


----追光逐电 光引未来----
随着Nvidia 的 GPU 技术大会 2025 在公司联合创始人兼首席执行官黄仁勋的主题演讲中如火如荼地拉开帷幕,Nvidia 公布了其采用硅光子学和在其 Quantum InfiniBand 和 Spectrum 以太网交换机系列中部署共封装光学器件(CPO) 的计划。
这不仅是一个令人兴奋的发展,而且事实证明,它将大大降低数据中心规模AI 系统中网络的功率要求。
网络中光学器件消耗的功率巨大,资本支出也是如此。之前一直有传言说数据中心规模集群的大部分成本在于链路两端的光收发器和它们之间的光缆。一些将交换机连接到网络接口卡的部件占网络成本的75% 到 80%,而交换机和 NIC 则占另外的 20% 到25%。听起来很疯狂。

上图基于使用服务器节点的数据中心,每个服务器节点中每四个GPU 配备两个 CPU(如 GB200 NVL72 机架式 MGX 系统设计),数据中心中有100,000 台服务器,因此有400,000 个 GPU。(如果您使用 HGX 设计,它不会完全连接机架内的 GPU 内存,而只会连接服务器节点内的GPU,那么每四个GPU 就会有一个CPU,并且只需要50,000 台服务器即可容纳400,000 个 GPU,但它占用的空间只有一半,光收发器也略少。但它占用的空间是原来的两倍。)
Nvidia选择的方案将有240 万个光收发器,这些可插拔模块插入每个服务器端口和每个交换机端口,将电信号转换为可以通过光纤管道传输的光信号。这240 万个收发器使用40 兆瓦的功率,而这些可插拔模块上的激光器占其中的24 兆瓦。
在“传统”超大规模和云数据中心中,它们采用Clos 拓扑而不是像AI 或 HPC 超级计算机那样采用全胖树拓扑,在收发器上消耗大约 2.3 兆瓦的功率,如果将数字倒过来,则略低于 140,000 个这样的可插拔模块。收发器数量如此之少的原因很简单:一台具有一两个 CPU 的服务器执行 Web 基础设施甚至搜索引擎抓取时只有一个端口,而 GPU 服务器每个 GPU 至少需要一个端口。AI超级计算机中计算引擎的绝对数量推动了光学收发器的使用。
它为业界提供了一个摆脱它们的完美借口,Nvidia正在其下一代Quantum-X InfiniBand 和Spectrum-X 交换机上实现这一目标,并且可能最终会在其Connect-X SmartNIC 和BlueField DPU 上实现这一目标,正如我们上面指出的那样,GPU和 CPU 上的 NVLink 端口以及 NVSwitch 内存原子交换机上
