https://zhuanlan.zhihu.com/p/310018687211.理想汽车贾鹏在NV GTC上的演讲视频 【如上】
2.理想汽车官方公众号文章:理想汽车发布下一代自动驾驶架构MindVLA
https://mp.weixin.qq.com/s/Q0XBU4fOFHNlAxRqTf48AA
3.理想贾鹏英伟达GTC讲VLA 1228字省流版/完整图文/完整视频
https://mp.weixin.qq.com/s/xrzNNWD_epO-lZUTaMp61A
方案解读
看MindVLA解读之前,建议先看看我总结的近期VLA论文调研 近几年VLA方案调研(截止25.03.14):https://zhuanlan.zhihu.com/p/30182000493
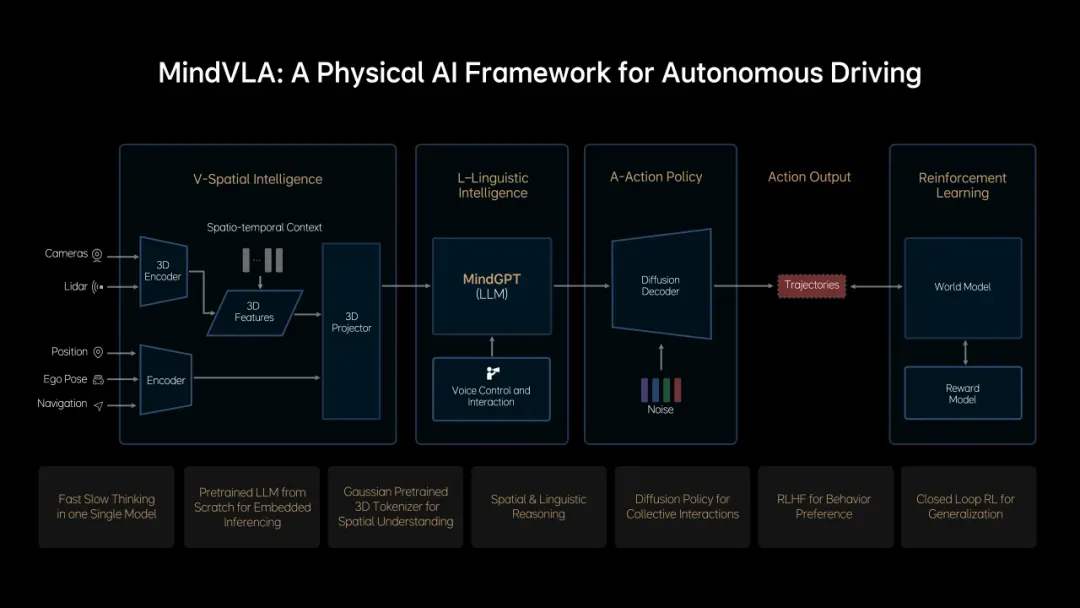
技术点总纲
贾鹏讲到了有六大技术点,听了几遍没听明白他是怎么划分这六大技术点的,就把我听到的技术点都列一下:
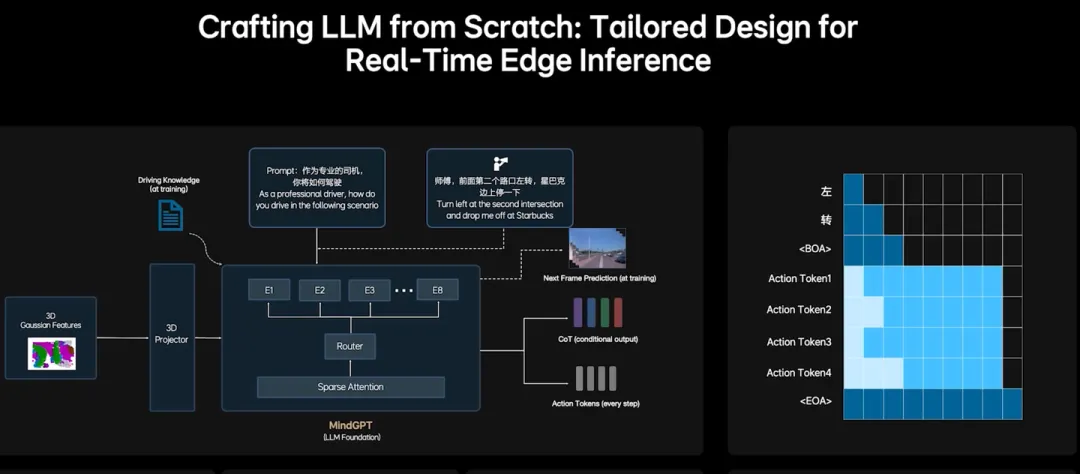
- 利用智驾现成感知网络能力,并添加其他智驾输入,自定义智驾专用的LLM input tokenizer
- 预训练时利用未来帧的预测生成和稠密深度的预测增加3D空间理解和推理能力
MoE
基于Guassian 3D的空间理解中间表达
这块儿是理想之前就发过的文章,我之前也没太细了解,听视频讲主要优势是可以通过视频自监督的训练这个中间表达,然后后边的感知网络都直接基于这个中间表达做,是BEV->Occ->3D Gaussian这么一个升级路线,中间表达越来越精细、3D化,并且Occ真值一般是依赖激光雷达生成的,Guassian 3D纯依赖图像。理想的方案是我调研最近很多方案,遇到的第一个整体重训LLM的,还是很有魄力的 (但也许只是我们比较穷>_<)
自定义智驾专用的LLM input tokenizer
一般来说VLM的实现方式就是基于一个现成的LLM的基础上,加上一些vision encoder再加个mlp把图像转成特殊的输入token,然后加一大堆图像和问题做输入,用回答的文字做监督。因为涉及到新增input token,其训练成本是比较高的。因为改动输入token成本较高(加进去容易,能学到难),一般业界SOTA的VLA方案,对模型改动大的,一般来说也只是在输出层加上特殊的输出Action Token,几乎不会在输入token上做什么改动。(PS: 文章发出后被指证,RoboMM里也添加了输入token,通过一些手段一定程度上降低了增加输入自定义Token的成本)但不在输入token上做改动就会导致VL部分能力容易被pretrained VLM的vision encoder卡住,没有办法充分的利用智驾领域成熟的专业感知网络,这限制了VL部分的效果。