

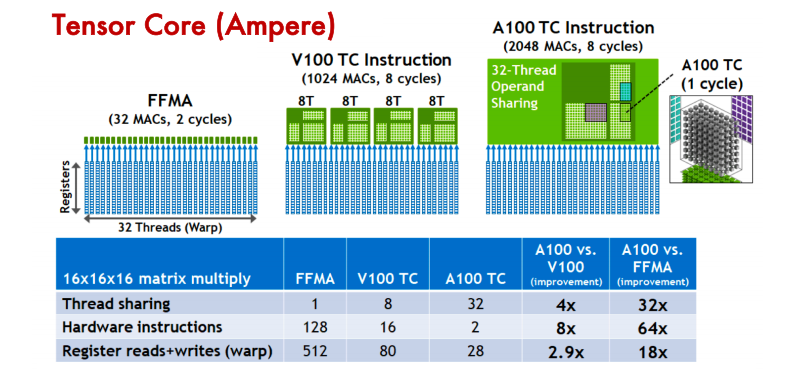

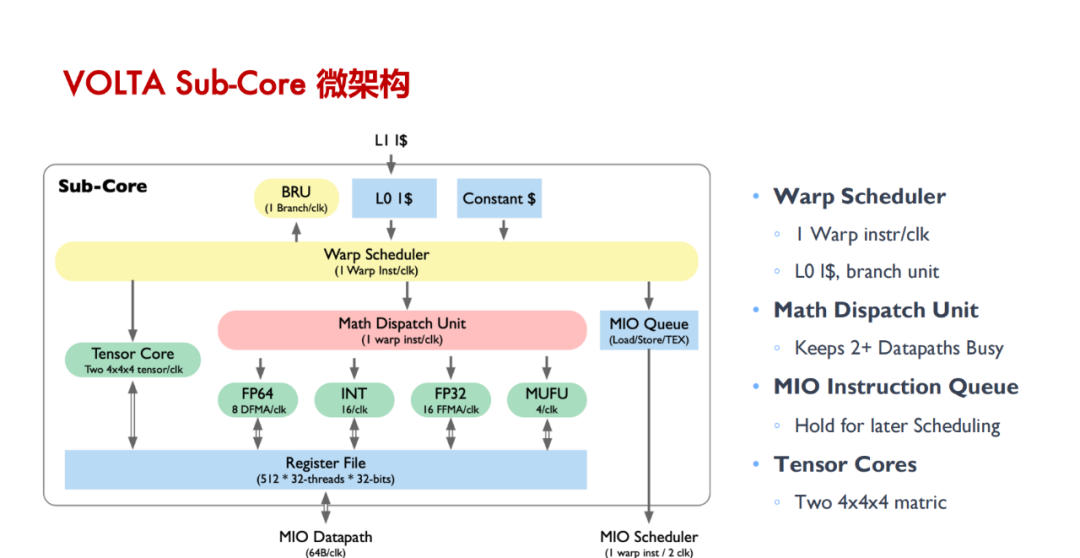
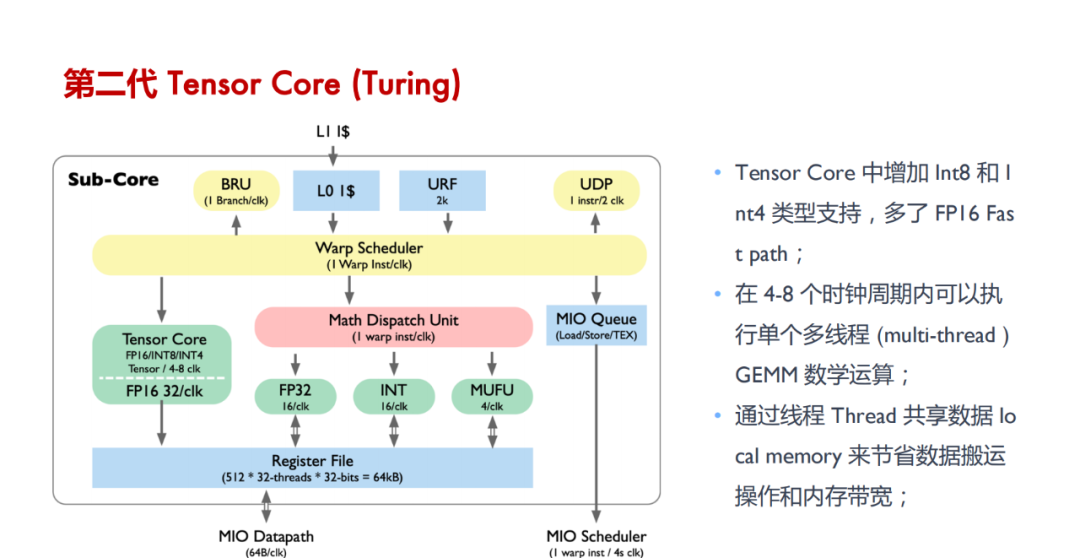
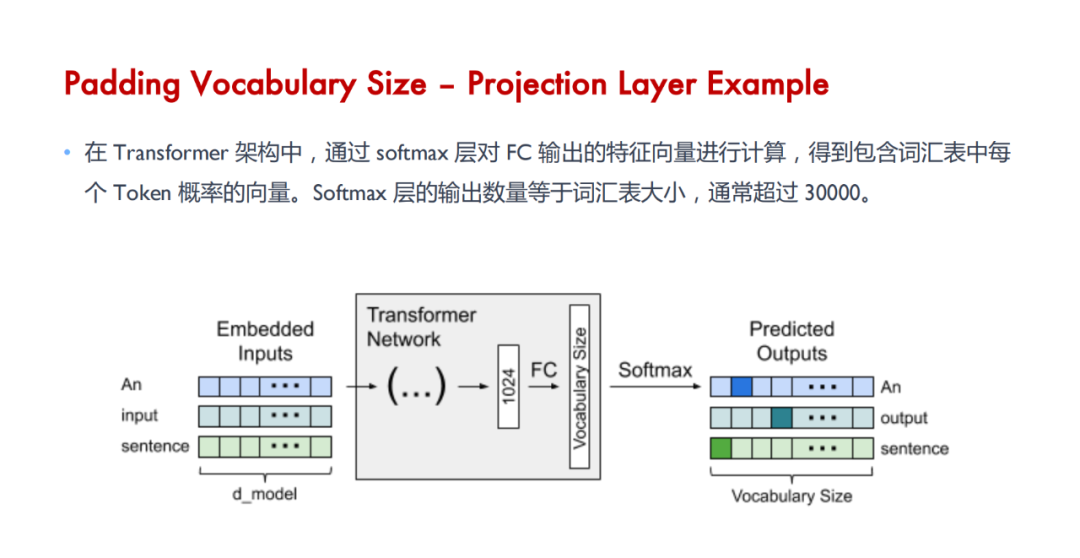
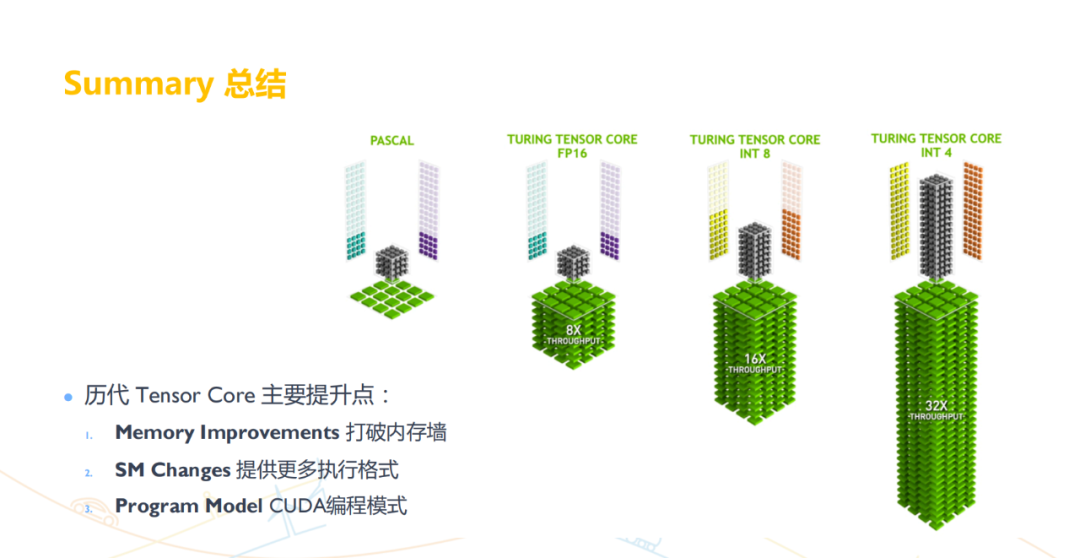
