昨晚,DeepSeek-V3悄然升级!

从发布时间和技术特点来看,DeepSeek-V3-0324,很可能是DeepSeek-R2的基础架构。
所以按照DeepSeek一贯的产品发布节奏(先推出基础模型,几周后再发布专门的推理增强版)来看,DeepSeek-R2很可能在几周后就将上线!
升级后的V3在代码、数学推理能力上,得到显著提升。尤其是代码领域,不少网友直呼「眼前一亮」。
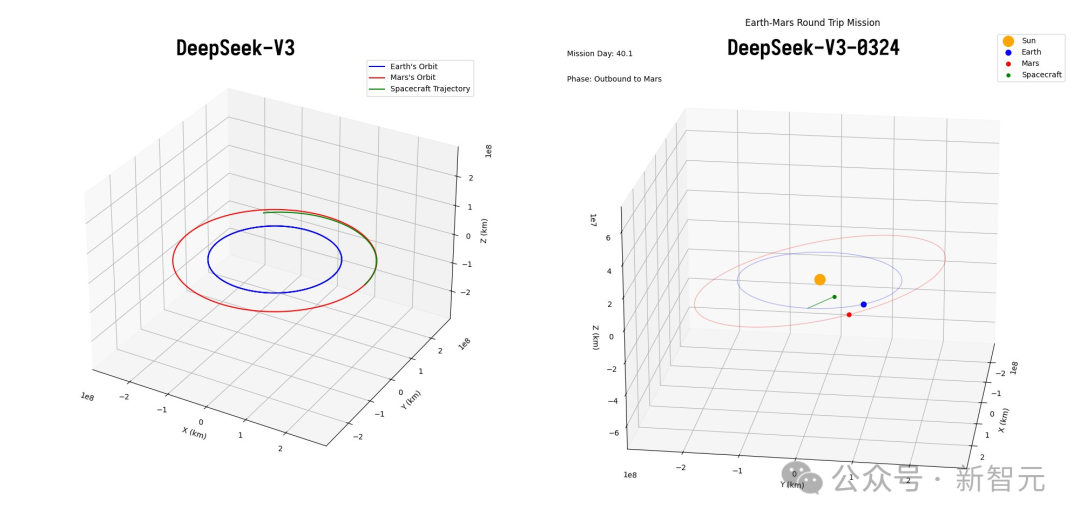
相较于上一版,从一个球在超立方体弹跳的Python脚本,即可看出V3代码性能的改善。
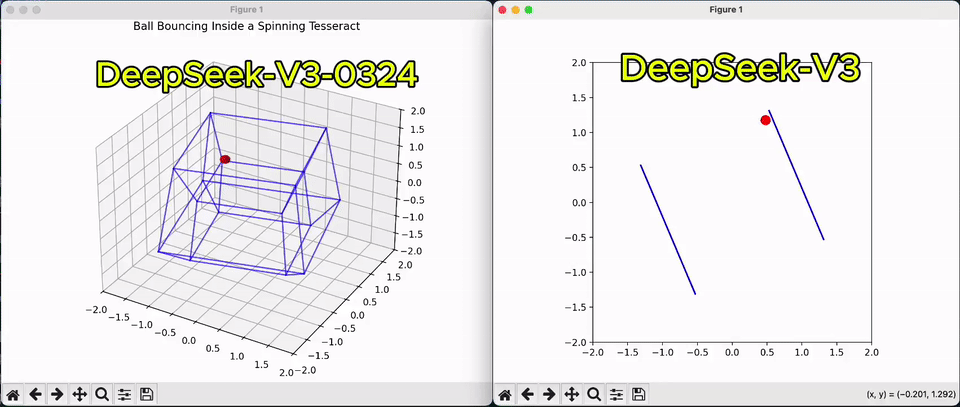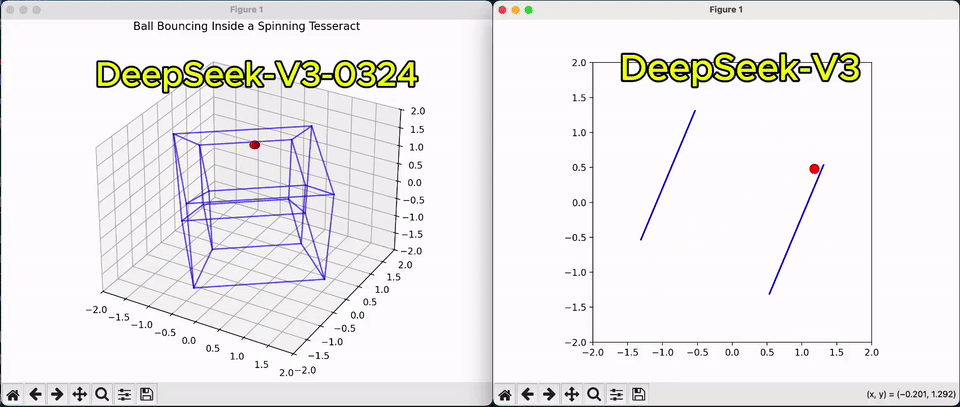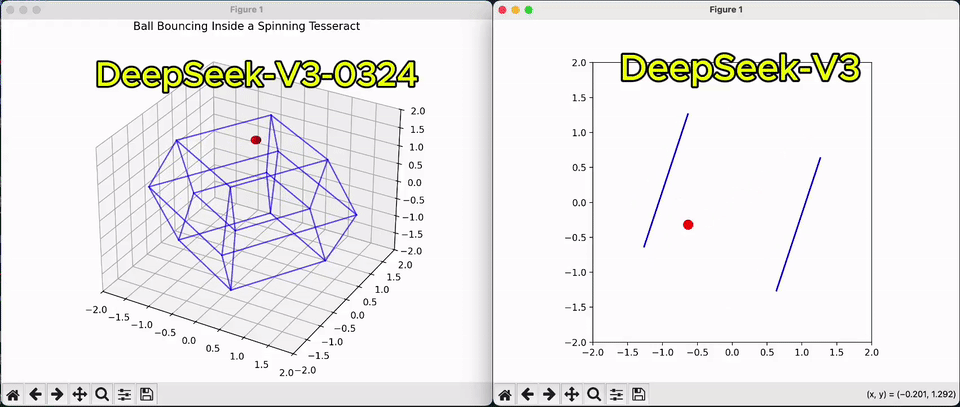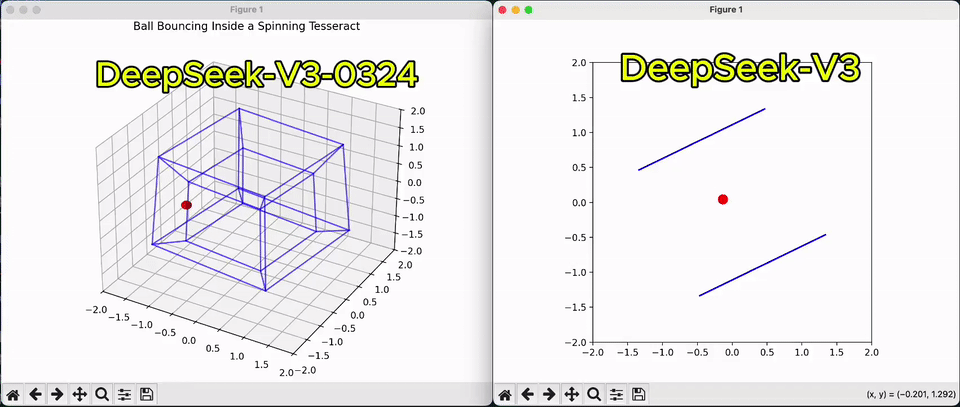
