AI工作负载正显著推动接口IP市场的创新。AI模型参数量呈指数级增长,大约每4至6个月翻一番,这与摩尔定律所描绘的硬件发展速度(周期长达18个月)形成了鲜明对比。此差距要求硬件创新来支持人工智能(AI)工作负载,并且需要更强的计算能力、更丰富的资源和更高带宽的互连技术。
更重要的是,硬件性能已经超越了标准掩膜尺寸的限制。由于计算单元和相关内存越来越多,CPU和GPU设计正在不断突破掩膜尺寸。AI加速器和GPU现在需要一种全新的超高效网络基础设施,突破单个芯片的性能限制,同时实现低延迟、高密度连接的芯片间通信,优化能效。
本文从技术角度深入探讨了横向、纵向扩展为何成为HPC和AI芯片开发商的关键需求,以及超以太网和UALink等新标准如何应对高带宽、低延迟连接和高效资源管理的挑战。
新标准的崛起
在AI工作负载需求的推动下,芯片到芯片架构的横向、纵向扩展至关重要。从单芯片过渡到Multi-Die系统,并融合HBM和UCIe等并行接口已成为必然趋势。这些解决方案支持同构和异构计算架构,借助PCIe和CXL的传统连接进一步扩展内存,并利用以太网实现更广泛的网络架构。
▲ 点击查看详细信息
为了满足AI扩展需求,两项新标准应运而生:
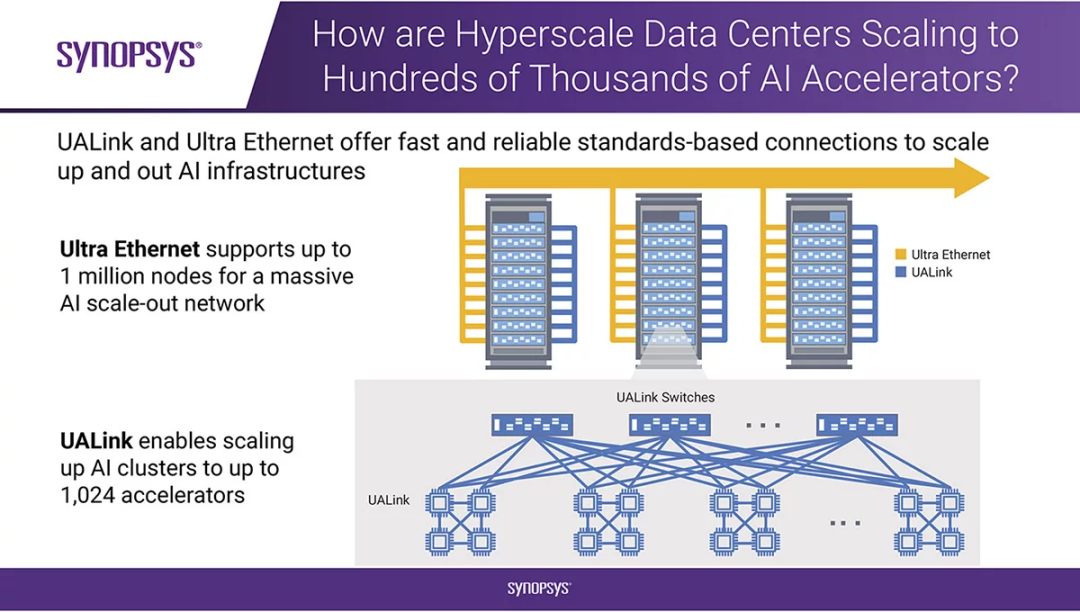
适用于横向扩展的超以太网
适用于纵向扩展的UALink
超以太网是一种开放、可互操作的高性能架构,专为AI而设计,得到了交换机、网络、半导体和系统供应等领域的知名企业以及超大规模用户的支持。另一方面,UALink则通过特定的内存共享功能,使加速器能够直接运行,得到了半导体行业重要参与者的广泛认可。
超以太网:横向扩展AI工作负载