Tensor Core 是用于加速深度学习计算的关键技术,其主要功能是执行神经网络中的矩阵乘法和卷积运算。通过利用混合精度计算和张量核心操作,Tensor Core 能够在较短的时间内完成大量矩阵运算,从而显著加快神经网络模型的训练和推断过程。具体来说,Tensor Core 采用半精度(FP16)作为输入和输出,并利用全精度(FP32)进行存储中间结果计算,以确保计算精度的同时最大限度地提高计算效率。
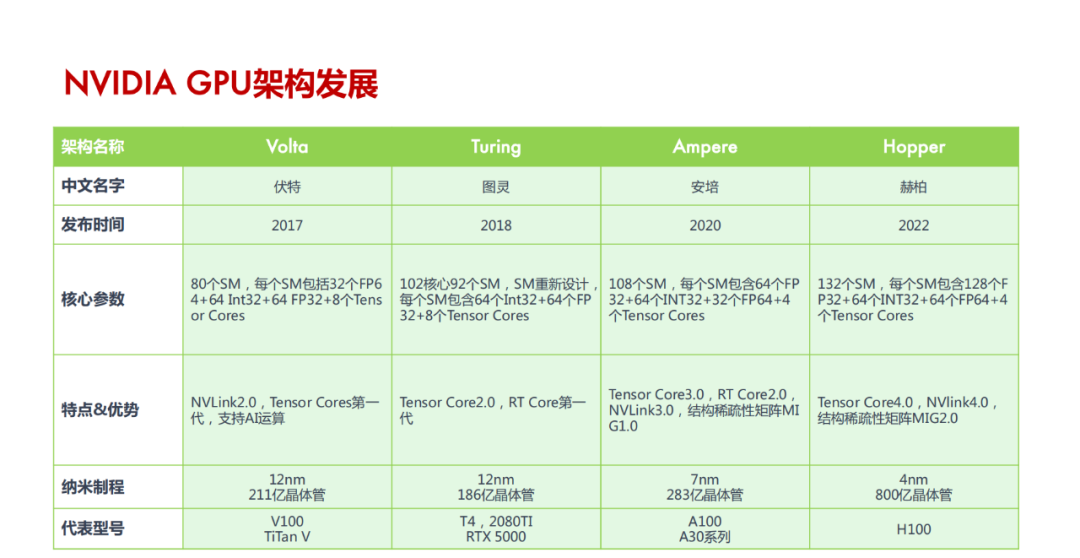
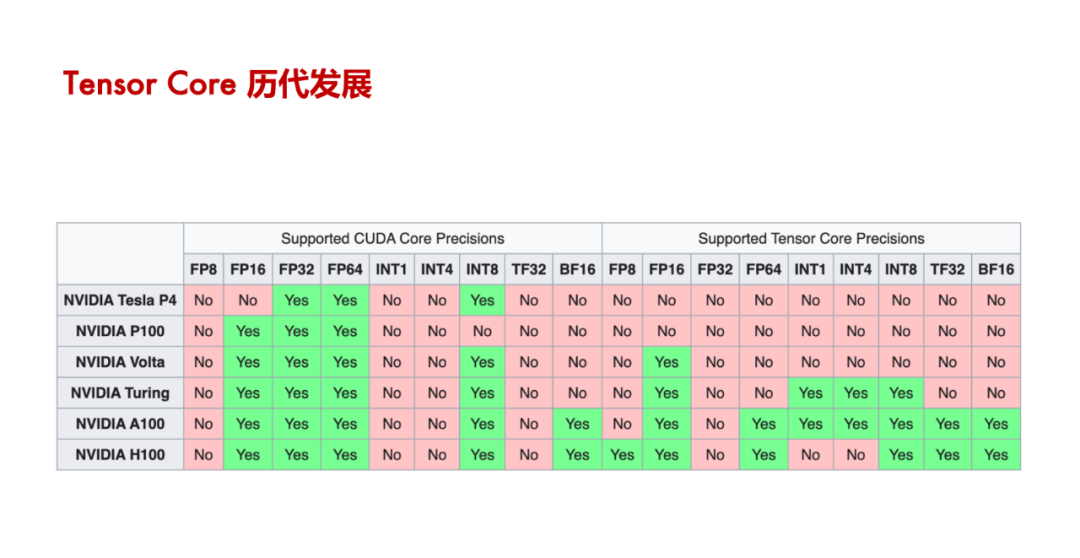
详细内容请参考“GPU原理详解:Tensor Core原理”,“GPU原理详解:Tensor Core架构演进”,“GPU原理详解:Tensor Core深度剖析”和“《100+份AI芯片技术修炼合集》”。