Nvidia 采用了两种不同的共封装光学器件方法,这些方法是与众多合作伙伴共同开发的。硅光子引擎由Nvidia 自己创建(Mellanox在制造可插拔光学器件方面拥有丰富的专业知识),并为这些交换机ASIC 创建了一种新的微环调制器(MRM) 设计,以集成其光学器件。(关于MRM我们在1月22号的文章中有介绍过)
800 Gb/秒端口中 200 Gb/秒信号通道的迁移可能是推动力。仅仅将信号从交换机ASIC 传输到面板上的端口就需要大量的信号重定时器(每个端口可能多达两个)。

未来带有 CPO的Quantum-X InfiniBand ASIC 有一个单片交换机ASIC 芯片,带有六个不同的CPO 模块,每个模块都有三个连接器,总共看起来像18 个端口,运行速度为800 Gb/秒,但实际上有36 个端口(每个插头似乎有两个端口)。
显然,这个InfiniBand 较小的 CPO 模块设计为低成本且可高产量制造。这是第一步,它不会导致具有高基数的交换机,因此需要大量的CPO 模块通过服务器上的NIC 互连一定数量的GPU 端口。
在这两种设计中,SerDes的运行速度均为每通道224 Gb/秒,四个通道组成一个端口,Quantum-X ASIC 上的SerDes 总共有 72 个通道,而 Spectrum-X 芯片集合上的 SerDes 有144 个通道。
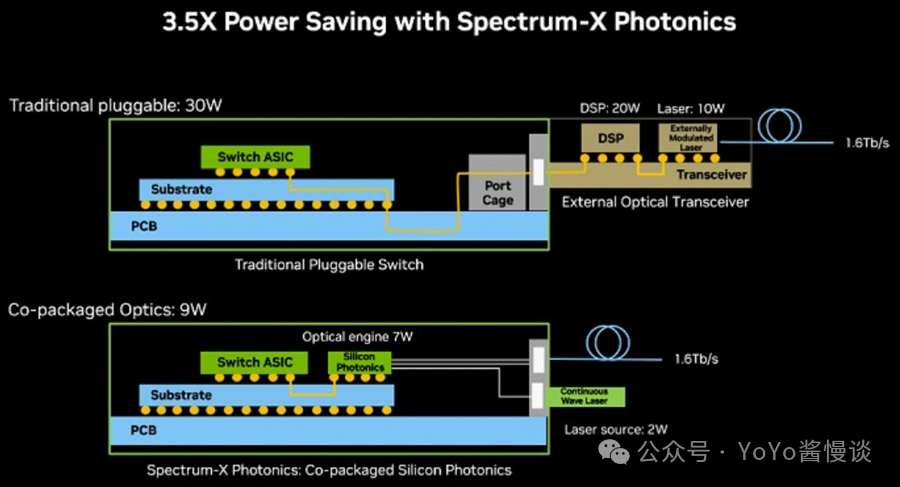
如上图所示,光收发器上的数字信号处理器消耗20 W,为收发器提供光源的外部调制激光器的功率为10 W。因此,240万个收发器共有30 W功率,用于交叉连接100,000 台服务器和400,000 个 GPU。
使用 CPO,交换机盒中有一个连续波激光源,每个端口消耗 2 瓦功率,光学引擎与 Spectrum 交换机 ASIC 使用的相同基板集成,消耗7 瓦功率。因此,现在每个端口的功率降至9 瓦,跨越 240万个链路,功率降至21.6 兆瓦。根据计算,链路的功率减少了3.3 倍。
因此使用 CPO 不仅降低了功率,而且由于信号组件之间的转换更少,整体端到端配置中的噪声更少。
