


本文参考自“《100+份AI芯片技术修炼合集》”,更多内容请参考“GPU原理详解:Tensor Core原理”,“GPU原理详解:Tensor Core架构演进”,“GPU原理详解:Tensor Core深度剖析”和“GPU原理详解:NVSwitch基础和原理”。
在当今的高性能计算领域,英伟达的 GPU 技术无疑是一颗璀璨的明星。随着 AI 和机器学习技术的飞速发展,对于计算能力的需求日益增长,GPU 之间的互联互通变得尤为重要。在这样的背景下,英伟达推出了 NVLink 协议,以及基于此技术的多 GPU 互联解决方案——NV Switch。
本节将深入探讨 NV Switch 的发展历程、工作原理以及其在构建高性能服务器集群中的关键作用,为读者揭开这一技术背后神秘的面纱。
随着单个 GPU 的计算能力逐渐逼近物理极限,为了满足日益增长的计算需求,多 GPU 协同工作成为必然趋势。
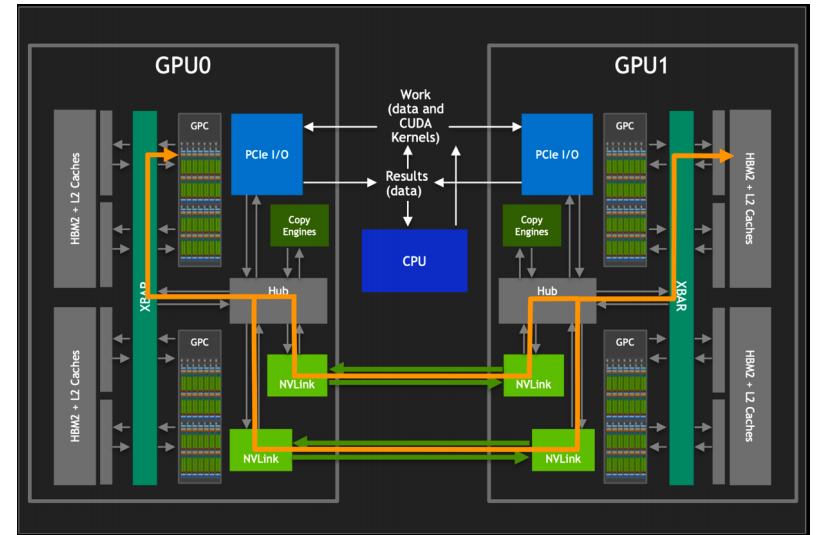
然而,要对其他 GPU 的 HBM2 进行访问,需要经过 PCIe 接口。如上图所示,传统的 PCIe 接口在数据传输速率和带宽上存在限制,这导致 GPU 间的通信通常会成为性能瓶颈。为了克服这一限制,英伟达开发了 NVLink 技术,它提供了比 PCIe 高 10 倍的带宽,允许单个服务器内的 8 个 GPU 通过点对点网络连接在一起,形成所谓的混合立方体网格。