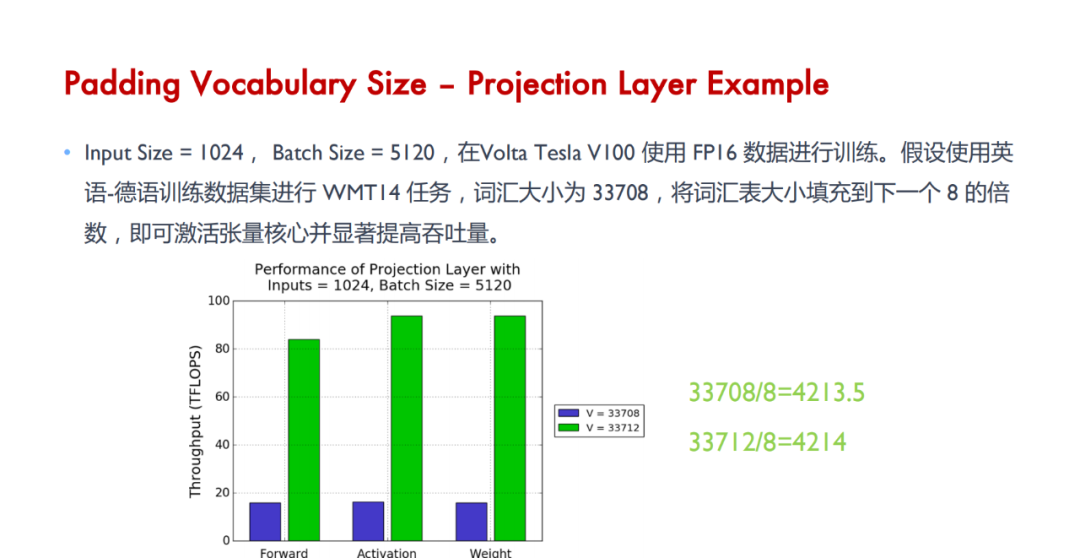
Tensor Core 的计算效率:Tensor Core 通过混合精度计算,利用 FP16 进行矩阵乘法运算并用 FP32 存储中间结果,大幅提高了神经网络模型训练和推断的计算速度。
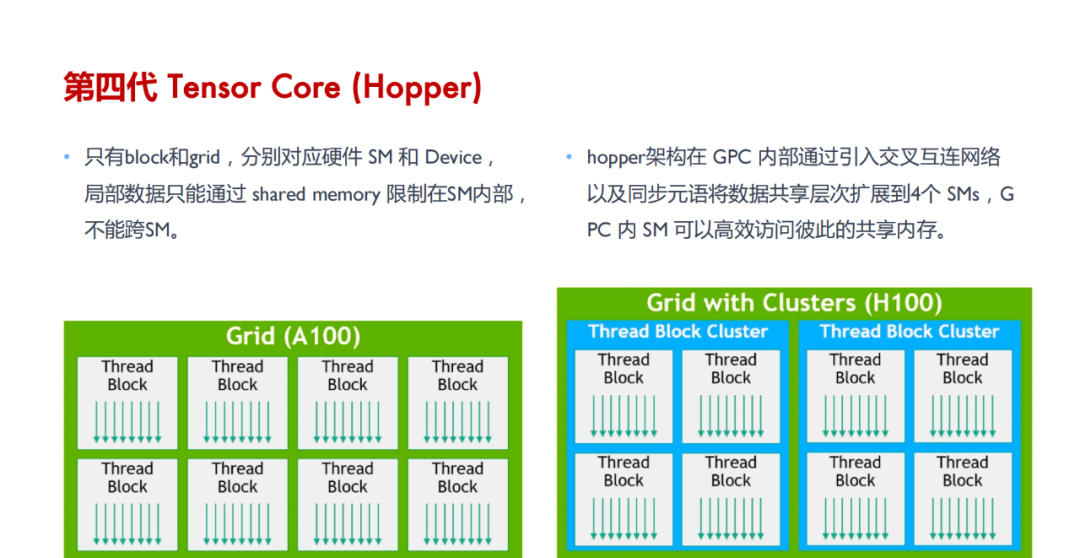
Tensor Core 的并行计算能力:与 CUDA Core 相比,Tensor