随着AI和HPC流量的增长,使用RoCE或专有解决方案的传统网络逐渐显露出其局限性。这包括严格的按序数据包传送、基于流的低效负载平衡,以及数据包丢失时在RDMA操作中繁琐的重新传输。而这些对于AI操作来说成本非常高昂。超以太网联盟(UEC)技术通过提供更高效、可扩展且强大的网络解决方案来解决这些问题,能够针对性地满足AI和HPC工作负载的高性能需求。
超以太网的工作原理
▲ 点击查看详细信息
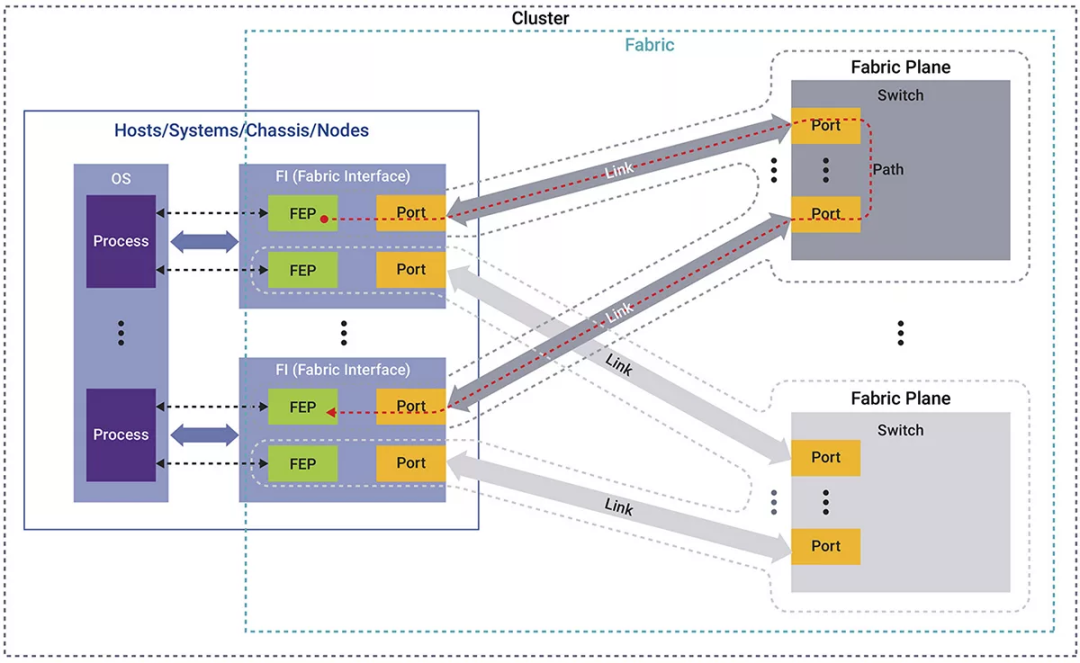
图1:超以太网集群图
超以太网系统由多个集群组成,每个集群都包含节点和基础设施。节点通过结构接口(网卡)连接到网络,该接口可以承载多个逻辑结构端点(FEP)。网络分为多个平面,每个平面包含多个通过交换机互连的FEP。
集群主要采用两种模式来处理不同的任务。
并行作业模式:系统运行任务直至完成,并允许多个节点同时进行通信。对于需要大量并行处理的高性能计算任务来说,这是理想的作业模式。
客户端/服务器模式:系统专为存储任务而设置。在这种情况下,服务器持续处理来自多个客户端的请求,并在特定的节点对之间进行通信,非常适合用于可靠且一致的数据访问和管理工作。
超以太网的关键技术特点
▲ 点击查看详细信息
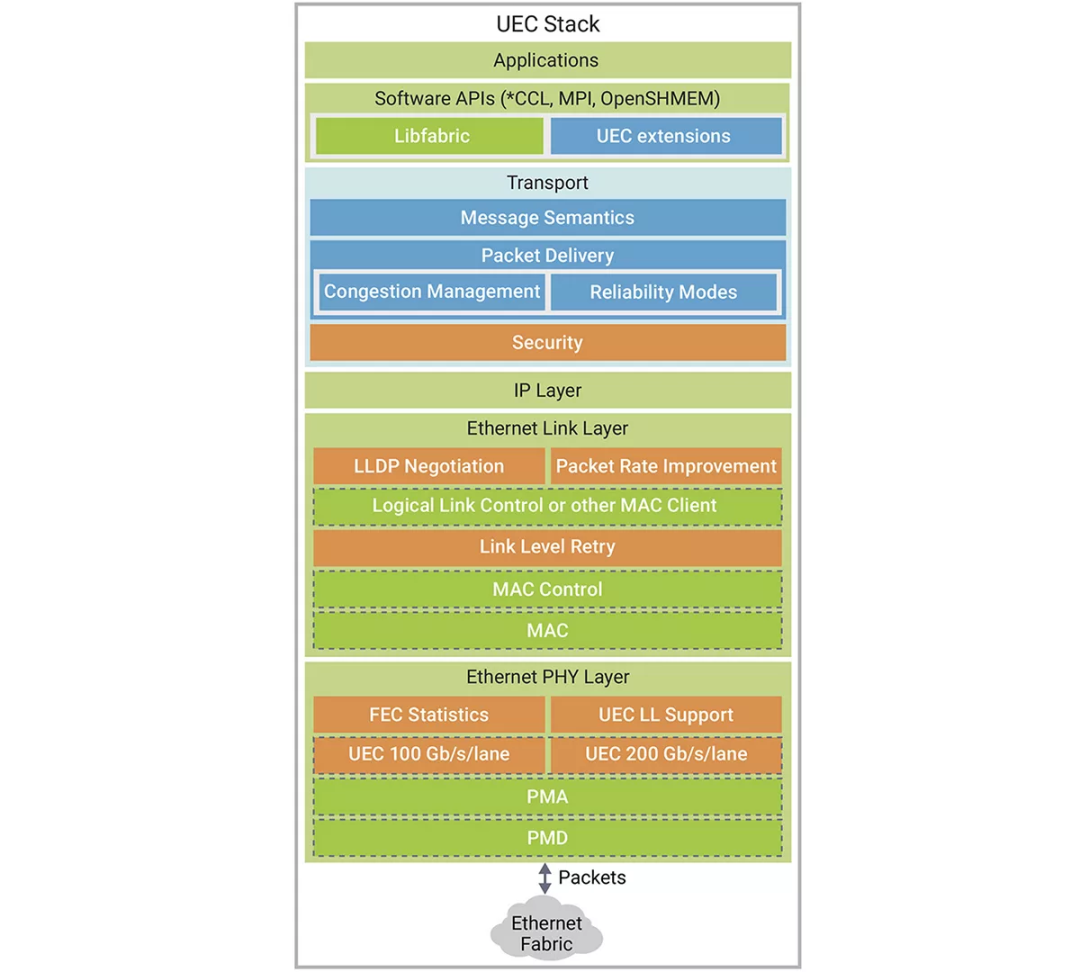
图2:超以太网使用专为AI和HPC应用而设计的下一代传输协议重新定义了以太网。(图片来源:超以太网联盟)
1. 物理层:与IEEE 802.3标准以太网兼容,具有基于FEC(前向纠错)码字的可选性能监控功能。UCR(不可纠正码字率)和MTBPE(平均数据包错误间隔时间)等指标有助于深入分析传输性能以及可靠性表现。
2. 链路层:引入LLR(链路层重传)协议,可实现无损传输,而无需依赖优先级流量控制(PFC)机制。这可确保更快的错误恢复,避免不必要的端到端重传,并减少尾部延迟。
3. 数据包速率改进(PRI):通过压缩以太网和IP报头提高数据包速率,解决由传统功能和冗余协议字段导致的效率低下问题。