NVLink 技术的核心优势在于它能够绕过传统的 CPU 分配和调度机制,允许 GPU 之间进行直接的数据交换。这种设计不仅减少了数据传输的延迟,还大幅提升了整个系统的吞吐量。此外,通过 NVLink GPCs 可以访问卡间 HBM2 内存数据,也可以对其他 GPU 内的 HBM2 数据进行访问。
在多 GPU 系统中,NVLink 还起到了 XBARs 的作用,它作为不同 GPU 之间的桥梁,允许数据在 GPU 之间自由流动。还巧妙地避开了与 PCIe 总线的冲突,使得 NVLink 和 PCIe 可以作为互补的解决方案共存,共同为系统提供所需的数据传输能力。
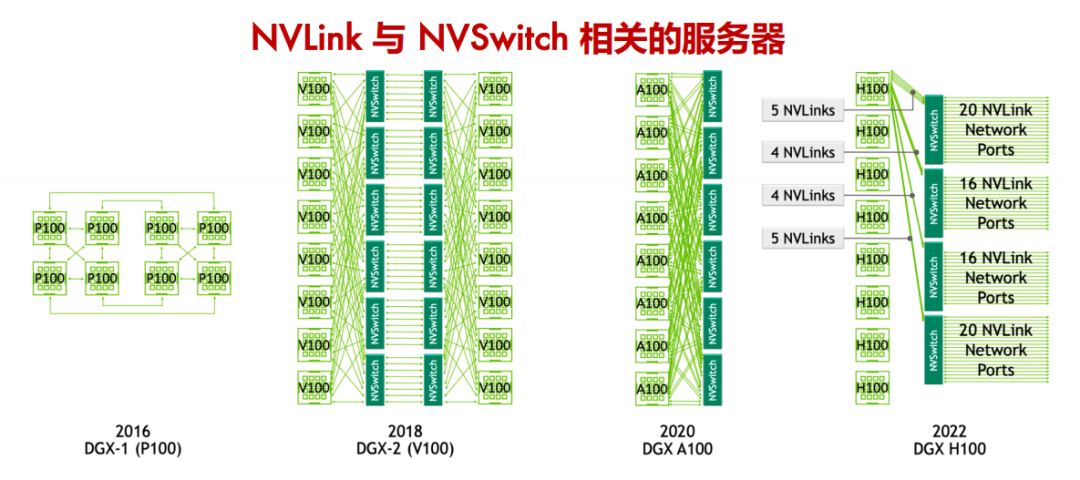
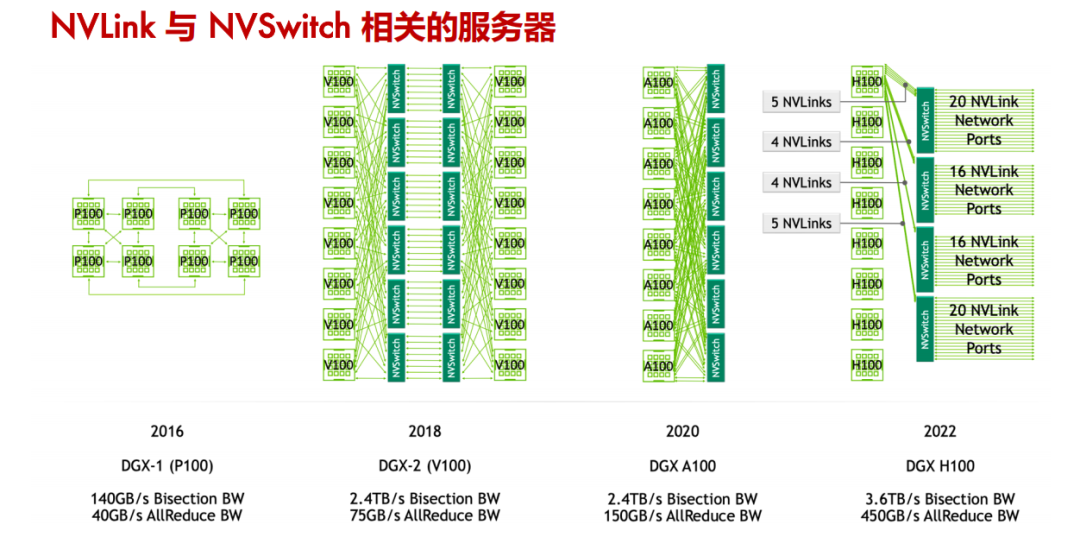
在英伟达的技术演进历程中,Pascal 架构首次引入了 NVLink,这一创新如同开辟了一条高速通道,极大地提升了 GPU 之间的通信效率。然而,真正的技术飞跃发生在下一代的 Volta 架构中,伴随着 NVSwitch 的诞生。
NVSwitch 的出现,犹如在数据传输的网络中架设了一座智能枢纽,它不仅支持更多的 NVLink 链路,还允许多个 GPU 之间实现全互联,极大地优化了数据交换的效率和灵活性。
英伟达的 NVSwitch 技术是实现高效 GPU 间通信的关键组件,特别是在构建高性能计算(HPC)和 AI 加速器系统中。