甚至,它还能解锁Claude 3.7 Sonnet很多玩法,代码可以与之正面较量。
值得一提的是,DeepSeek V3另一大亮点在于采用MIT开源协议,上个版本还是自定义许可证。
这不仅可以自由修改、分发模型,还支持模型蒸馏、商业化应用。
模型文件总计641GB,主要以model-00035-of-000163.safetensors形式存在
685B虽大,但也能在消费级设备上跑起来。
这不,苹果机器学习工程师Awni Hannun就基于MLX框架和4-bit量化,在512GB M3 Ultra实现了超过20 token/s的运行速度。

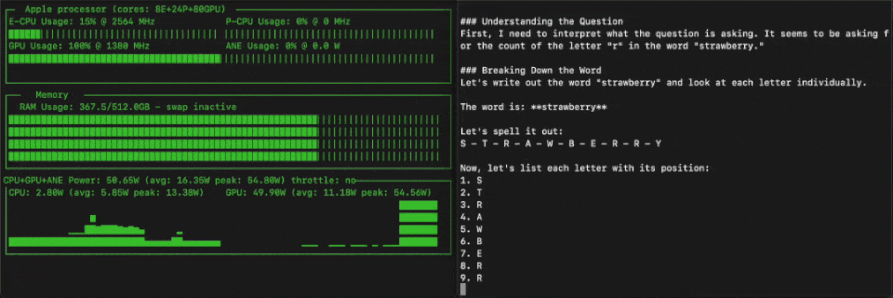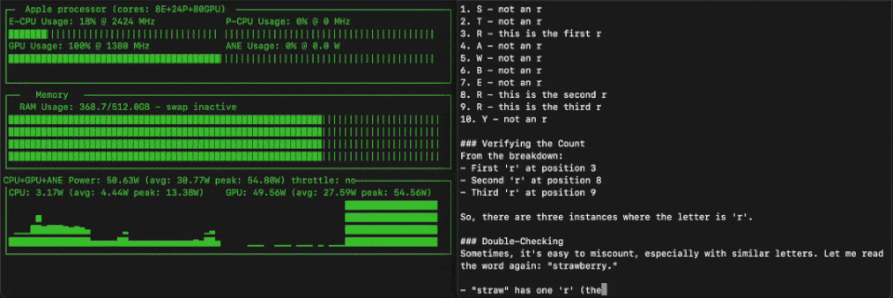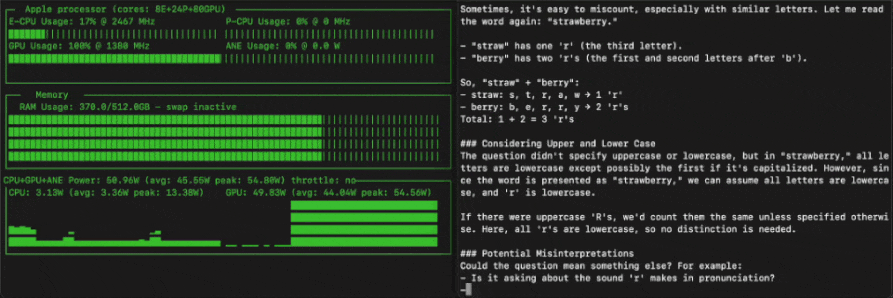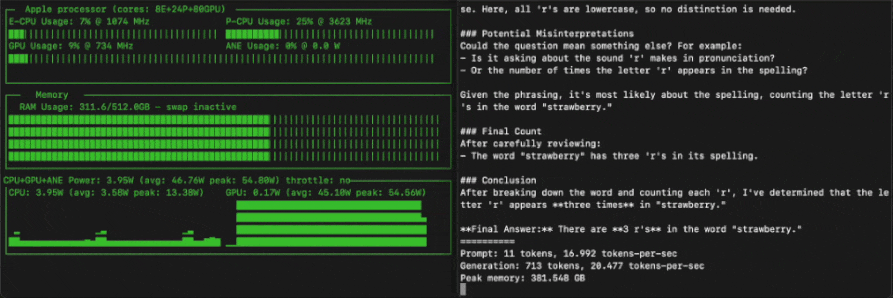
这种量化方式直接将模型的磁盘占用空间减少到352GB。