为了规避这种问题,在一些论文中提到了在Action中添加额外的网络和额外传感器数据,例如RoboDual,这种方式简单有效,但这会使得VL部分发挥的作用变低,可能VL部分慢慢就退化成了只有人类语音指令意图识别了,想让它发挥3D空间识别推理能力时,即使它给准了下游也未必敢信。因此,我觉得理想这块儿还是比较有决断和魄力的,直接从根本上走了难走但上限高的路子。(不过只是增加input token和完全要从零开始LLM难度还是有差异的,如果理想真的是从零开始,应该还有别的原因,比如后边说的推理效率、增强空间推理能力等)
预训练时利用未来帧的预测生成和稠密深度的预测增加3D空间理解和推理能力
比较容易理解,相当于用视频生成类的方法来监督LLM的训练,用更难但更容易自监督(更容易获得大量数据)的方法来做训练,使其获得基本的能力,用于简单一些的任务上,是很常见有效的手法。
Action Token
Action Token方法和OpenVLA & pi-0比较像,最简单就是用栅格法(分箱法),把动作空间划分成许多栅格,每个格子整成一个token,然后让VLM预测这个token,拿真实的主车、障碍车轨迹算出token来做监督。后边pi-0 fast、OpenVLA-OFT里也都有一些token的优化表达方式,有兴趣的可以再去了解细节。这里边有个重点视频里提了一句,就是Action Token表达的不仅仅是主车的Action,还包括周围的状态车的。这个我在前边调研论文里就说过,在机器人领域里当前一般只关注机器人本身的动作,对动态障碍物要求还没那么高,而智驾领域里,障碍车的响应编码进去是很必要的,可以参考MotionLM里的编码方法来完成主车和障碍车的统一编码。
CoT
用可配置开启的思维链,用来提升规划效果。这块具体细节我不太熟悉。
MoE
DeepSeek R1之后基本标配了,不多说
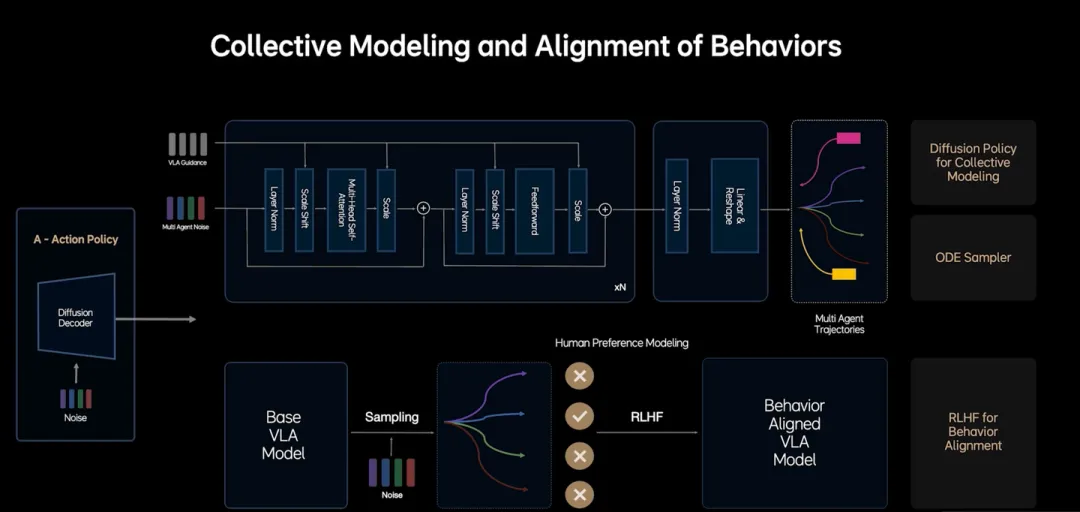
diffusion model生成精细化动作
VLM出的Action Token已经可以直接反向推出一个主车和障碍车预测轨迹了,但缺点是Action Token分栅格时会有精度损失。diffusion model可以把Action Token转化生成更精细的动作,这块儿基本上也是业界通用手法。
RLHF微调采样过程,对齐行为生成
但我这块儿没有太懂,行为决策为啥不是在VL部分搞好,而是要在Action模型里做。我觉得VL部分有点像智驾里的BP,而Action部分类似于MP,粗轨迹里就应该包含好决策信息,如果让Action搞这种决策的话VL部分的职责就很不清晰,很容易最后所有问题都要靠Action模型。我觉得可能是当前阶段VL还不能很好做好决策,把压力都压到了Action层导致的。