NVSwitch 的设计引入为英伟达创建一个完全无阻塞的全互联 GPU 系统,这对于需要大规模并行处理的应用至关重要。
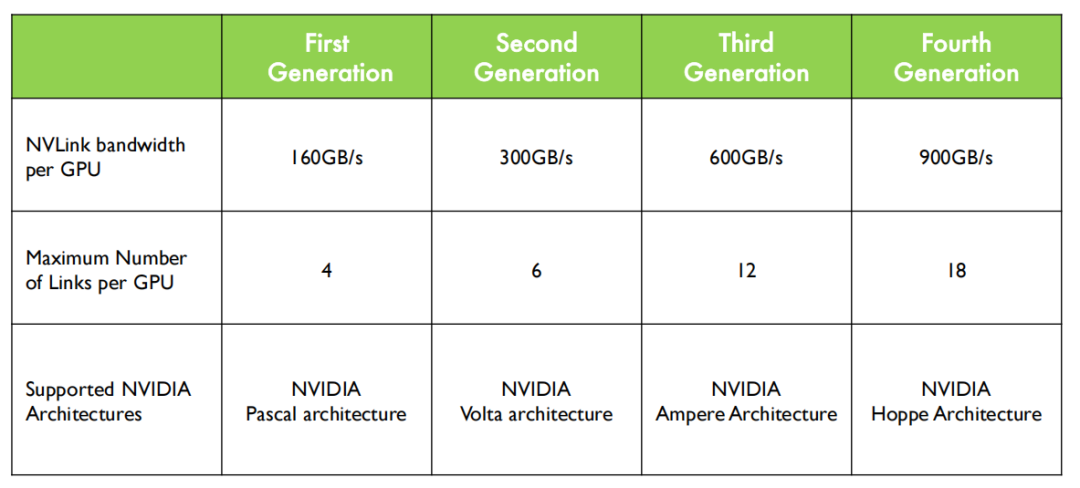
第一代 NVSwitch 支持 18 路接口,NVSwitch 能够支持多达 16 个 GPU 的全互联,实现高效的数据共享和通信。
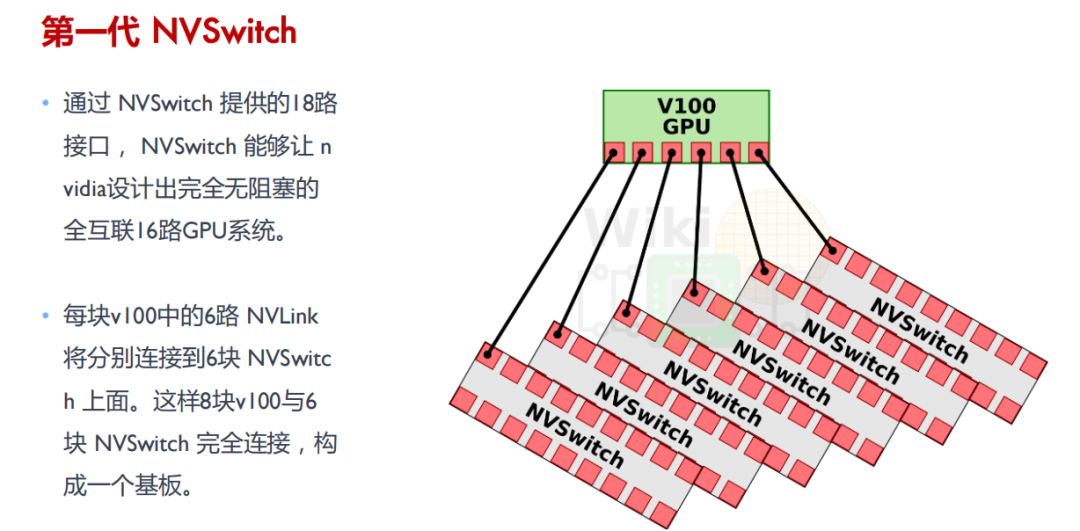
英伟达的 NVSwitch 技术为 GPU 间的通信带来了革命性的改进。NVSwitch 作为一个高速交换机,允许所有链路上的数据进行交互。
在 NVSwitch 架构中,任意一对 GPU 都可以直接互联,且只要不超过六个 NVLink 的总带宽,单个 GPU 的流量就可以实现非阻塞传输。这也就意味着,NVSwitch 支持的全互联架构意味着系统可以轻松扩展,以支持更多的 GPU,而不会牺牲性能。每个 GPU 都能利用 NVLink 提供的高带宽,实现快速的数据交换。
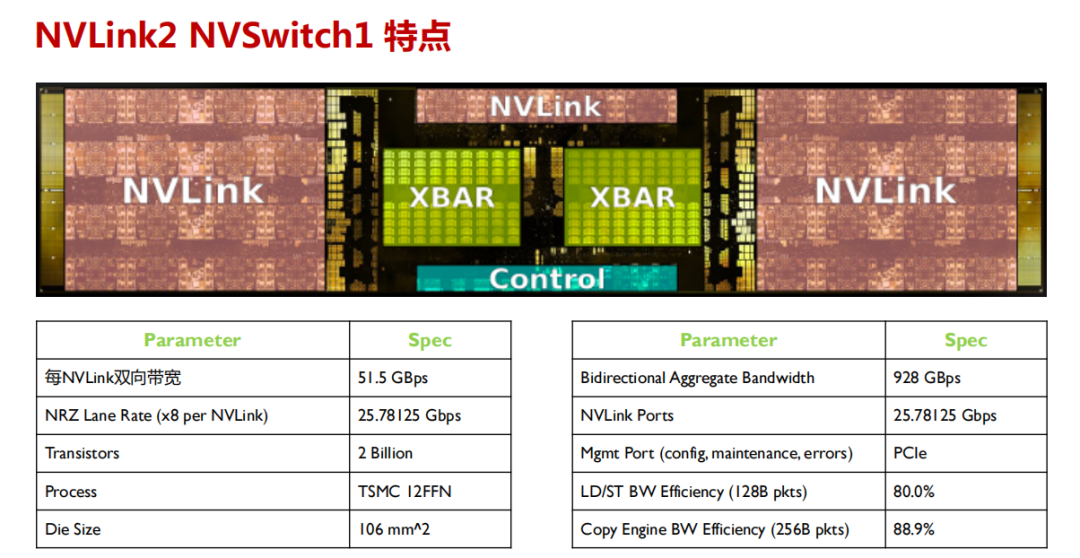
NVSwitch 在解决多 GPU 间的互联有以下优势和特性:
扩展性与可伸缩性:NVSwitch 的引入为 GPU 集群的扩展性提供了强大的支持。通过简单地添加更多的 NVSwitch,系统可以轻松地支持更多的 GPU,从而扩展计算能力。