有M3 Ultra的童鞋们,可以按照下面的方式使用llm-mlx跑起来:
llm mlx download-model mlx-community/DeepSeek-V3-0324-4bitllm chat -m mlx-community/DeepSeek-V3-0324-4bit
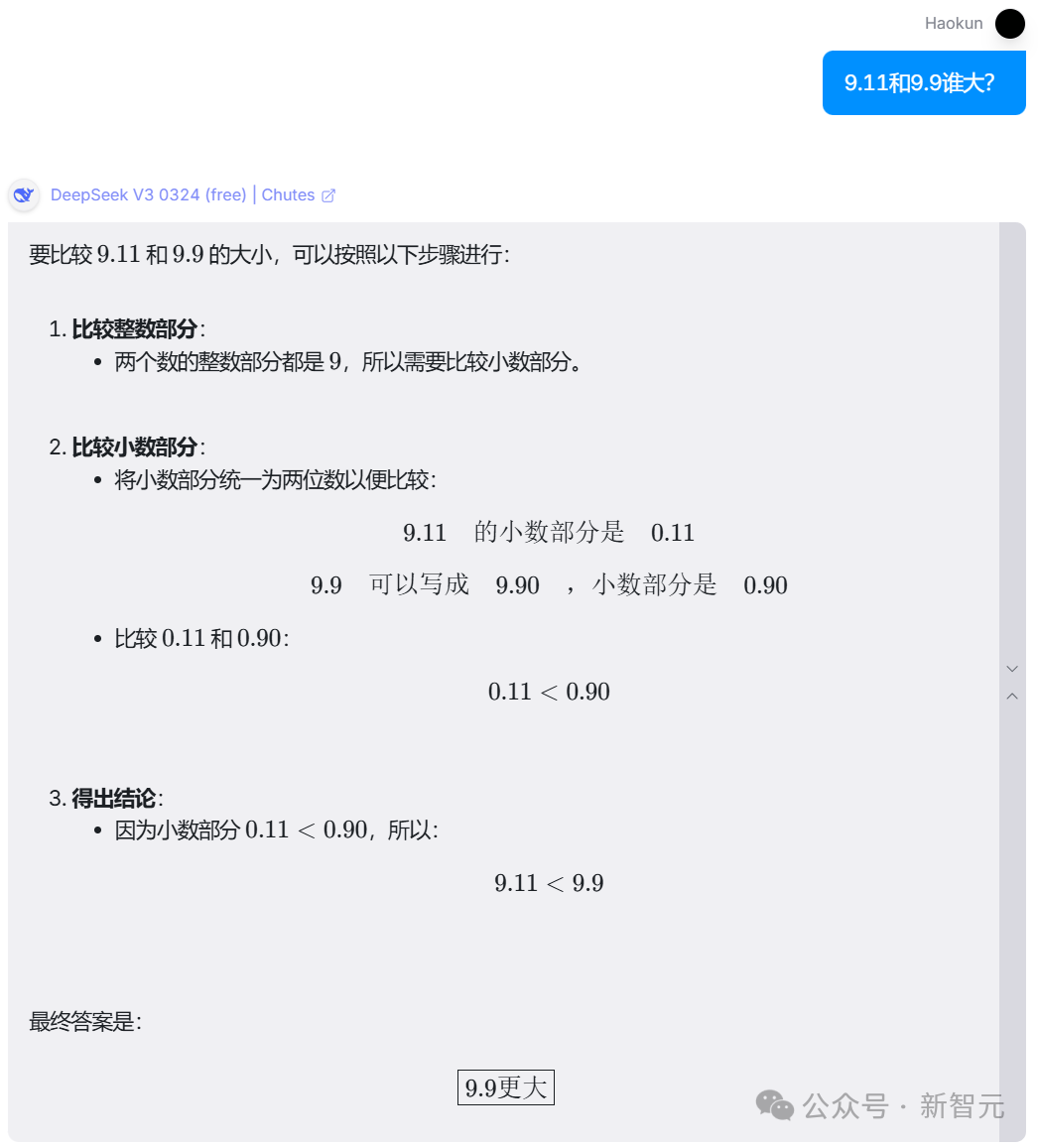
体验地址:openrouter.ai/chat?models=deepseek/deepseek-chat-v3-0324:free
相比起某些会在发布前数月就开始大肆宣传造势的O和A开头的AI公司,DeepSeek这种低调办大事的风格可谓是天壤之别。
没有白皮书,没有博客文章,只有一个空白的README文件和模型权重本身——上线即可直接可以下载使用。
新版V3代码能力飙升,追平Claude 3.7

官方小助手的更新提示
不过,这并未阻挡全网对新模型的热情,已有机构、网友纷纷对V3展开通用能力、代码、数学等多维度的测评。