4. 链路协商协议:通过协商功能扩展LLDP,以检测并启用LLR和PRI等受支持功能。
5. 传输层:旨在解决传统RDMA网络的局限性,支持选择性重传、无序传送、数据包喷射和高级拥塞控制机制。提供多种传输模式,包括可靠有序交付(ROD)、可靠无序交付(RUD)和不可靠无序交付(UUD)。
6. 拥塞控制:实现了incast管理、加速速率调整、基于遥测的控制和通过数据包喷射进行自适应路由等功能,以尽可能地减少尾部延迟并增强网络性能。
7. 安全:在传输层整合基于作业的安全性,利用IPSec和PSP功能进一步减少加密开销并支持硬件卸载。
UALink:纵向扩展AI工作负载
AI模型的规模越来越大,相关市场对算力和内存资源的需求显著增加。传统的互连技术并非专为AI工作负载网络设计,难以满足其需求。UALink作为一种可扩展结构,可在数十到数百个专用AI加速器之间建立基于标准的超高带宽连接网络。这一技术的出现标志着市场的重大进步,纵向扩展网络从临时配置转向更标准化的网络,支持更高基数的系统,并配备专用的UALink交换机。
UALink的工作原理
▲ 点击查看详细信息
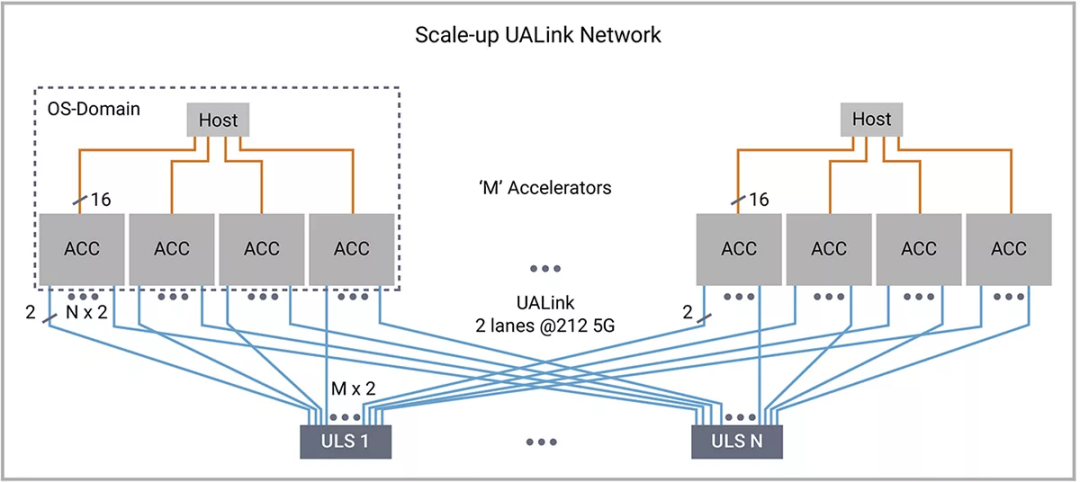
图3:UALink为纵向扩展网络和AI加速器交换机营造了开放的生态系统。摘自:MICRO-2024 HiPChips研讨会
UALink创建了一个高速、低延迟的网络,可以连接一个Pod内的多个加速器(例如GPU)。这让每个加速器能够直接访问其他加速器的内存,整个Pod可以像单个巨大的GPU一样运行。这使得每个GPU可以直接访问和修改同一扩展网络内其他任何GPU的内存。从软件角度来看,这组相互连接的GPU看起来就像一整个大型GPU。
UALink的工作原理超加速器链路(UALink)的关键技术特点
