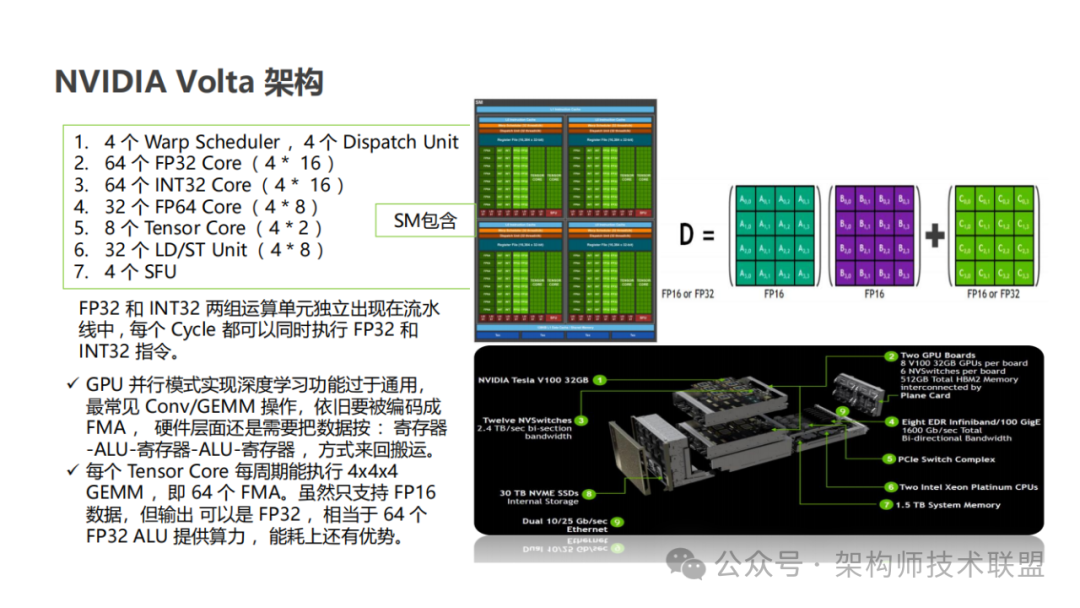
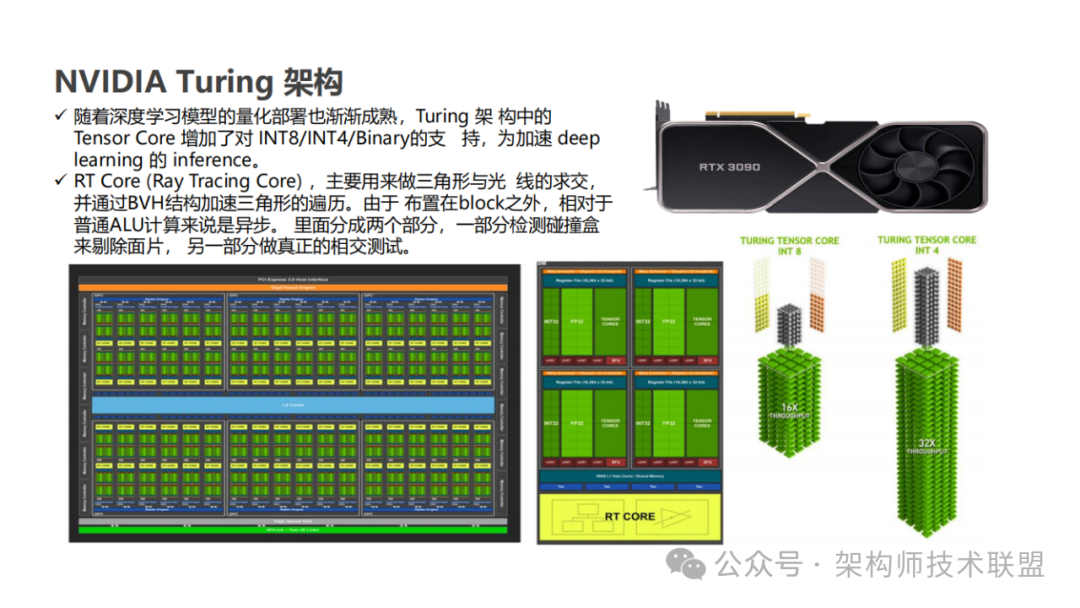

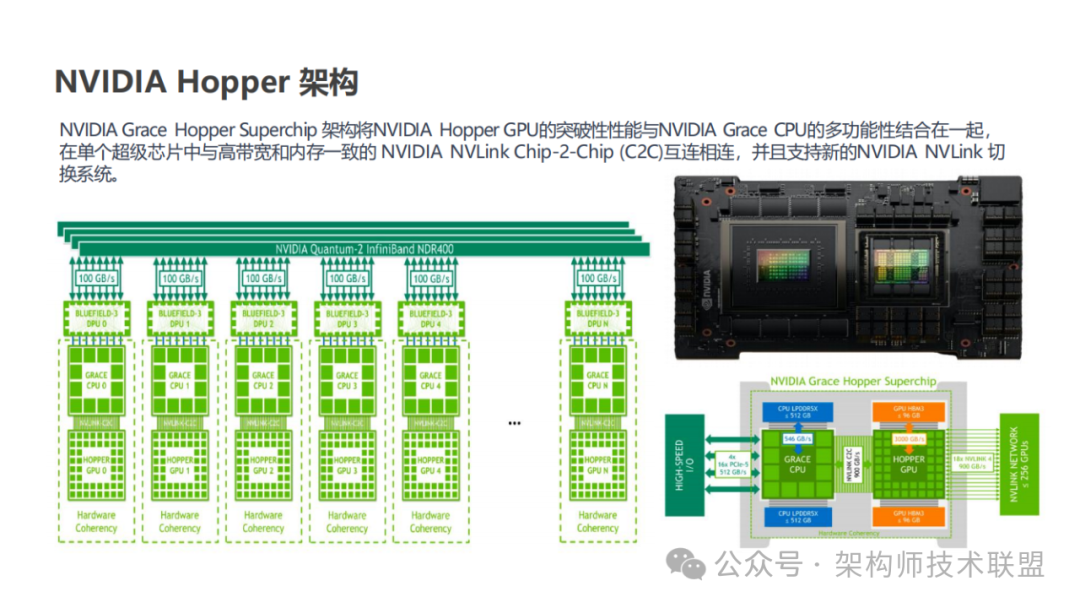
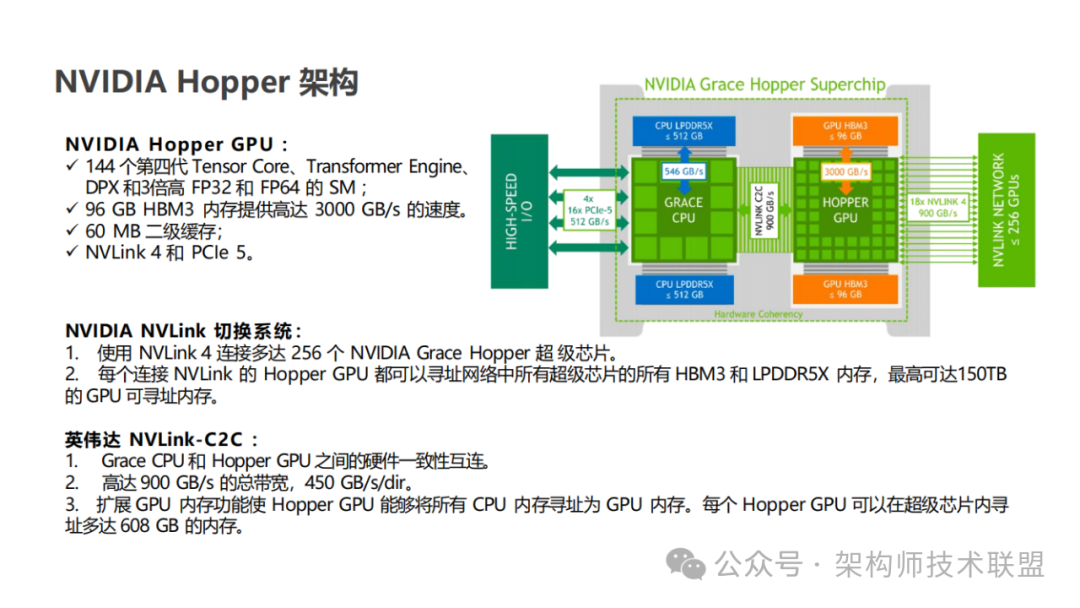
2022 年英伟达提出的 Hopper 架构,这一创新架构中最为引人瞩目的便是第 4 代 Tensor Core 的亮相。
回顾 Tensor Core 的发展历程,前三代的 Tensor Core 均基于 Warp-Level 编程模式运作。尽管在英伟达 A100 架构中引入了软件的异步加载机制,但其核心运算逻辑仍基于 Warp-Level 编程模式进行。简而言之,这一模式要求先将数据从 HBM(全局内存)加载到寄存器中,随后通过 Warp Scheduler 调用 Tensor Core 完成矩阵运算,最终再将运算结果回传至寄存器,以便进行后续的连续运算。然而,这一流程中存在两大显著问题。
首先,数据的搬运与计算过程紧密耦合,这导致线程在加载矩阵数据时不得不独立地获取矩阵地址,简而言之,Tensor Core 准备数据时,Warp 内线程分别加载矩阵数据 Data Tile,每一个线程都会获取独立矩阵块地址;为了隐藏数据加载的延时(全局内存到共享内存,共享内存到寄存器的数据加载),会构建多层级软流水(software pipeline),使用更多的寄存器及存储带宽。