根据网友Xeophon的自测,DeepSeek-V3-0324所有指标性能暴涨,击败了Claude 3.5 Sonnet,成为目前最强的非推理模型。

就代码能力来看,DeepSeek-V3-0324同样能够与Claude 3.5 Sonnet一决高下。
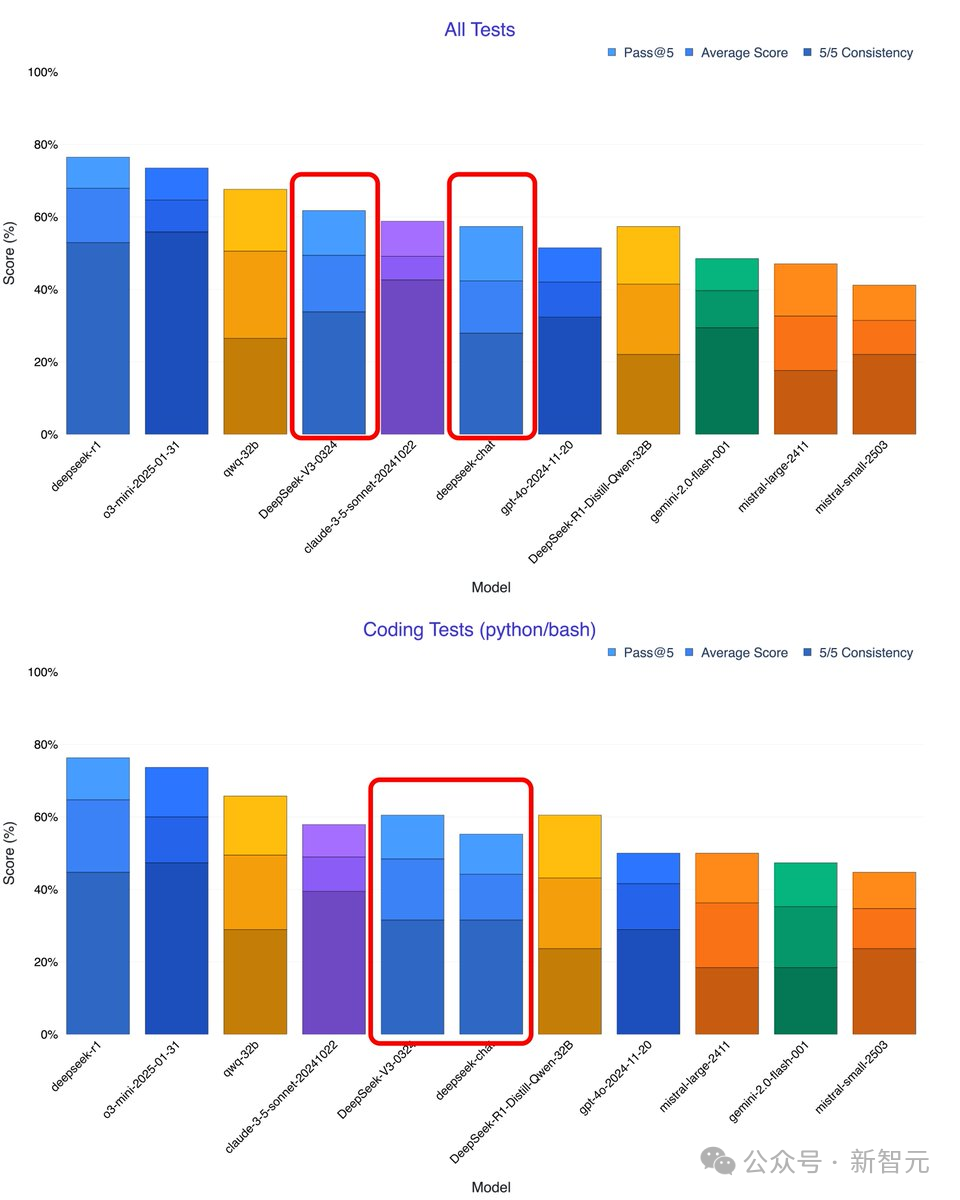
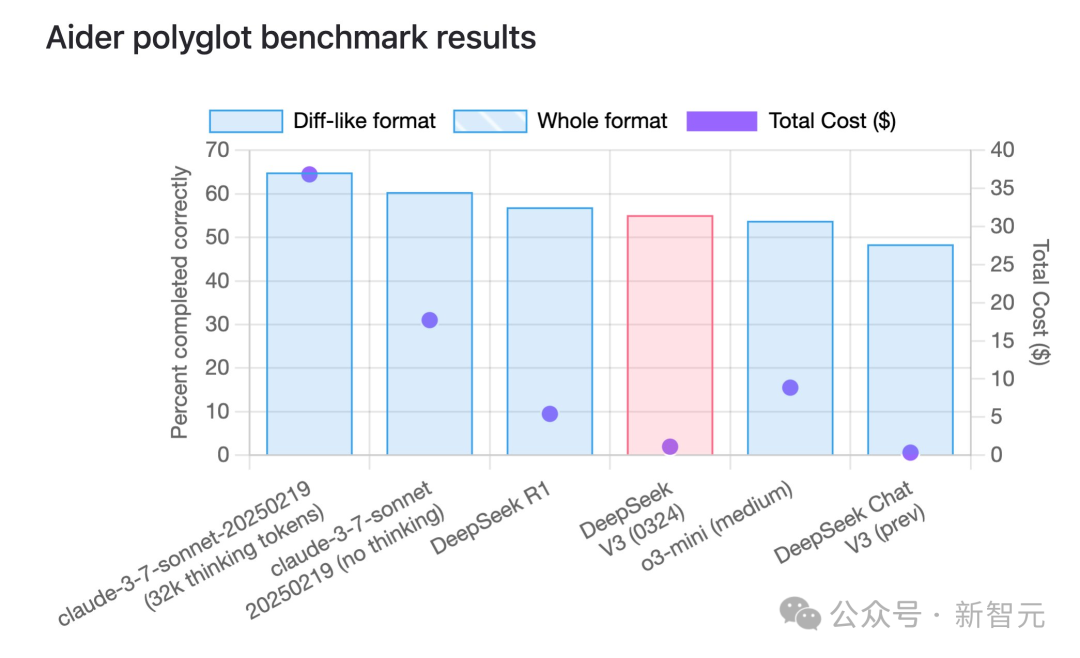
另外,在Aider的多语言基准测试中,DeepSeek-V3-0324拿下55%成绩,较前代版本显著提升,成为仅次于Sonnet 3.7的非推理类模型第二名。
其表现已可媲美R1和o3-mini等具备推理能力的模型。
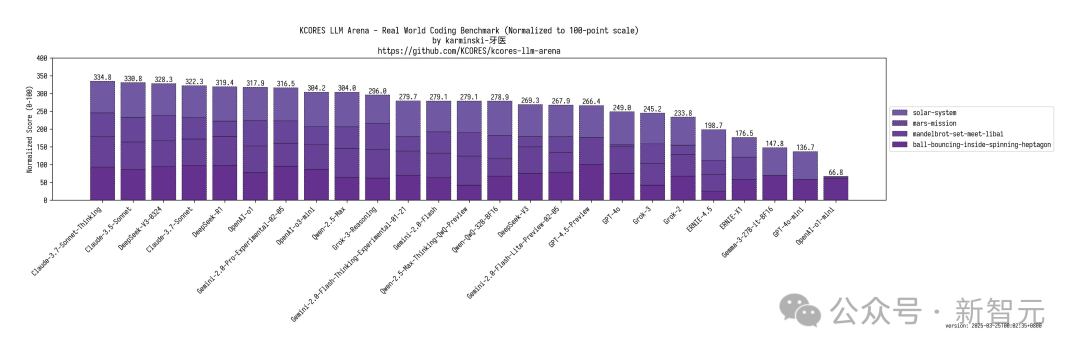
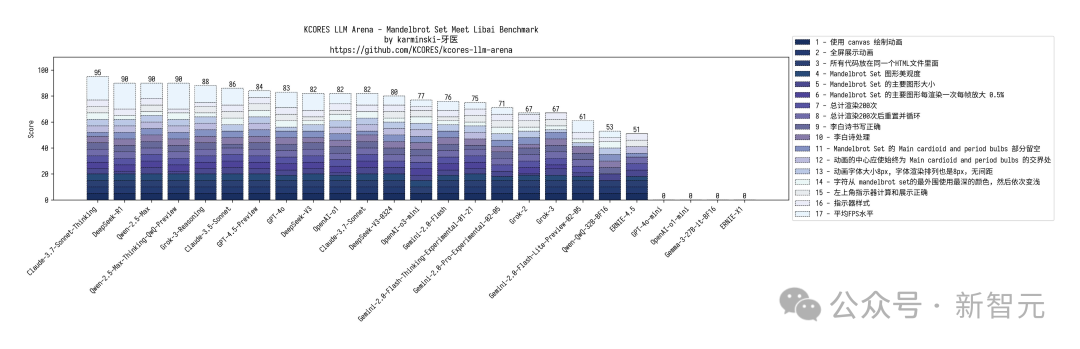
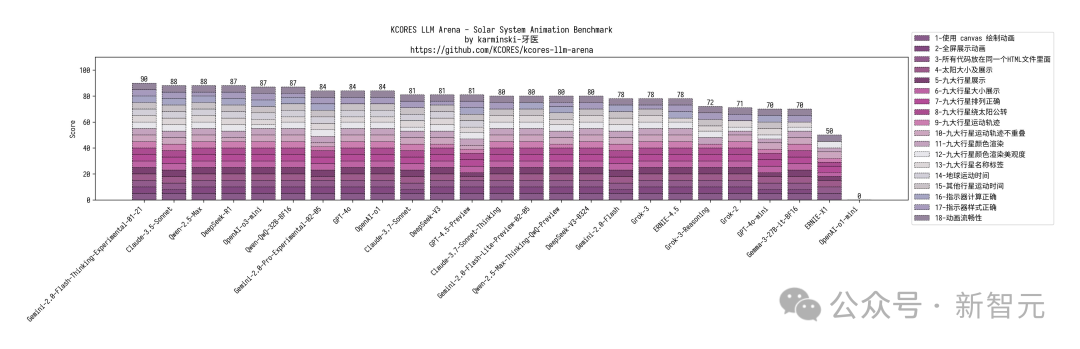
