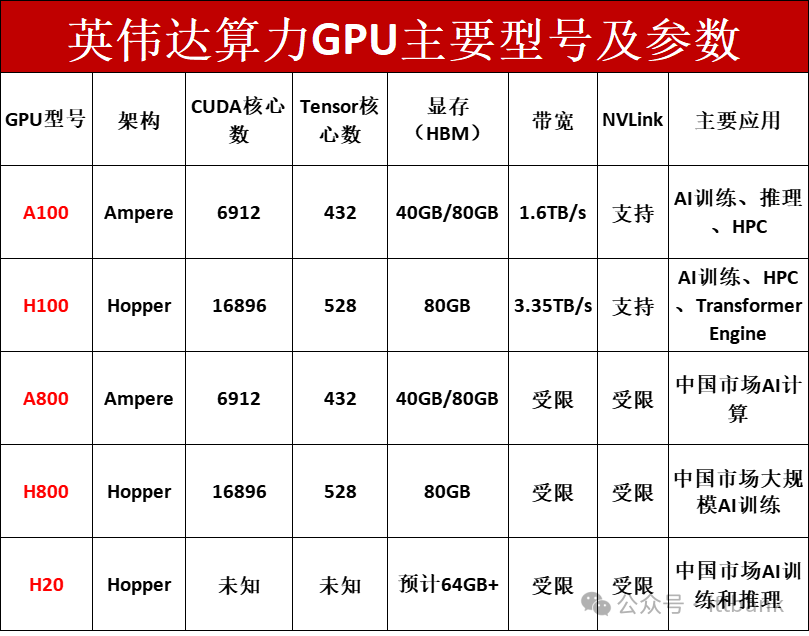
1. A100:数据中心AI计算的奠基石
A100是英伟达2020年发布的旗舰级数据中心GPU,基于Ampere架构,主要特性包括:
- 应用场景:深度学习训练、推理、科学计算、大规模数据分析
A100可广泛应用于高性能计算(HPC)和深度学习任务,适用于需要大量计算资源的企业级用户。
2. H100:性能提升的算力王者
H100是A100的升级版,采用更先进的Hopper架构,相比A100提升了数倍的计算性能,主要特性包括:
- 显存:80GB HBM3(带宽高达3.35TB/s)
- Transformer Engine:专门优化AI大模型训练,如GPT-4
H100特别适用于大型AI模型训练,比如Llama、GPT、Stable Diffusion等,可以大幅提升训练效率。
3. A800 & H800:中国市场专供版
A800和H800是英伟达专为中国市场推出的受限版GPU,以符合美国的出口管制要求:
- A800:基于A100,限制了NVLink互联带宽,适合AI推理和训练
- H800:基于H100,限制了带宽,但仍然保留了较高的计算能力,适用于大型AI训练
这些GPU主要面向中国客户,如阿里云、腾讯云、百度云等云计算厂商,性能稍逊于A100和H100,但仍然具备极高的计算能力。
4. H20:新一代受限算力GPU
H20是英伟达为中国市场设计的新一代受限版H100,预计将取代H800:
H20仍然具备强大的算力,适用于AI训练和推理,但具体性能指标需等待正式发布后确认。
二、如何搭建自己的算力中心?