Core 能在每个时钟周期内执行更多的 GEMM 运算,等效于同时进行 64 个浮点乘法累加(FMA)操作,显著增强了并行处理能力。
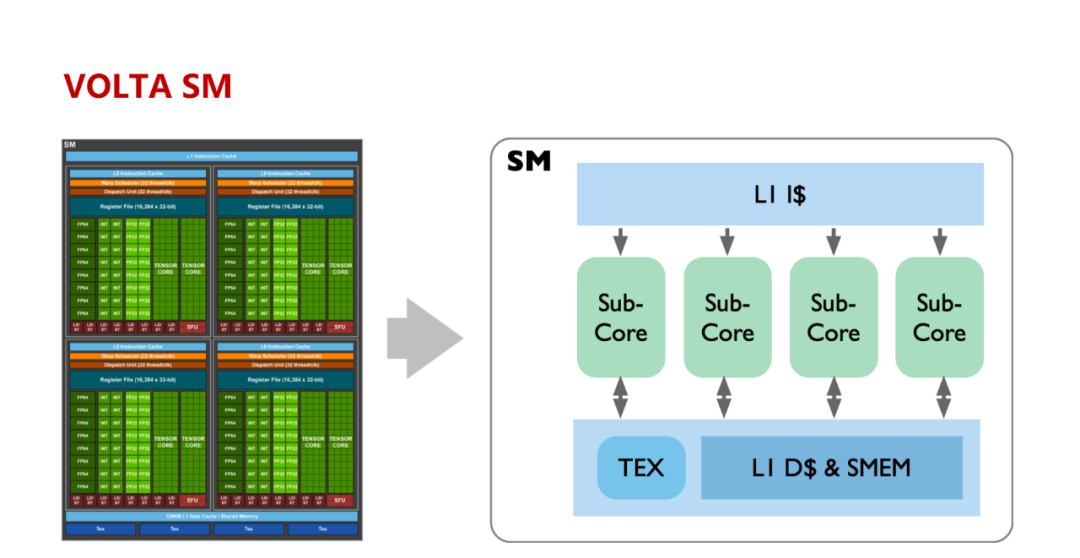
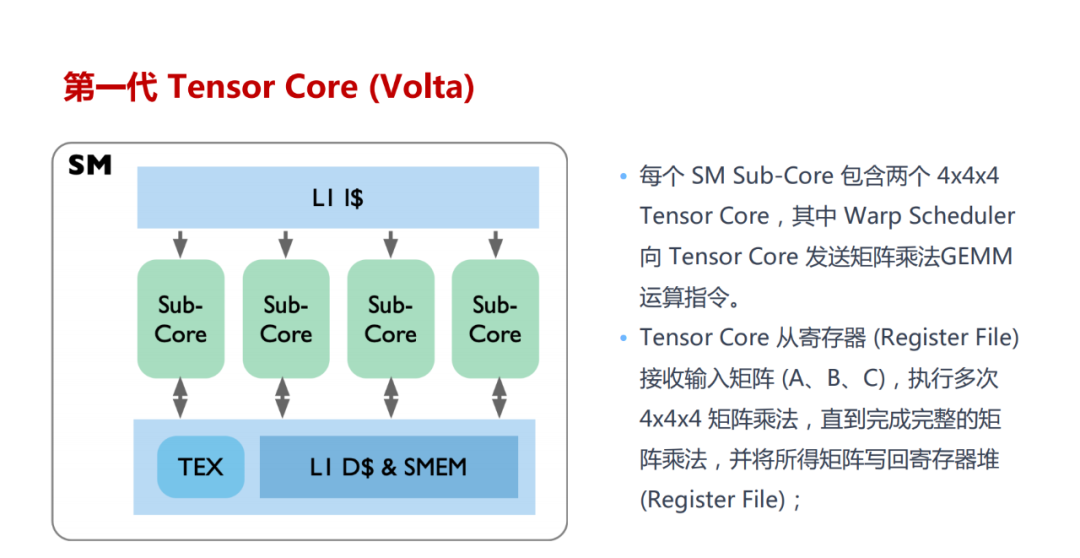
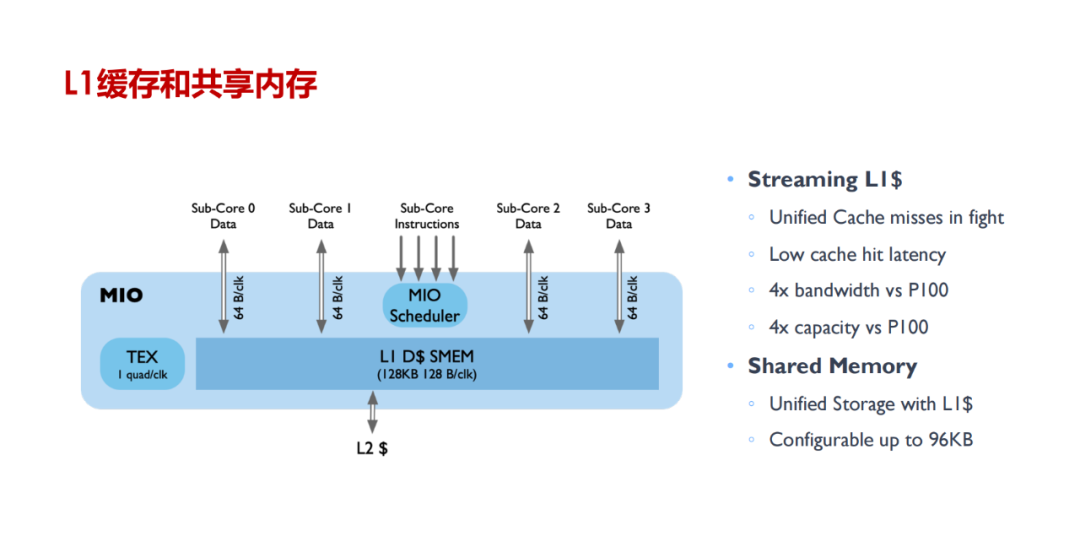