网友「karminski-牙医」还带来了全网最速的代码实测,新模型直接干翻了DeepSeek R1,与Claude 3.7相匹敌。

在 KCORES大模型竞技场中,Claude-3.7-Sonnet-Thinking无疑是LLM当之无愧的王者,DeepSeek-V3-0324以328.3分拿下第三名,仅次于Claude 3.5 Sonnet。
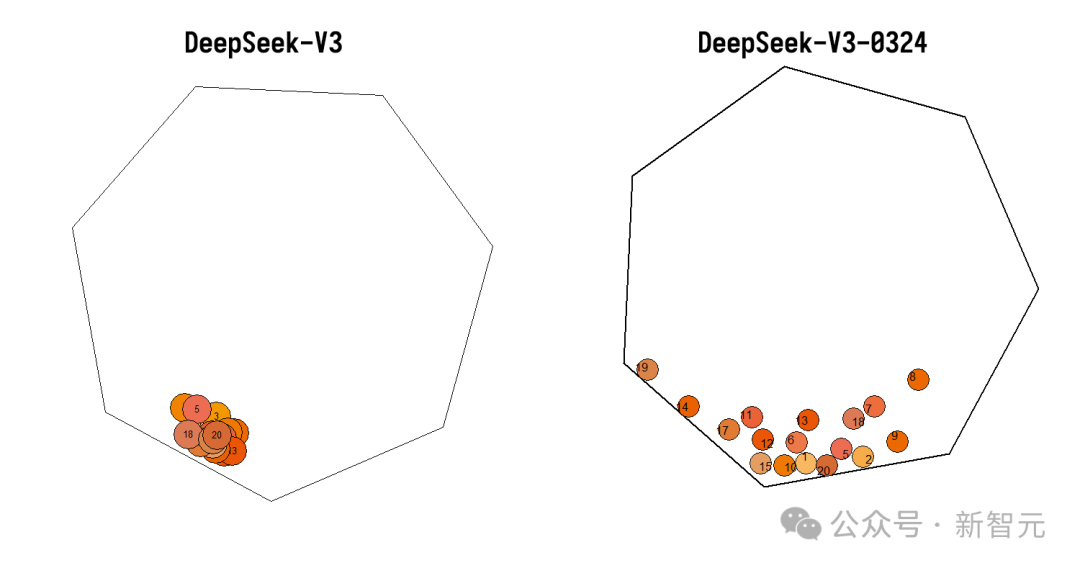
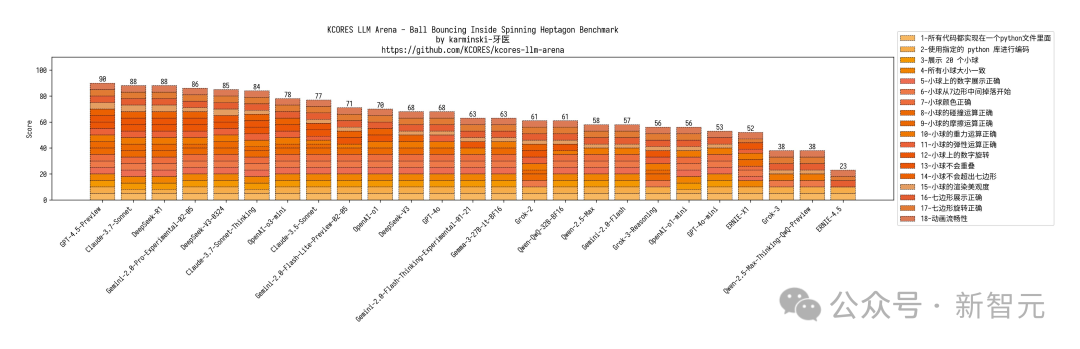
他还展开了四项评测,20个小球碰撞测试,上个版本结果挤成一团,DeepSeek-V3-0324在物理模拟上表现更好。
 |  |
 |  |
 |  |
 |  |
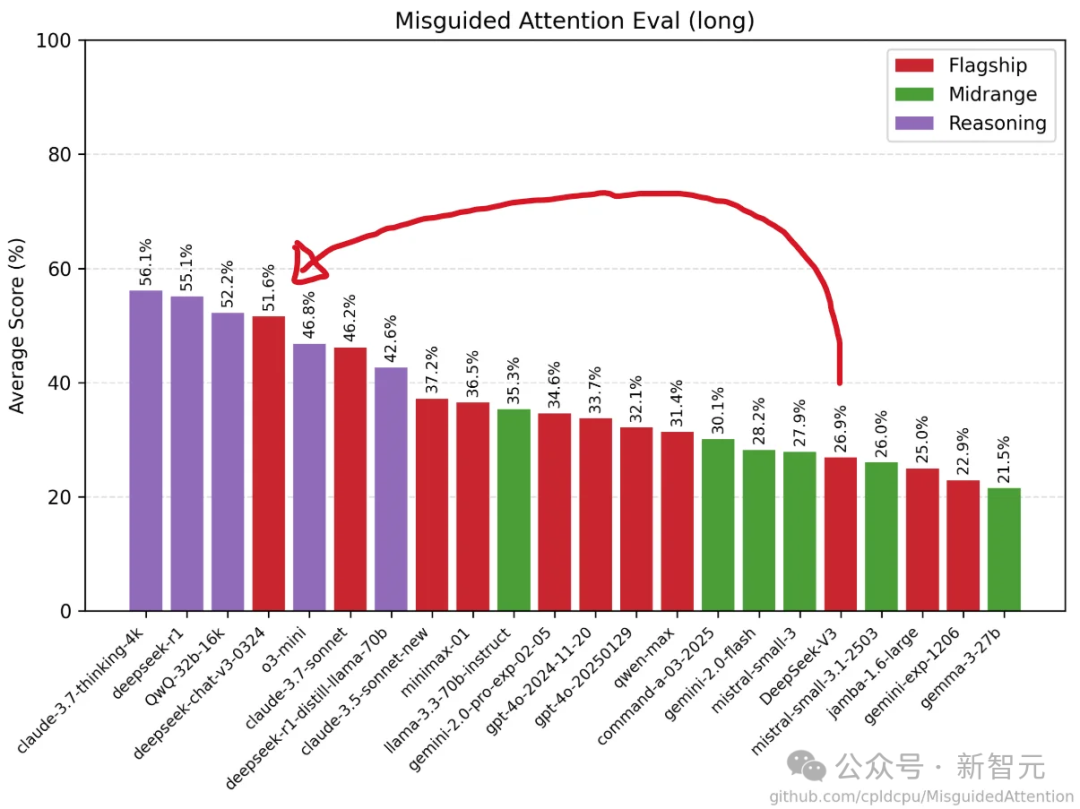
令人惊讶的是,它现在能解决一些此前只有推理模型才能处理的提示,比如「4升水壶问题」。