高效的系统构建:例如,八个 GPU 可以通过三个 NVSwitch 构建成一个高效的互连网络。这种设计允许数据在所有 GPU 链路之间自由交互,最大化了数据流通的灵活性和效率。
全双向带宽利用:在这种配置下,任意一对 GPU 都能够利用完整的 300 GBps 双向带宽进行通信。这意味着每个 GPU 对都能实现高速、低延迟的数据传输,极大地提升了计算任务的处理速度。
无阻塞通信:NVSwitch 中的交叉开关(XBAR)为数据传输提供了从点 A 到点 B 的唯一路径。这种设计确保了通信过程中的无阻塞和无干扰,进一步提升了数据传输的可靠性和系统的整体性能。
优化的网络拓扑:NVSwitch 支持的网络拓扑结构为构建大型 GPU 集群提供了优化的解决方案。它允许系统设计者根据具体的计算需求,灵活地配置 GPU 之间的连接方式。
第三代 NVSwitch 采用了 TSMC 的 4N 工艺制造,即使在拥有大量晶体管和高带宽的情况下,也能保持较低的功耗。它提供了 64 个 NVLink 4 链路端口,允许构建包含大量 GPU 的复杂网络,同时保持每个 GPU 之间的高速通信。同时支持 3.2TB/s 的全双工带宽,显著提升了数据传输速率,使得大规模数据集的并行处理更加高效。
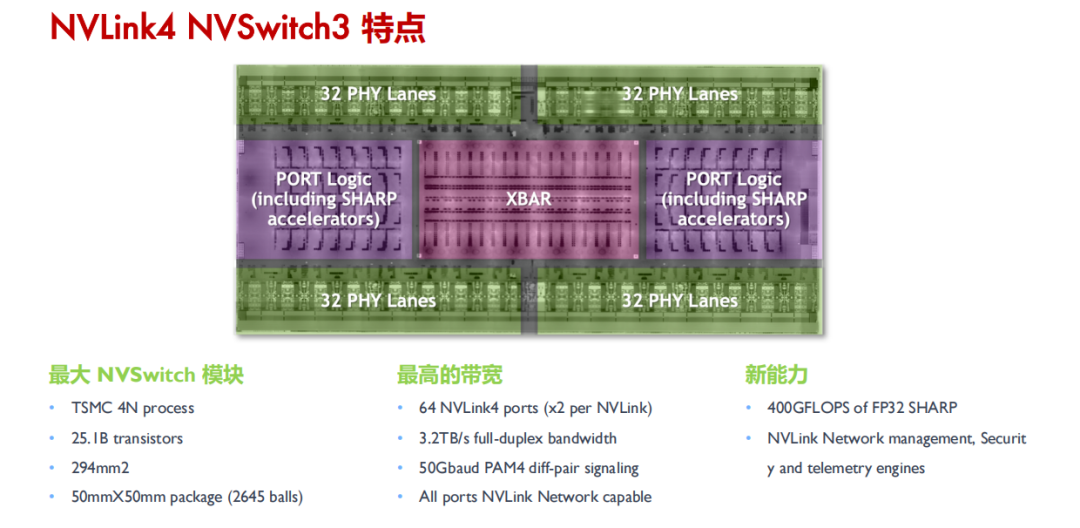