如果你想搭建自己的算力中心,无论是用于AI训练,还是进行高性能计算,都需要从以下几个方面考虑:
1. 确定算力需求
首先需要明确你的算力需求:
- AI训练:大规模深度学习训练(如GPT、Transformer)推荐H100或H800
- AI推理:推荐A100、A800,推理对带宽要求较低
2. 选择GPU服务器
你可以选择以下方式搭建你的GPU算力中心:
- 选择如 DGX Station A100/H100,单机最多4-8张GPU
- 可使用 DGX A100/H100 服务器,支持多台GPU互联
- 通过InfiniBand和NVLink构建大规模集群
3. 搭配高性能计算环境
- CPU:推荐使用AMD EPYC 或 Intel Xeon 服务器级CPU
- 存储:SSD + 高速NVMe存储(如1PB级别)
- 网络:支持InfiniBand和100GbE以上高速网络
4. 软件环境搭建
- 操作系统:Ubuntu 20.04 / 22.04 LTS,或基于Linux的服务器环境
- 驱动与CUDA:安装最新的NVIDIA驱动,CUDA 11+(H100支持CUDA 12)
如果对数据隐私和持续算力需求较高,建议选择本地搭建GPU集群。
三、训练场景 vs 推理场景
在AI训练(Training)和AI推理(Inference)场景下,不同GPU的性能表现存在明显差异。主要区别体现在计算精度、带宽需求、显存优化以及核心架构等方面。以下是详细对比:
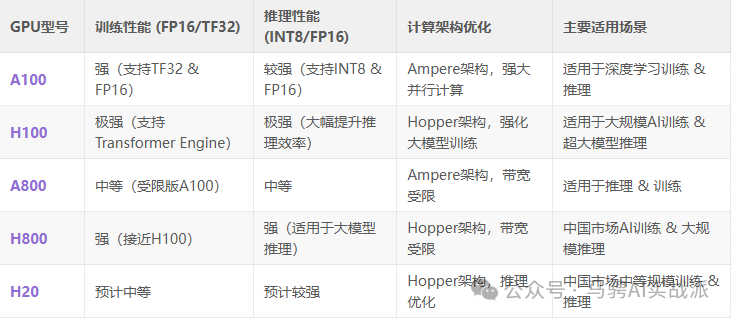
训练 vs. 推理:性能对比
 image
image
训练 vs. 推理:性能解析
1. 计算精度(数值格式)
在AI计算中,不同的数值格式影响计算速度和精度:
- 训练 需要高精度计算(如 FP32、TF32、FP16)
- 推理 需要低精度计算(如 INT8、FP16),以提升计算吞吐量
H100 特别优化了 Transformer Engine,在 FP8/FP16 下可大幅提升 AI 训练和推理性能,适用于 LLM(大语言模型)如 GPT-4。
2. 显存带宽
训练任务 通常需要处理大规模数据,因此高显存带宽至关重要:
- H100(HBM3,3.35TB/s) → 训练速度比 A100 快 2-3 倍
- A100(HBM2e,1.6TB/s) → 适合标准 AI 任务
- H800/A800 由于带宽受限,训练效率比 H100 低
推理任务 一般不需要大带宽,因为:
- 推理更关注 吞吐量(TPS) 和 延迟(Latency)
3. 并行计算 & 计算核心优化
- AI训练 依赖 矩阵计算(Tensor Cores),需要强大的 FP16/TF32 计算能力
- AI推理 需要高效的 INT8/FP16 计算,以提高吞吐量
在计算核心优化上:
| | |
|---|
| A100 | Tensor Core优化,FP16/TF32 训练 | |
| H100 | Transformer Engine | |
| A800 | | |
| H800 | | |
| H20 | | |
H100 在 Transformer-based AI 任务(如 GPT)中比 A100 快 6 倍,而推理吞吐量也更高。
小结
- AI训练: 需要高带宽 + 高精度计算,推荐 H100/A100 及其变种
- AI推理: 需要低延迟 + 高吞吐量,推荐 H100/H800/H20
- H100 在Transformer模型训练 和 推理吞吐量 方面遥遥领先
未来,随着 H20 逐步普及,它可能成为中国市场AI训练和推理的首选。
四、算力中心投资成本估算
根据GPU型号,搭建算力中心的成本会有所不同:
一个基础的4张H100服务器可能需要20万-50万美元,而大型AI训练集群(如64张H100)则可能超过千万美元。
小结:如何选择合适的算力架构?
- 云端还是本地? 云端适合短期任务,本地适合长期需求