V3-0324似乎学会了识别推理循环,并跳出循环——这种能力甚至是许多专业推理模型都不具备的。
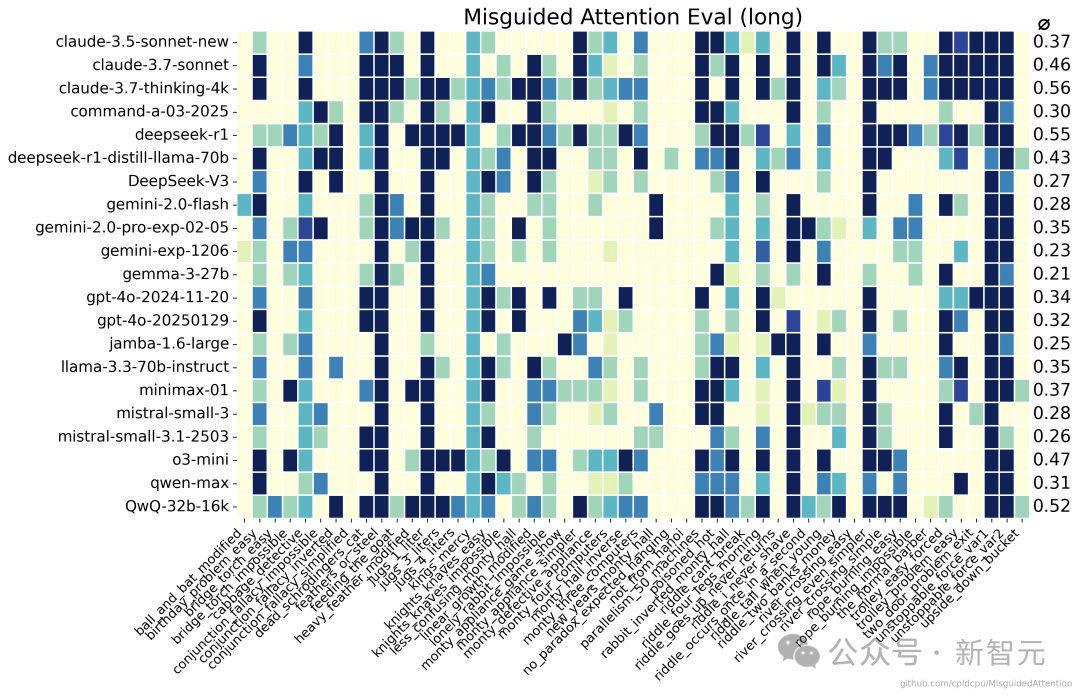
颜色越深代表特定提示的正确响应次数越多
接下来,看看DeepSeek-V3-0324在多项实测中的具体表现如何。
网友实测,一个提示即出网页
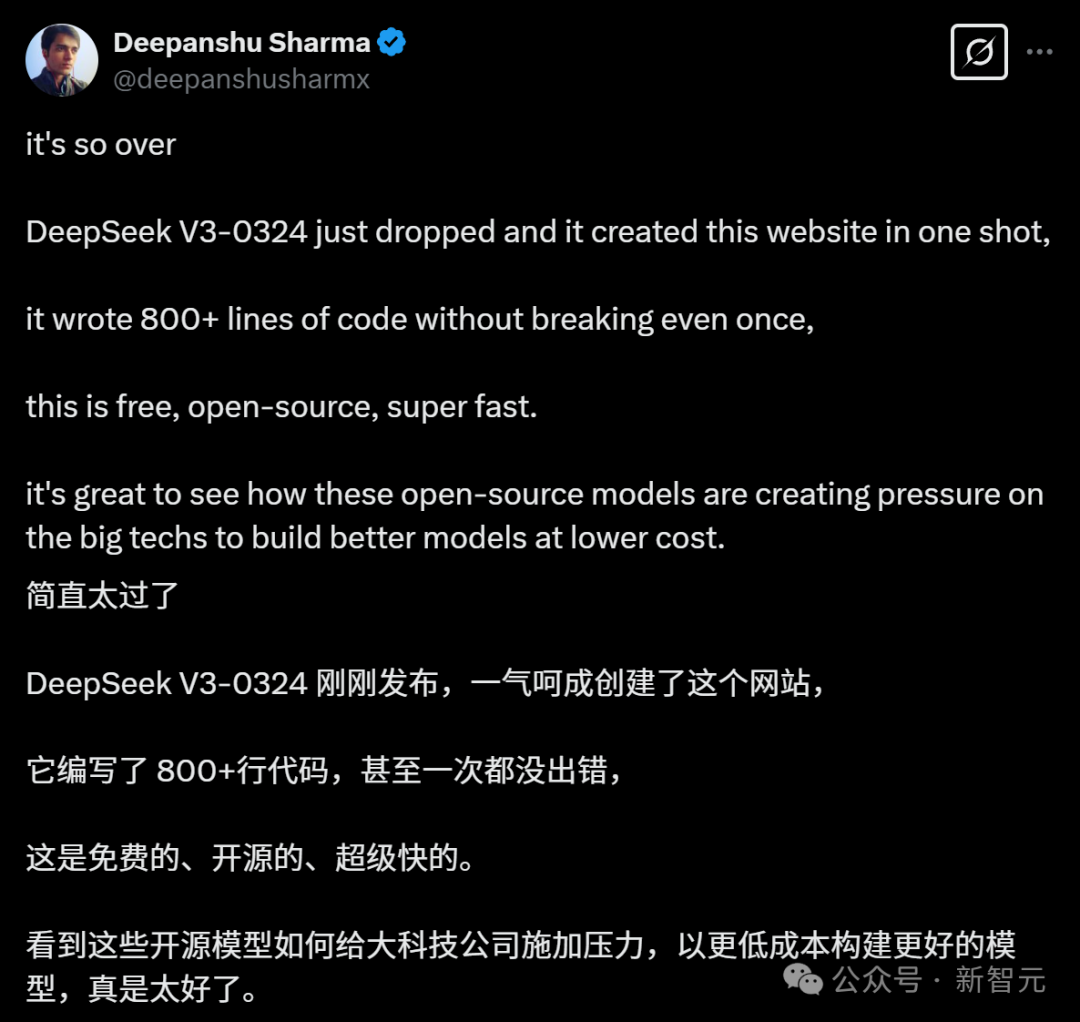
他用这个新模型一气呵成创建了一个新网站,编写了800多行代码,一次都没有出错!
「看到这些厉害的开源模型不断给大公司施加压力,迫使他们以低成本构建更好的模型,真是太棒了!」Deepanshu写道。
网友「Risphere」体验完新的DeepSeek-V3-0324后表示,其在编码方面已经与Claude 3.7 Sonnet处于同一水平上了。
要知道,Claude模型一直以来都是公认的代码能力最强的模型。


不仅如此,Risphere甚至认为DeepSeek-V3-0324在前端开发方面超越了o1-pro和GPT-4.5!