这一过程不仅消耗了大量的继承器资源,还极大地占用了存储带宽,进而影响了整体运算效率。
其次,这一模式的可扩展性受到了严重限制。由于多级缓存 Cache 的存储空间限制,单个 Warp 的矩阵计算规格有上限,这直接限制了矩阵计算的规模。在大数据、大模型日益盛行的今天,这种限制无疑成为了制约计算性能进一步提升的瓶颈。
而第 4 代 Tensor Core 的引入,正是为了解决这些问题。英伟达通过全新的设计和优化,它旨在实现数据搬运与计算的解耦,提升存储带宽的利用率,同时增强可扩展性,以应对日益复杂和庞大的计算任务。随着第 4 代 Tensor Core 的广泛应用,计算性迎来新的飞跃。
英伟达在去年的GTC 2024上发布了Blackwell架构,并推出了GB200芯片,今年将这一系列正式命名为Blackwell Ultra。
与此前传言的GB300不同,Blackwell Ultra本质上是Blackwell的内存升级版,基于台积电N4P(5nm)工艺的双芯片架构(Blackwell GPU + GraceCPU),搭配12层堆叠的HBM3e内存,显存容量提升至288 GB,带宽达1.8 TB/s,延续第五代NVLink技术。


从技术角度看,Blackwell Ultra在FP4精度下的算力达到15 petaflops,结合Attention Acceleration机制,其推理性能比Hopper架构的H100提升2.5倍。
Rubin GPU则是英伟达的战略重拳。以天文学家Vera Rubin命名的这款GPU,推理速度将达50 petaflops(比Blackwell的20 petaflops高出一倍多),配备288 GB HBM4内存。


基于Rubin的Vera Rubin NVL144机柜(72颗Grace CPU + 144颗Rubin GPU)将提供3.6 exaflops(FP4推理)和1.2 exaflops(FP8训练)的算力,是Blackwell Ultra NVL72的3.3倍。
到2027年,Rubin Ultra NVL576将进一步提升至15 exaflops(FP4)和5 exaflops(FP8),性能是Blackwell Ultra NVL72的14倍。这些数据表明,英伟达正全力抢占AI计算的制高点。
下载链接:
8、《3+份技术系列基础知识详解(星球版)》
《245+份DeepSeek技术报告合集》
《42篇半导体行业深度报告&图谱(合集)
亚太芯谷科技研究院:2024年AI大算力芯片技术发展与产业趋势
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