这也是理想这个方案一大革新,虽然都是工程上的东西,但意义重大。它可能是第一次实现了同一个VLA模型在车端高频(10hz+)执行,完全满足了智驾的耗时需求。OpenVLA-OFT本身做了许多优化之后,最后做到了一次推理0.321s,然后利用Action Chunking均摊之后说可以做到77hz,但实际上Action Chunking均摊并不会增加感知信息更新频率,实际上真正的频率还是按3hz左右算更合理。而pi-0 & RoboDual之类的多数文章都是绕开了提升VL执行性能这条路,让VL和A分开执行,VL低频运行,Action高频运行。一般来说也够用,但确实也会导致Action有时要有能力忽略掉VL的提示(因为可能会有更新的输入)。而理想这块儿则是直接想办法搞定VL高频执行这个难题。
Sparse Attention
Action Token采用并行解码
CoT采用小词表和投机推理
常微分方程的ode采样器
这个也没太多要说的,FlowMatching常见手法。仿真器里强化学习这块儿我不很看好,没看到怎么解决Smart Agent和Planner模型鸡生蛋蛋生鸡问题,暂不多说。
应用场景
本文重心主要讲的技术点,对于应用层,直接贴一下原视频里的图,不多解释:

最后闲聊下
VLA能带来什么?
语言、图像多模态指令理解和交互能力。
首先是与用户的交互能力可以显著提升,比如,『请帮我在电梯口附近找一个相对比较空的车位停下来』这类复杂的指令的理解和执行。也可以对用户输出一些智驾行为解释,提升用户安心感。
除了与用户的交互外,VLA也可以提升一些泛语言的标识等世界指示信息的理解,简单来说就比如公交车道、限时车道、交警指示、路边一些特殊文字指标、商店标牌的理解,以及理解之后的推理能力,如地库里根据各种标识来推测用户目的地在哪儿,该往哪里走。
此外,VLA还可以提升与外界的交互能力。将来可能打灯之类的也都可以直接VLA出、甚至未来哪天可能车可以直接和旁车或行人说话。叠加上座舱相关的大模型,最终目标就是车就是一个出行的智能助理。
世界常识与基于常识的推理能力
塑料袋、棉花团能不能压?如果必须要撞了,怎么撞更安全些?这些问题很可能用端到端也是无法解决的,因为端到端训练不太可能拿一堆撞了的数据来做训练怎么撞安全些。但人类是可以基于常识推理出来的。还有一些道路上少见的特殊状况的未来状态预测,也可能需要依据常识来进行推理。
对于机器人领域,目前主要关注的是泛化指令理解。但我觉得未来机器人VLA会有一个比较有意思的爆发点:
训练时,迁移学习,用人类的动作来训练,学习动作,最后拿机器人微调。
然后最后实现One Shot Imitation Learning,即人类示范一遍之后,VLA拆解理解人类动作,让机器人实时的学会新的技能。比如,人类告诉机器人,『我在示范拿起书籍』,机器人学会了『拿起』『书籍』这两个概念,然后人类指令是『拿笔放到书上』时,机器人可以拿刚学到的概念增强新指令的执行效果。
可惜这个似乎在智驾领域意义没那么大。
声明:本文基于公开资料分析,不涉及理想汽车未公开技术细节。