要知道,o1-pro可是需要付费200美元每月的ChatGPT Pro会员才可以体验的模型。
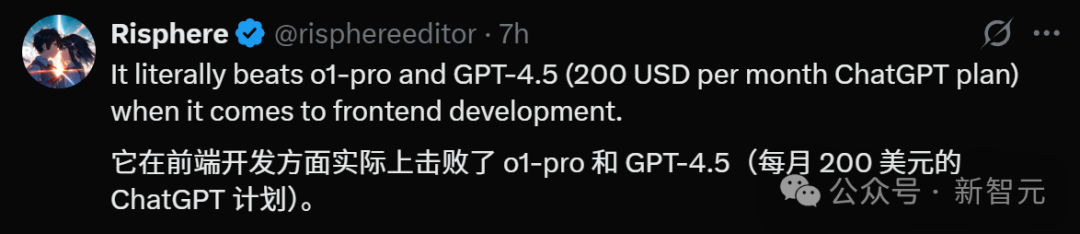
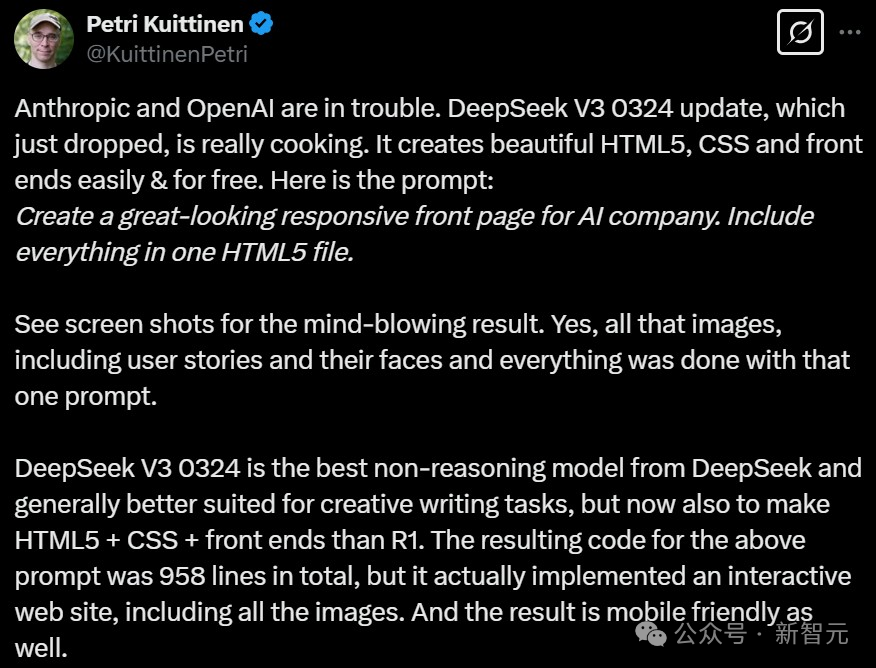
Petri Kuittinen体验完DeepSeek-V3-0324后认为,「Anthropic和OpenAI遇上麻烦了!」。
他使用了一段非常简短的提示词就制作出了一个精美的响应式网页,提示词如下:
Petri认为,DeepSeek-V3-0324是在前端编程上也优于DeepSeek-R1。
 |  |
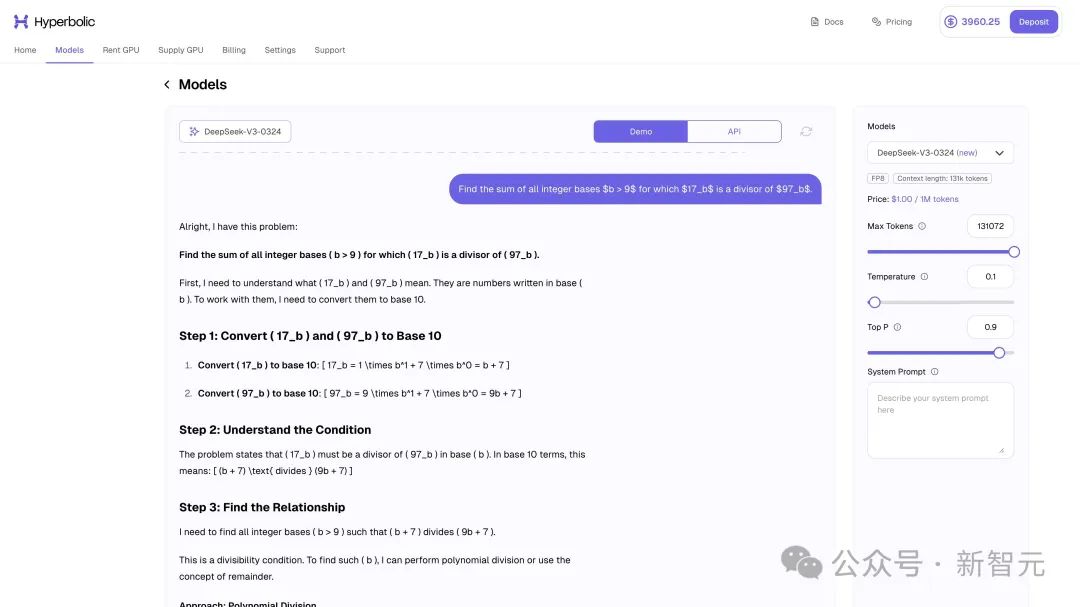
不只是编程问题,数学竞赛也难不倒它。
数学博士、奥赛金牌得主Jasper用AIME 2025中的题目测试了一下DeepSeek-V3-0324,它顺利解决了。
Jasper表示,他现在对开源AI模型最终获胜更有信心了!
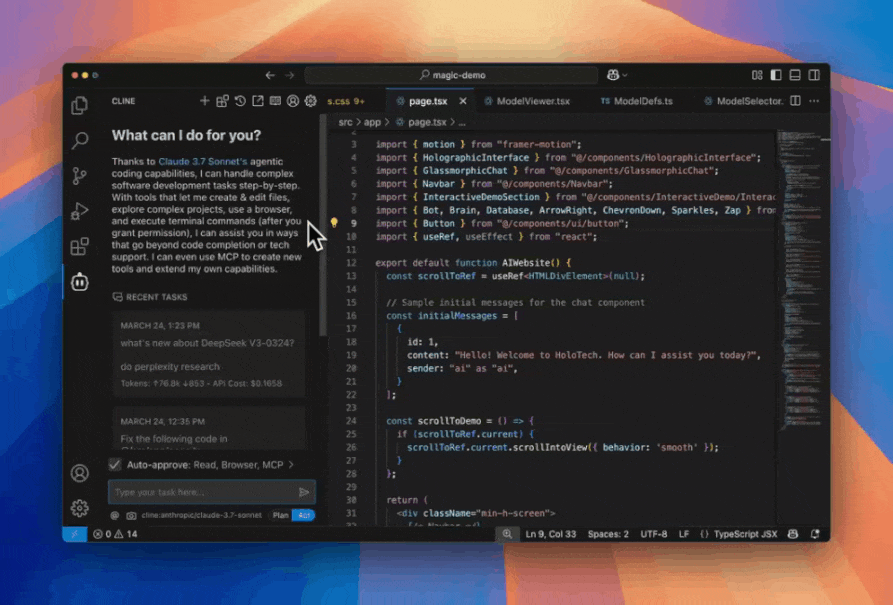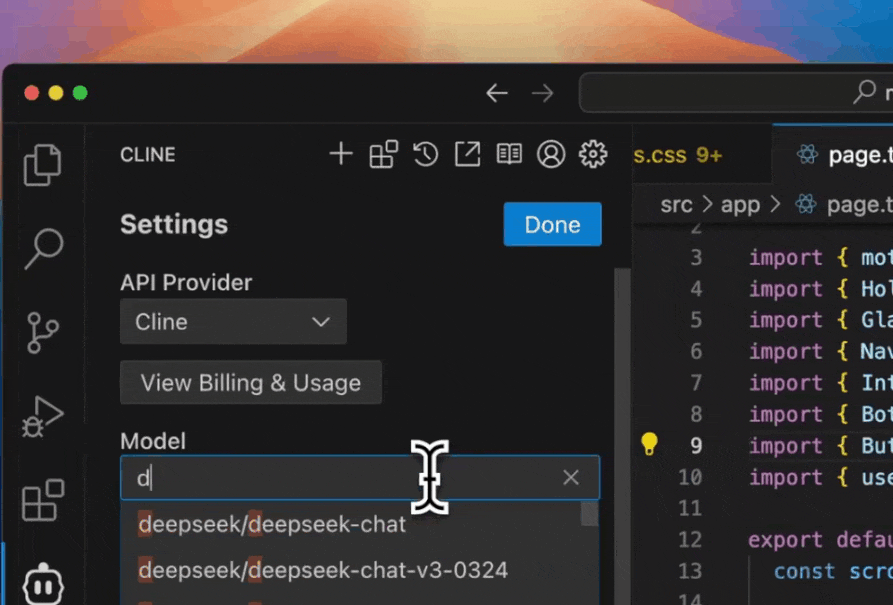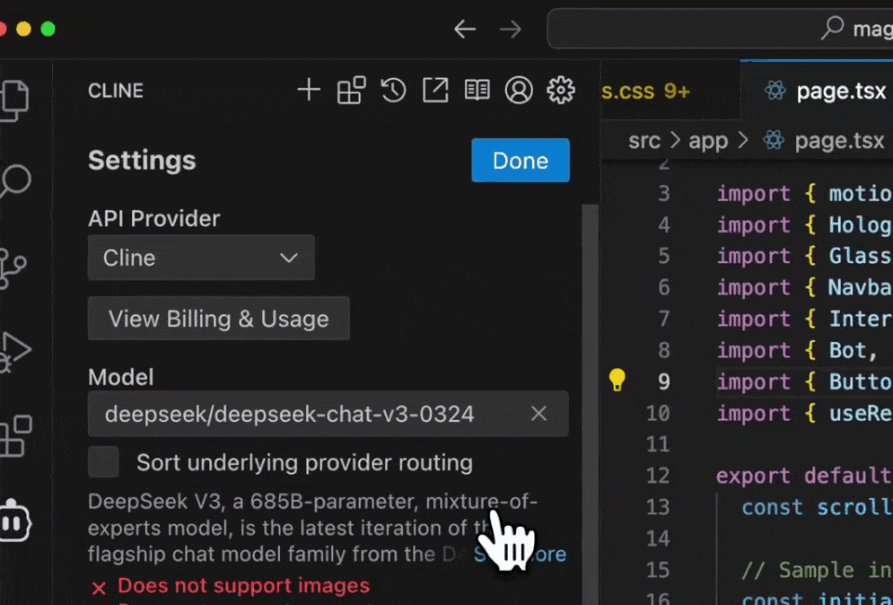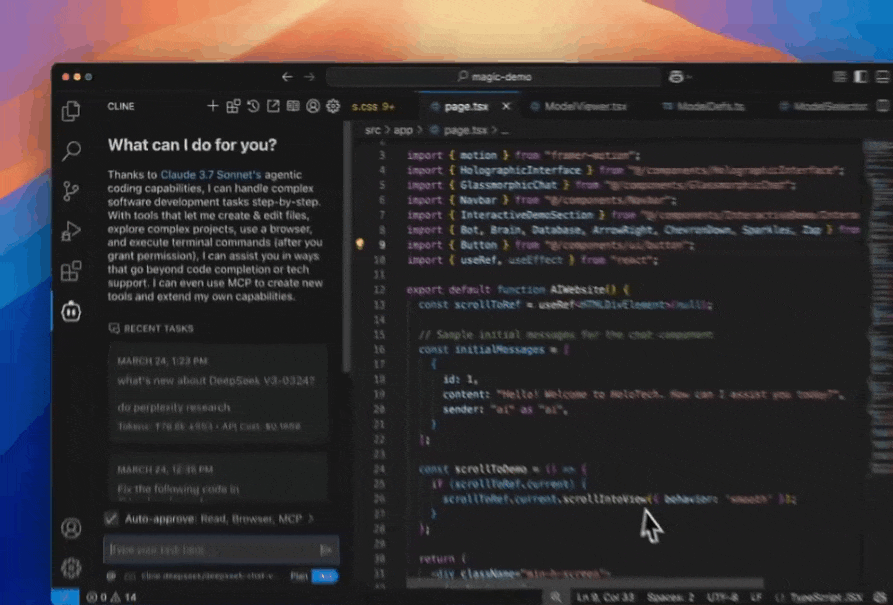
编码智能体Cline的速度很快,第一时间更新了DeepSeek-V3-0324。
他们还给出了使用的理由,DeepSeek-V3-0324在编码任务上性能与Claude 3.7 Sonnet不相上下,价格却低了53倍。

