


本文来自“算力芯片系列:GPGPU与ASIC之争”。
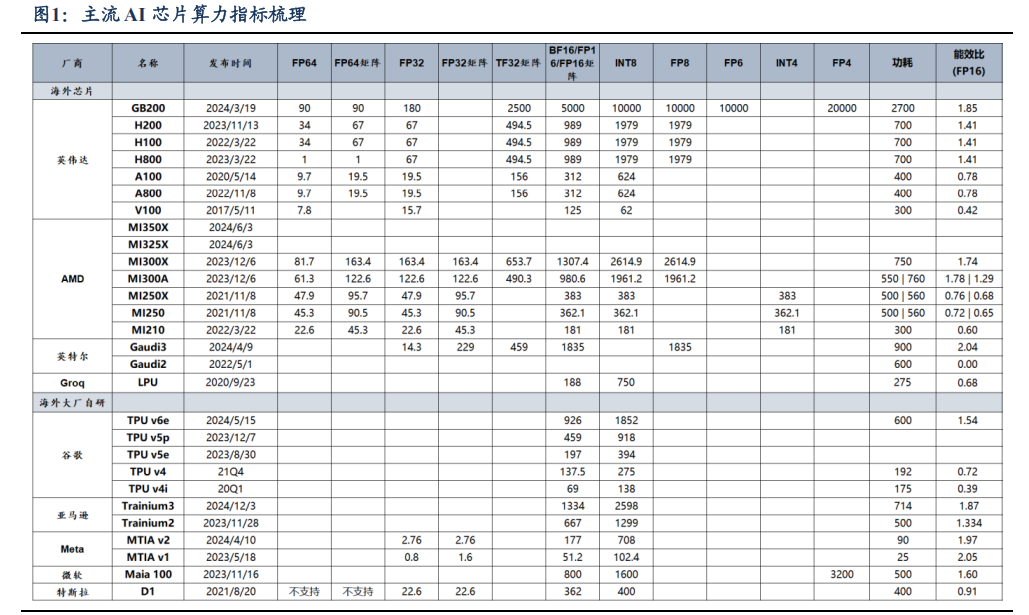
1)算力方面,多数 ASIC 较少涉及高精度浮点数数据,聚焦于低精度领域且拥有相对而言更可观的功耗控制与能效比,但尽管在低精度领域,算力性能部分指标仍难以与同时期的 GPGPU 相媲美。
2)存力方面,ASIC 算力密度高,算数强度迭代快,但在显存带宽和容量上与 GPGPU仍有较大差距,近期表现亮眼的 LPU 则通过超高内存带宽突破性化解传统 GPU 的内存瓶颈。
3)互连方面,英伟达 NVLink 所能实现的 Scale-up 互连能力一骑绝尘,挑战英伟达 NVLink 的难度较大。ASIC 在特定性能上表现突出,但整体来看仍较难超越英伟达的市场地位。
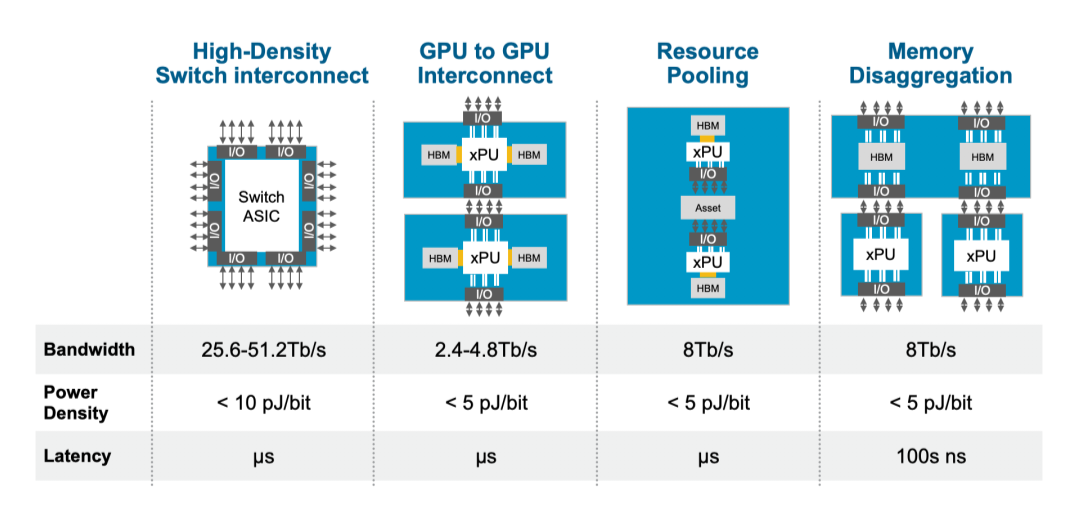
GPGPU 与 ASIC 性能对比一览
算力:精度与能效的差异化竞争
1)从精度范围来看,ASIC 较少涉及高精度浮点数数据,主要聚焦于低精度领域,这与其主要应用于大模型训练的定位相符。大模型训练过程中,低精度数据类型(如INT8、FP16 等)足以满足大部分计算需求,并且能够在一定程度上减少计算量和存储需求,提高训练效率。
2)就低精度部分的算力性能而言,大厂自研的 ASIC 在一些指标上也难以与同时期的 GPGPU 相媲美。以英伟达 GB200 为例,FP16 达 5000,远超同时期 ASIC 数值。
3)在功耗和能效比方面,多数 ASIC 拥有相对而言更可观的功耗控制与能效比。通常,ASIC 由于其定制化的设计,专为特定任务(如大模型训练)优化,在执行特定任务时可能具有相对较低的功耗。
GPGPU 在执行相同任务时,由于其架构需要兼顾多种计算场景,功耗往往较高。例如,微软的 Maia 100 能效比高达 1.60,而同时期的英伟达 H200 为 1.41。但也有例外,如英伟达 A100 的能效比(0.78)高于同期谷歌TPU v4i(0.39),呈现出兼顾普适性与高效性的特点。