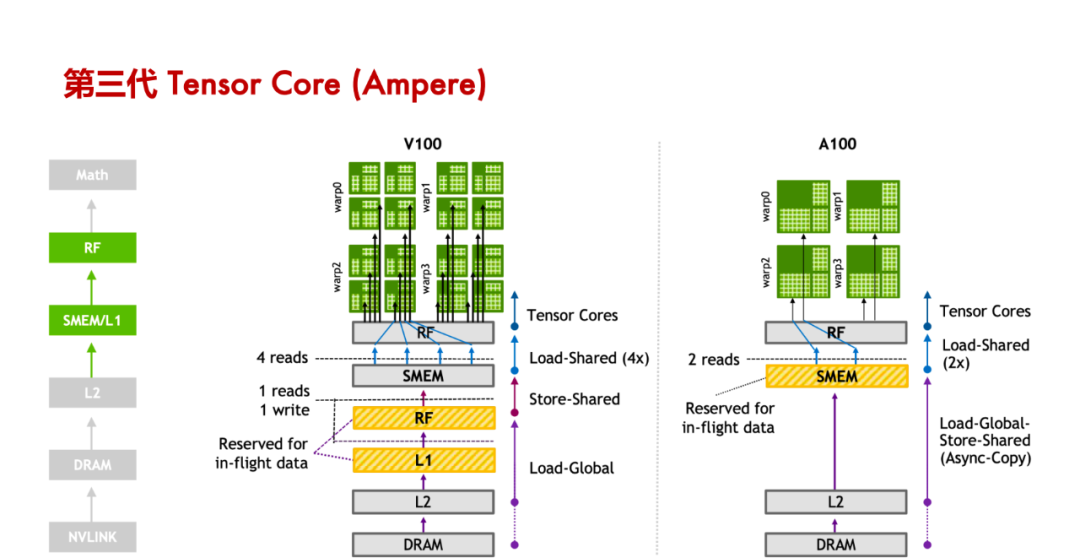
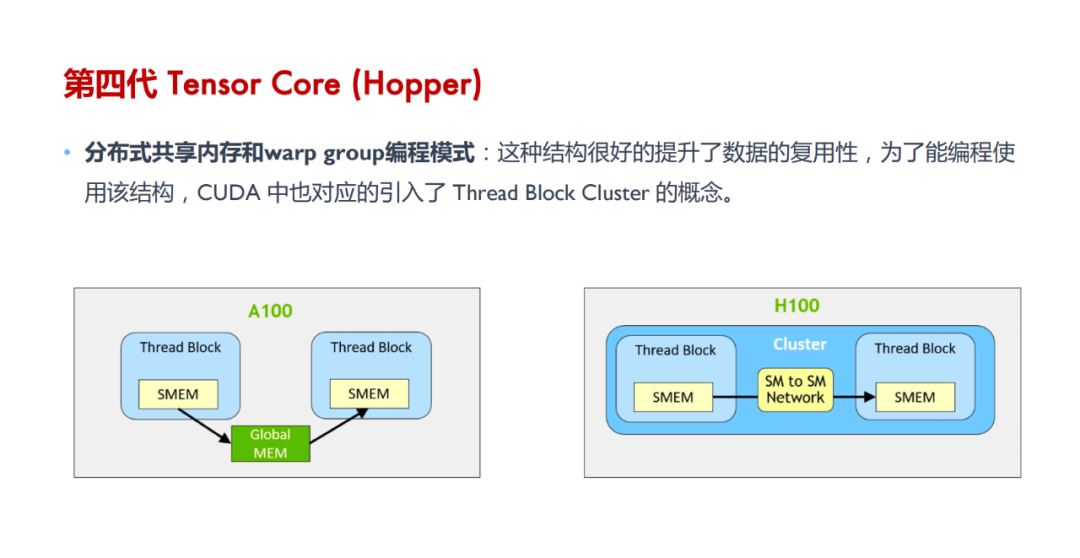
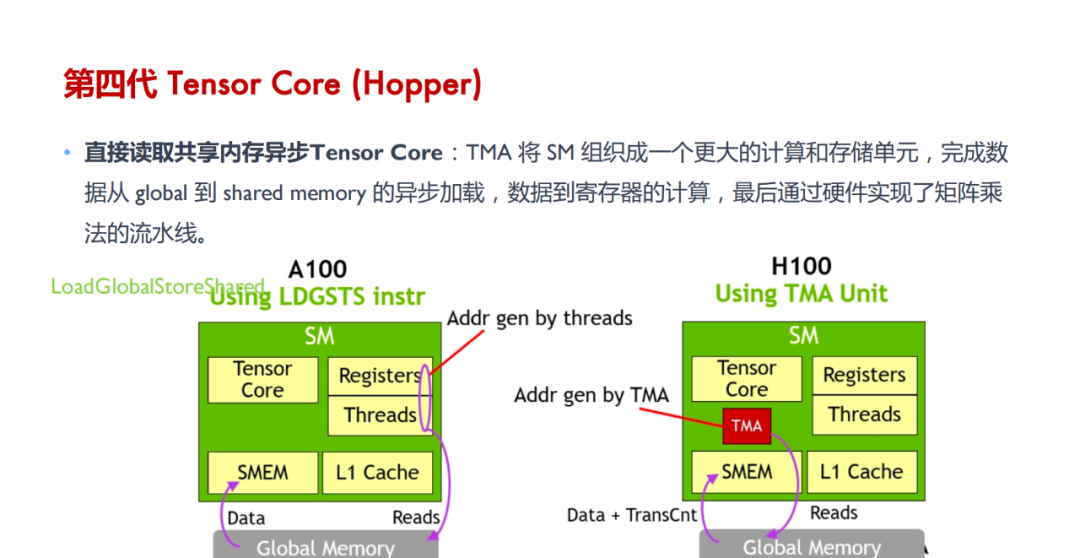
Tensor Core 的计算过程:涉及将大矩阵分块、数据加载到共享内存和寄存器、在 Tensor Core 中进行计算、结果回存到共享内存并最终写回全局内存,整个过程通过 WMMA API 和 CUDA 编程技术实现高效的数据管理和计算。









下载链接:
8、《3+份技术系列基础知识详解(星球版)》
《270+份DeepSeek技术报告合集》
《42篇半导体行业深度报告&图谱(合集)
亚太芯谷科技研究院:2024年AI大算力芯片技术发展与产业趋势
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