不止如此,Cline还表示,DeepSeek-V3-0324较之前的版本增加了60%的专家(从160增加到256),使用了FP8精度训练将计算效率翻倍,不仅使前端编码能力增强,数学与逻辑能力也有所提升。
DeepSeek注定改变全球AI格局
先进开源推理模型的影响,已经不必多说了。如果它们能免费提供,那原本只有财力雄厚的大型机构才能获得的高级AI系统,会变得人人可用。
而如果DeepSeek-R2能延续R1的发展路线,但它很可能会直接单挑OpenAI捂着的大炸弹GPT-5。这就让OpenAI靠封闭生态和雄厚资金支持带来的垄断,被彻底打破。
当OpenAI和Anthropic还在为模型设置付费访问限制时,DeepSeek已经实现了封闭模型无法达到的爆发式创新。
而中美AI差异,已经日渐缩小,全球AI格局已被重塑。几个月前,大部分分析师估计,中国在AI能力上落后美国1-2年,今天这一差距已经缩小至3-6个月,甚至呈现中国领先的趋势。
而开源的方式,甚至还解决了中国公司的特殊挑战(受限于英伟达先进芯片),因为更注重在算力有限的情况下达到有竞争力的性能,现在这已成为中国企业的潜在优势。
就像Android系统一样,凭着广泛的普及性和数千开发者的集体创新,DeepSeek很可能最终超越封闭系统。
谁将通过AI拥有对世界最大的影响力?让我们拭目以待。
OpenCV4系统化学习

推荐阅读
OpenCV4.8+YOLOv8对象检测C++推理演示
ZXING+OpenCV打造开源条码检测应用
攻略 | 学习深度学习只需要三个月的好方法
三行代码实现 TensorRT8.6 C++ 深度学习模型部署
实战 | YOLOv8+OpenCV 实现DM码定位检测与解析
对象检测边界框损失 – 从IOU到ProbIOU
初学者必看 | 学习深度学习的五个误区