1. 高带宽:UALink每通道的速度高达200 Gbps,有助于在加速器之间高效传输数据。
2. 轻量级协议:该协议设计轻量,可减少开销并确保高效通信。
3. 效率:亚微秒级延迟提高了推理性能,并支持在不划分工作负载的情况下扩展到八个GPU以上。
4. 开放标准:UALink是一个开放的行业标准,可改善互操作性,减少供应商锁定。
5. 内存共享:特定的内存共享功能让加速器可以有效地访问共享内存资源,支持数百个GPU之间的加载、存储和原子操作,减少端到端延迟并降低功耗。
6. 同步功能:UALink包含同步功能,有助于确保多个加速器之间的一致性,促进高效运行。
7. 与UEC相辅相成:可以与超以太网联盟成员的前沿技术良好协作,实现更广泛的可扩展性。
利用业界首发的超以太网和UALink IP解决方案实现大规模AI集群
新思科技抢先推出业内首款UALink和超以太网IP解决方案,致力于连接海量AI加速器集群。

▲ 点击查看详细信息
新思科技超以太网IP解决方案的速度高达1.6Tb/s,可支持多达一百万个端点。此外,新思科技UALink IP每通道的速度高达200Gb/s,可连接一千多个加速器。这些解决方案针对AI的横向、纵向扩展进行了优化,提供了AI通信所必需的高带宽和轻量级协议。
结语
随着AI领域的不断扩大,采用标准化接口对于推动创新、降低复杂性和提高整体系统性能至关重要。AI基础结构的未来在于这些能够促进行业增长、提高效率的协作性开放标准解决方案。新思科技正处于AI和HPC设计创新的前沿,提供广泛的高速接口IP组合。新思科技为PCIe 7.0、1.6T以太网、CXL、HBM、UCIe以及最新的超以太网和UALink提供完整且安全的IP解决方案,从而推动AI和HPC在性能、可扩展性、效率和互操作性等方面达到新的高度,帮助客户实现一次性流片成功。
如需了解更多信息,请扫描下方二维码联系我们