在信号技术方面,采用了 50 Gbaud PAM4 信号技术,每个差分对提供 100 Gbps 的带宽,保持了信号的高速传输和低延迟特性。
NVSwitch 集成了英伟达 SHARP 技术,包括 all_gather、reduce_scatter 和 broadcast atomics 等操作,为集群通信提供了硬件加速,进一步提升了性能。NVSwitch 3.0 的物理电气接口与 400 Gbps 以太网和 InfiniBand 兼容,提供了与现有网络技术的互操作性。
NVSwitch 的关键作用:NVSwitch 技术通过提供高带宽、低延迟的多 GPU 互联,解决了大规模并行计算中的通信瓶颈问题。
NVSwitch 的演进:自 Volta 架构首次引入以来,NVSwitch 技术经历了多代发展,每代都显著提升了 GPU 间的通信能力和系统的整体性能。
NVSwitch 的技术特性:NVSwitch 支持全互联架构,具备高度的系统扩展性和灵活性,同时集成的 SHARP 和 NVLink 模块增强了数据处理能力和安全性,为高性能计算和 AI 应用提供了坚实的基础。
下载链接:
8、《3+份技术系列基础知识详解(星球版)》
《270+份DeepSeek技术报告合集》
《42篇半导体行业深度报告&图谱(合集)
亚太芯谷科技研究院:2024年AI大算力芯片技术发展与产业趋势
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