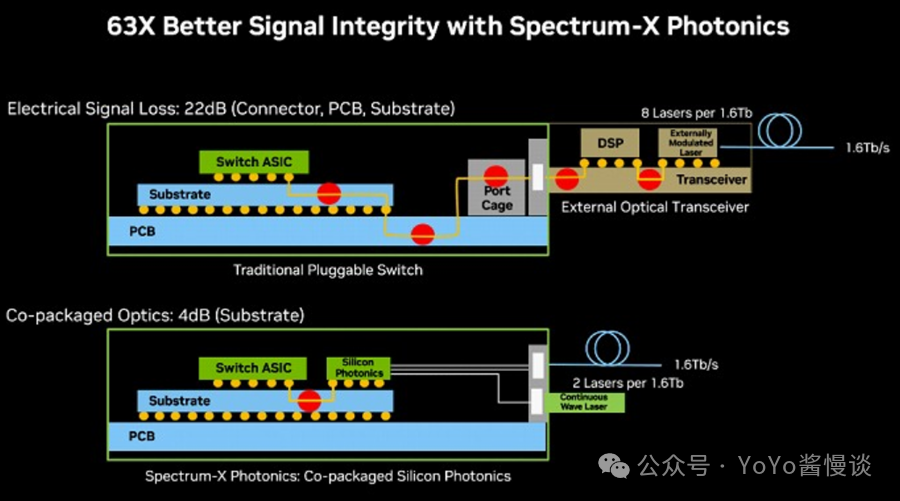
每次从一个组件跳转到另一个组件时,都会产生信号噪声,而将可插拔光学器件连接到交换机后,收发器和交换机PCB、基板和端口笼之间会有五次转换,总共会产生 22 dB的信号损失。使用 CPO,基板中有一个转换,用于将交换机 ASIC 连接到硅光子模块,信号损失仅为4 分贝。信号噪声降低了5.5 倍。
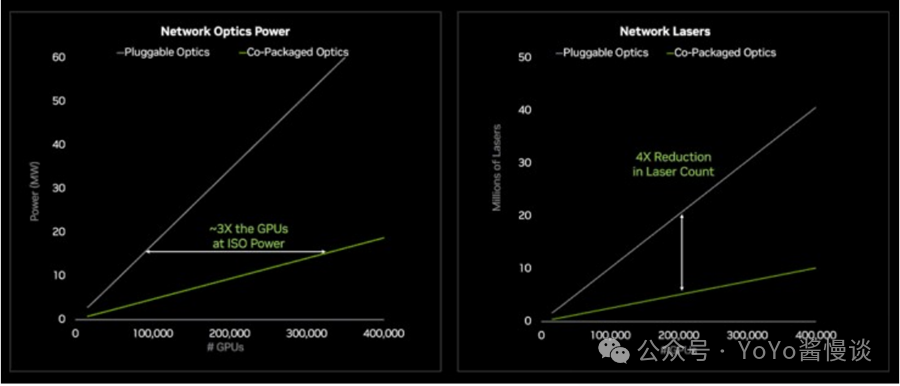
上图显示,在相同的光学功率范围内,GPU数量可以增加 3倍,但正如上图所看到的,实际数量是3.3 倍。值得注意的是,连接任意数量的GPU 所需的激光器数量也将减少4 倍以上。当然,诀窍是将激光源置于Quantum-X 和Spectrum-X 交换机内部,以便在发生故障时轻松在现场更换,或者足够可靠,不用担心发生故障。因此,带有CPO 的Quantum-X 和Spectrum-X 交换机将采用液体冷却,这样可以让它们在更冷的温度下运行,并且不会让激光器变得异常。

目前,Nvidia计划推出三种不同的交换机。
第一个是Quantum 3450-LD,它将在盒子内部配备四个Quantum-X CPO 插槽,以无阻塞方式完全连接,以800 Gb/秒的速度提供144 个端口,这些端口的总有效带宽为115 Tb/秒。这款Quantum-X 交换机将于2025 年下半年上市。
两款采用 CPO的Spectrum-X 交换机需要更长时间才能投入使用,预计要到2026 年下半年才能投入使用。
Nvidia 的第一款采用CPO 的以太网交换机是Spectrum SN6810,它将配备单个Spectrum-X CPO 设备,为 128个以 800 Gb/秒运行的端口提供102.4 Tb/秒的总带宽。(封装上显然有一些额外的CPO 单元,以提高封装产量。)Spectrum SN6800 交换机非常糟糕,有512 个以 800 Gb/秒运行的端口,盒子内的四个ASIC 总共提供409.6 Tb/秒的有效总带宽。
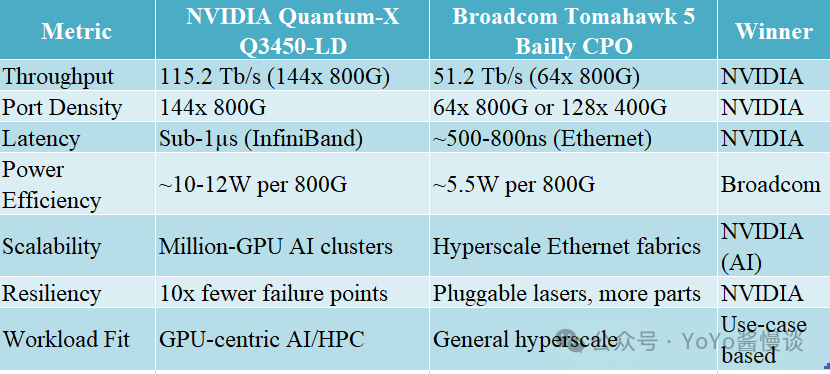
最后,我们把Nvidia Quantum-X与之前大火的BroadcomTomahawk5做了一下比较。如下:
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