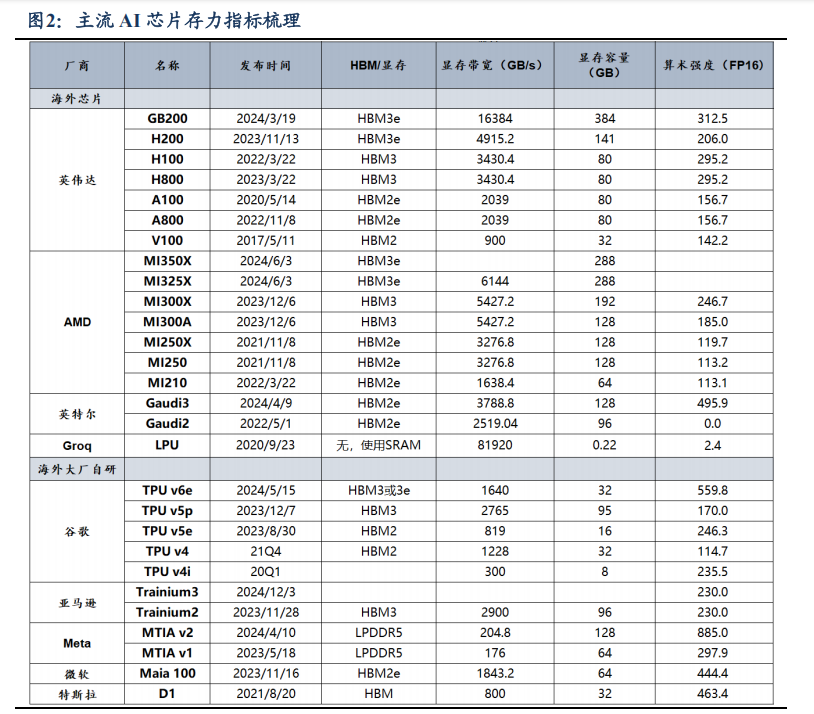
存力:显存性能与算力密度的权衡角逐
1)从显存性能来看,自研 ASIC 在显存带宽和容量上与 GPGPU 仍有较大差距。GB200 依靠 HBM3e 技术拥有高达 16384GB/s 的带宽,这使其在处理大规模数据时能更高效地运行复杂任务。
2)从算力密度(算力/显存容量)来看,GPGPU 单位显存算力相对有限,ASIC 则以高算力密度在特定任务凸显优势。在实际应用中,较高的算力密度意味着在相同的显存资源下,芯片能够完成更多的计算任务。以谷歌 TPU v6e 为例,FP16 算力 1852,显存容量 32GB,算力密度约 57.88,展现出显存利用效率高、存力与算力协同性好的特征。
3)从算术强度(算力/显存带宽)来看,早期 ASIC 弱于同时期 GPU,但技术迭代速度快,22 年后实现反超。至 24 年,ASIC 芯片如 Meta MTIA v2算术强度达 885 FLOPs/Byte,是同期 GB200 算术强度的 2.8 倍。
4)LPU 通过超高内存带宽突破性化解传统 GPU 的内存瓶颈。LPU 采用 230MB SRAM 集成设计,提供 80TB/s的峰值内存带宽。这种存力使每个计算单元可即时获取连续 token 序列,消除传统架构中因频繁访问外部显存产生的时钟周期损耗。该设计架构通过存力创造性释放算力潜能,为大模型推理提供数据供给保障,完成低算术强度任务性能创造性突破。
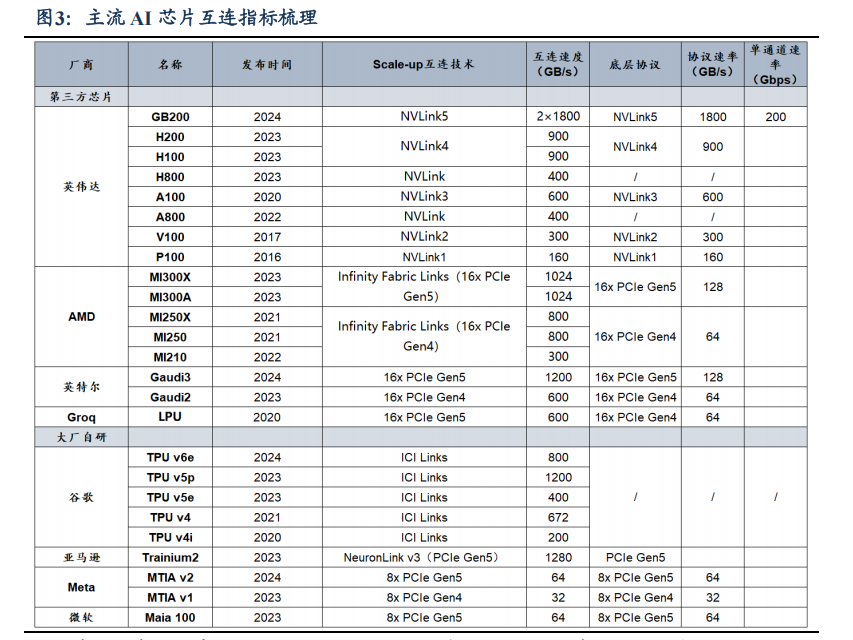
互连:NVLink 主导下的技术挑战与突破
1)单从纸面性能来看,英伟达 NVLink 所能实现的 Scale-up 互连能力一骑绝尘。GB200 所依赖的 NVLink5.0 技术能够实现 1.8TB/s 的互连速度,而其他厂商的 Scale-up互连大多以 PCIe 协议为基础,目前 PCIe5.0 技术单通道双向速率为 8GB/s,16 通道可达 128GB/s,远远低于 NVLink 同代技术。
2)从技术节奏来看,挑战英伟达 NVLink 的难度较大。UALink 初代 V1.0 标准将于 25Q1 发布,NVLink1.0 早在 2016 年已应用于Pascal 架构 GPU。
为什么大厂纷纷开始自研 AI 芯片?
通常来说一个芯片公司的支出有以下四个方面:员工薪资、EDA 和 IP 费用、芯片制造费用、销售费用。以谷歌 TPU 与博通外包服务模式为例,这其中有部分由博通承担,但最终谷歌都需要支付相应的价格,因此我们不做口径调整,依然按 Fabless 公司的研发投入模式来计算。据老石谈芯对哲库造芯团队的研发投入测算,对于一家数字芯片 Fabless 公司而言,员工薪资约占总支出 60%,占掉大部分的比重。
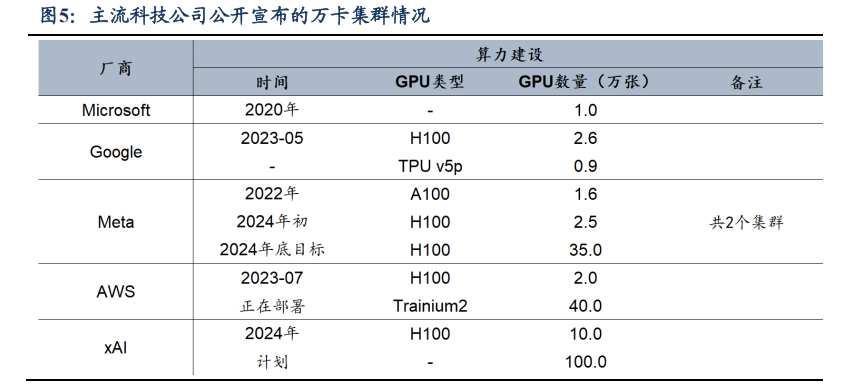
头部大厂的万卡集群建设未曾停歇,完全有望覆盖自研 ASIC 的前期投入。
1)训练端:从训练集群的规模上看,单一集群的需求量已逐渐超过 10 万卡。2023-24H1,各厂商陆续建成万卡集群,其中比较有代表性的是 Meta 于 24/03 月宣布的两个 24k GPU集群(共 49152 个 H100)。24H2 以来市场最为关注的是 xAI 建设的 10 万卡 H100 集群,明年目标或将扩展至 100 万卡。
2)推理端:英伟达 FY2024 数据中心有 40%的收入来自推理业务。随着 AI 应用遍地开花,我们认为 AI 推理需求还有更大渗透空间。
下载链接:
8、《3+份技术系列基础知识详解(星球版)》
《245+份DeepSeek技术报告合集》
《42篇半导体行业深度报告&图谱(合集)
亚太芯谷科技研究院:2024年AI大算力芯片技术发展与产业趋势
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


